応用情報 データベース ・バックアップ (ER図、DFD、正規化、トランザクション管理と排他制御)

1.RDB(リレーショナルデータベース)
制約
📌非null制約
nullを認めない制約
なにかしらの値の入力が必要となる
📌主キー制約
主キーを設定した項目に、自動で制約される
主キー
テーブル内で1種類もしくは1組だけで、全てのカラム(属性)の値が決まるもの
・サロゲートキー
主キーのためだけに用意した項目
複合キー
複数項目で構成された主キーのこと
候補キー
主キーの候補のこと
その中から一つだけを主キーとする
・オルタネートキー
候補キーのうち、主キーには選ばれなかったもの
📌一意性制約
値の重複をしないような制約
👍テーブル内で複数の項目に、制約をかけられる
レプリケーション(複製という意味)
データベースに加えた変更を、他の別のネットワーク上の複製データベースに自動的に反映
↓
信頼性・耐障害性を高める
📌参照制約
全く関係ない値が入力されないようにする制約
(例)都道府県の欄に、都道府県以外は入力できないようにする
・外部キー
FOREIGN KEY列リスト
子テーブルにある列(カラム)を指定
他のテーブル(親テーブル)にある列を参照
ここに格納されるデータは、親テーブルの
該当列に存在するデータと必ず一致する
REFERENCES 親テーブル(列リスト)
参照する親テーブルとそのテーブル内の列を指定
つまり、子テーブルの FOREIGN KEY に指定された列に入力される値は、必ずこの親テーブルに存在する値になる
その他
NAS(network attached stroge)
コンピュータネットワークに直接接続して、
使用するファイルサーバ
コントローラーとハードディスクから構成される
👍各種OSや複数のサーバでのデータ共有が容易
B+木インデックス
木の深さが一定・葉のみが値を持つインデックス
根から節をたどっていくことで、目的のデータを探す
👍すべてのキー値が同じ深さなので、データ量が増加してもパフォーマンスが下がりにくい
👍一致検索・「BETWEEN」などの範囲検索を効率よくできる
✖ 欠損値・否定を含む検索条件では、効果なし
DBMS(データベース管理システム)
コンピューター上のデータベースの整理やデータの検索、更新、共有などを行うソフトウェア
・ディスクに対する入出力効率向上のため
トランザクションの更新を、メモリ上のバッファ・ログファイルに記憶
↓
一定の間隔ごとにまとめてディスクと同期
チェックポイント
補助記憶装置と同期をとるタイミング
✅チェックポイントまでのトランザクションは更新済みなので、復旧は不要
✅そもそも書き込みがされていない場合、バックアップを復旧させることは当たり前だができない
DBMS 例題

ロールフォワード:T2,T5
ロールバック :T6
書き込み(write)されていない場合は
ロールフォワード・ロールバックできない
↓
つまり書き込んでない場合は、読み込み中に障害が発生すると、データが復旧できない
メタデータ
データの定義情報が記載されているデータ
ストアドプロシージャ
・データベースに対する
一連の処理をまとめた手続きにして、
データベース管理システムに保存したもの
・SQL文のCALL文で実行される
(CALLは、呼び出すという意味)
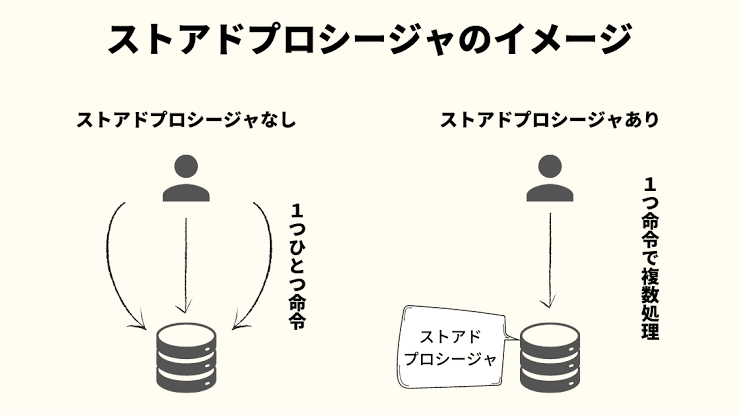
👍クライアントからサーバに対し1回の要求で
複数のクエリをデータベースに発行できる
※あくまで、要求があったら実行される
自動的に実行されるわけではないので注意
※クライアントから送信されるクエリは減るが、
全体として、クエリやバッファの数自体が減っているわけではない。
あくまで、一連のまとまりになってるだけ
👍よく使われる一連の処理を定型化できる
👍2者間の通信量を少なくして
クライアント・サーバ間のネットワーク負荷を
軽減できる
データウェアハウス
大量のデータを一元的に蓄積し、意思決定支援やデータ分析のために使用されるシステムやデータベースのこと
主に企業や組織がビジネスインテリジェンス(BI)やデータ分析を行う際に利用する
データウェアハウスの特徴
1. 統合
• さまざまなソースからのデータ(例:販売、マーケティング、財務、ERPシステムなど)を一元的に集約して保存
これにより、異なるシステムで管理されていたデータを統一的に分析できる
2. 時系列
• 過去のデータも蓄積されているため、時間の経過に伴うデータの変化を追跡できる。
3. 非揮発性
• データウェアハウスに格納されたデータは、一度保存されると基本的に変更されない
データ分析のためのデータの正確性と一貫性を維持するため
4. 意思決定支援
• 主に意思決定支援システム(DSS)やビジネスインテリジェンス(BI)ツールと連携して、経営層やアナリストが企業の業績やトレンドを把握し、戦略的な決定を行うのに役立てられる
OLAP(オンライン分析処理)
•データウェアハウスが、複雑なクエリや集計を高速で実行し、データの多次元的な分析を行うために、連携するシステム
ETLプロセス
• E=Extract(抽出): さまざまなソースシステムからデータを抽出する。
• T=Transform(変換): 抽出されたデータを分析に適した形式に整形、加工する。
• L=Load(ロード): 加工されたデータをデータウェアハウスに格納する。
データマート
• 特定の部門や業務に特化したデータウェアハウス
効率的に部門ごとの分析が可能に
データの整理方法
・データクレンジング (直訳:データを落とす)
データウェアハウスの元データを整理するために
業務システムごとに異なるデータ属性・コード体系を統一する処理
※データウェアハウスでは、データがバラバラで、
データ分析とかには、とても使えない
・ダイス
多次元データベースの中から縦軸と横軸を指定して
2次元の表にする操作のこと
3次元であるサイコロを振ると見えている面が変わるように、縦横の項目を変えて多次元データのまったく違う面を表にする機能のこと
◯ドリルダウン
詳細に展開する操作のこと
(例) 四半期集計データから月集計データに移ること
◯ロールアップ(ドリルアップ)
ドリルダウンの逆
集計レベルを上げる操作のこと
(例) 月集計データから四半期集計データに移ること
データベースの管理
・データ管理者
データベースの論理設計をする
・データベース管理者
データベースの物理設計をする
・開発者
データの管理規定を明文化する
・オペレータ
データベースに、業務データの登録と削除をする
データベースの設計(UMLとは違う)
E-R図
実体(entity)と、実体間の関連(relationship)で、データの構造を多重度で表したもの

DFD(データフローダイアグラム)
⬜︎ 源泉・吸収
元となる場所のこと
___
––– データストア
データの蓄積のこと。データストア同士は直接ではなく、◯を通して結ばれる
◯ 処理
何かしらの処理を行うこと
正規化
データ項目のグループ化のこと
第1正規化から第3正規化まで行うことが多い


それぞれの目的
第1正規化→値の重複をなくす
第2 →
第3 →冗長性をなくし、更新時異状を回避する
関係演算の種類
○行=タプル(組)=横
○列=属性=縦
✅選択
行(横一列)を取り出すこと
✅射影
列(縦一列)を取り出すこと
✅結合
表同士で共通の列を繋げること
SQL文
*問い合わせ
SELECT(全ての列を取得)のこと
副問い合わせ
SELECT文の中で、SELECT文を記述
・FROM句
・WHERE句
・相関副問合せ
*和
UNION句を使用し、複数の表を縦にそのまま合わせること
※結合→同じ項目があれば横につなげる
SELECT * FROM 社員 UNION SELECT * FROM 入社予定者
*直積
2つの表を、全ての行に対して組み合わせること
3行の表と・3行の表があれば、3×3=9で9行の表を作成
※直積とWHERE句を使うことで、内部結合と同じ結果を得られる
〇選択で用いる文
例えば、商品コードが26と等しい商品を選ぶとき
SELECT * FROM 商品 WHERE 商品コード = 26
= 等しい
<= 小なり
<> 否定
※WHERE句には、AND,OR,NOTの記述が可能
・パターン検索
・範囲指定
・複数指定
・NULLの指定
〇射影で用いる文
SELECT
全ての列を取得
※同じ列を、重複して選択できる
(例)
SELECT 商品名, 単価, 最終入荷日 FROM 商品
SELECT 商品名 AS 名前, 単価 AS 価格, 最終入荷日 AS 入荷日 FROM 商品 WHERE 商品コード IN (1,2)
・条件分岐
(例)単価が300以下であれば「割引対象」、それ以外なら「通常価格」と表示したい
SELECT 商品名, CASE WHEN 単価 <= 300 THEN '割引対象' ELSE '通常価格' END
FROM 商品
CASE WHEN (条件)
THEN(条件に合致した場合に表示する内容)
ELSE (条件に合致しない 〃 )
◆整列
ORDER BYを使用して、昇順・降順に並べること
ASC=昇順 DESC=降順
(例)
SELECT * FROM 商品 ORDER BY 単価ASC, 在庫数量 DESC
◆グループ分け
GROUP BYを使用して、グループ分けを行うこと
(例)
SELECT * FROM 社員 GROUP BY 性別、年代
①集約関数
COUNTやSUM等の後に(給与額)というように、特定の項目の各種値を求める関数のこと
②条件指定
集約関数で値を求めたら、さらにそこからWHERE句で特定のデータのみを取り出すこと
※WHERE句は、必ずGROUP BYの前!!
(例)
SELECT 性別、年代、AVG(給与額) AS 平均給与
FROM 社員
WHERE 性別 = '女性'
GROUP BY 性別、年代
SELECT 〃
FROM 〃
GROUP BY 〃
HAVING 性別='女性'
※HAVING句はGROUP BYの後!!
〇結合で用いる文
INNER JOIN句で、2つのテーブルをつなげること
(例)
SELECT
社員コード、社員名、性別、都道府県、住所、部署、電話番号
FROM 社員 INNER JOIN 都道府県 ON 社員.都道府県=都道府県.都道府県
◆内部結合
INNER JOINで、社員テーブルと、都道府県テーブルを結合させること
◆外部結合
OUTER JOIN句で、内部結合で結合条件に一致しなかったレコードが取得できなかった場合に行う
1,2つのテーブルを指定項目で結合し取得する
2,もし一方テーブルのレコードのうち、結合から漏れたレコードは、取得対象とする
(例)
SELECT
社員コード、社員名、性別、都道府県名、住所、部署、電話番号
FROM 社員 LEFT OUTER JOIN 都道府県 ON 社員.都道府県=都道府県.都道府県
※LEFT OUTER JOINは、左外部結合
データの変更
◆追加
INSERT句で、データを追加すること
(例)
INSERT INTO 社員 (社員コード、社員名、都道府県コード、住所、部署)
VALUES(4、'吉田'、1、XXXXX、'システム部' )
◆更新
UPDATE句で、データを更新すること
(例)
UPDATE 社員 SET 部署 = ‘システム部’
WHERE 社員コード = 3
参考問題
◆削除
DELETE句で、レコードを削除すること
(例)
DELETE FROM 社員 WHERE 社員コード =4
テーブルの作成と修正
◆テーブルの作成
CREATE TABLE文で、テーブルを作成
◆テーブルの修正
ALTER TABLE文で、テーブルの構造を変更する
テーブルの種類
・ファクトテーブル
スターテーブルの中心にある、時間の経過によって発生する数値データがあるテーブル
・ディメンションテーブル
属性データがあるテーブル

ビュー
給与額など、あまり見せたくないカラムを、見えないようにした仮想のテーブルのこと
CREATE VIEW文で、仮想テーブルを作成する
📌SQL文 問題


スキーマとは
データベースの構造や仕様を記述するもの。
3層スキーマアーキテクチャ
以下の3つに定義を分けることで、データの構造を変化してもプログラムに影響しないようにすること
☑️外部スキーマ(サブスキーマ)
利用者の必要とするデータの見方を表現
☑️概念スキーマ
データの論理的関係を表現
☑️内部スキーマ
データの物理的関係を表現
データベースを記録媒体にどのように格納するかを記述

2.トランザクション管理
データベースで一連の処理をまとめたもの
データベースを複数人で管理するときに必要
ACID特性
NoSQLデータベースや分散システムの動作を説明するための概念
✅原子性(Atomicity)
0か100か
トランザクションの処理結果が、「全て実行されるか」「全く実行されないか」のどちらかで終了すること
✅一貫性(Consistency)
データベースの内容が矛盾のない状態であること
✅独立性(Isolation)
お互いの処理が干渉しないこと
✅耐久性(Durability)
障害が発生しても、復旧できること
BASE特性
NoSQLデータベースや分散システムの動作を説明するための概念
ACID特性とは反対に、可用性を重視するが、データの整合性は保証しない
BA (Basically Available)
基本的にいつでも利用でき、最低限の機能を提供し続ける
S (Soft State)
システムの状態が常に整合性を保つわけではなく、
時間の経過やデータの更新に応じて変化する可能性があること
E (Eventual consistency)
データの整合性は即時に保証されるわけではないが、
結果的に整合性が保たれていればよい
☆トランザクション回復処理
☆トランザクションの種類
・2層コミットプロトコル
トランザクションの原子性・一貫性を保証する
【第1層(投票層)】
①主サイトが従サイトに対し、コミットの可否を問い合わせる
②従サイトが応答
👇
【第2層(決定層)】
①コミット可能なら、コミットするように従サイトに要求
②コミットできないなら、ロールバックを指示

排他制御
同時更新による、データの不整合を防ぐために
他の人が読み書きできないようにすること
✅共有ロック
他のユーザーはデータを読み込める(SELECT文だけ許可する)が、書けない
✅専有ロック
他のユーザーはデータの読み込み、書き込みともにできない
2相ロッキングプロトコル(2相ロック)
以下の2ステップでロックを操作すること
テーブルを更新する直前に、そのテーブルにロックをかける
トランザクションの終了時に、全てのロックを解除する
👍お互いの処理が干渉しづらいため、高い独立性(ACIDのI)が維持できる
❌デッドロックが発生する可能性がある
デッドロック
いわゆる、行き詰まり状態のこと
【重要】
順番が同じなら、とりまデッドロックは防げる
※No.SQL
以上で記述してきたRDBよりも手軽な代わりに、SQLが使えない
↓
データを取り出すとき、基本的にプログラムで記述する
ACID特性がなく、BASE特性がある
キー・バリュー型
1つのキーに1つの値を結びつけてデータを格納する

カラム指向
行キーに対してカラム(名前と値の組み合わせ)を結びつけて格納する
ドキュメント指向
XMLやJSONなどの構造でデータを格納する
グラフ指向
グラフ理論に基づいてデータ間の関係性を表現する
3.バックアップ
フルバックアップ
保存される、全てのデータをバックアップ
👍復旧まで短時間
✖ 読み込み処理に時間かかる
差分バックアップ
前回のフル分
+
変更された分のみをバックアップ
👍読み込み処理は短時間
✖ 復旧まで時間かかる
増分バックアップ
フルバックアップ
+
増分
これらを全てバックアップ
ロールフォワード
更新後ログを使って、コミット済みのトランザクションを、データベースに適用
ロールバック
更新前ログを使って、データベースをトランザクション以前の状態に戻すこと
この記事が気に入ったらサポートをしてみませんか?