プログラミング初心者が競馬予想プログラムを作ってみた!!!

はい、Aidemyでデータ分析の講座を受け始め、成果物として競馬予想していこうと思うのですが、正直なところ、競馬自体もそんなに詳しくなかったので結構、競馬自体を調べるのが辛かったです。
では、さっそくやっていきます!
まずデータ収集から、提供されたデータセットには競馬データはなかったのでスクレイピングをしていきます!
pip install beautifulsoup4beaytifulsoup4のインストール
pip install requestsrequestsのインストール
import os
os.mkdir("./data")スクレイピングのデータフォルダを先に作成しときます。
import requests
from bs4 import BeautifulSoup
import time
import csv #取得開始年
year_start = 2020 #取得終了年
year_end = 2024
for year in range(year_start, year_end):
race_data_all = []
#取得するデータのヘッダー情報を先に追加しておく
race_data_all.append(['race_id','馬','騎手','馬番','走破時間','オッズ','通過順','着順','体重','体重変化','性','齢','斤量','上がり','人気','レース名','日付','開催','クラス','芝・ダート','距離','回り','馬場','天気','場id','場名'])
List=[]
#競馬場
l=["01","02","03","04","05","06","07","08","09","10"]
for w in range(len(l)):
place = ""
if l[w] == "01":
place = "札幌"
elif l[w] == "02":
place = "函館"
elif l[w] == "03":
place = "福島"
elif l[w] == "04":
place = "新潟"
elif l[w] == "05":
place = "東京"
elif l[w] == "06":
place = "中山"
elif l[w] == "07":
place = "中京"
elif l[w] == "08":
place = "京都"
elif l[w] == "09":
place = "阪神"
elif l[w] == "10":
place = "小倉"
#開催回数分ループ(6回)
for z in range(7):
#開催日数分ループ(12日)
for y in range(13):
race_id = ''
if y<9:
race_id = str(year)+l[w]+"0"+str(z+1)+"0"+str(y+1)
url1="https://db.netkeiba.com/race/"+race_id
else:
race_id = str(year)+l[w]+"0"+str(z+1)+"0"+str(y+1)
url1="https://db.netkeiba.com/race/"+race_id
#yの更新をbreakするためのカウンター
yBreakCounter = 0
#レース数分ループ(12R)
for x in range(12):
if x<9:
url=url1+str("0")+str(x+1)
current_race_id = race_id+str("0")+str(x+1)
else:
url=url1+str(x+1)
current_race_id = race_id+str(x+1)
try:
r=requests.get(url)
#リクエストを投げすぎるとエラーになることがあるため
#失敗したら10秒待機してリトライする
except requests.exceptions.RequestException as e:
print(f"Error: {e}")
print("Retrying in 10 seconds...")
time.sleep(10) # 10秒待機
r=requests.get(url)
#バグ対策でdecode
soup = BeautifulSoup(r.content.decode("euc-jp", "ignore"), "html.parser")
soup_span = soup.find_all("span")
#馬の数
allnum=(len(soup_span)-6)/3
#urlにデータがあるか判定
if allnum < 1:
yBreakCounter+=1
print('continue: ' + url)
continue
allnum=int(allnum)
race_data = []
for num in range(allnum):
#馬の情報
soup_txt_l=soup.find_all(class_="txt_l")
soup_txt_r=soup.find_all(class_="txt_r")
#走破時間
runtime=''
try:
runtime=soup_txt_r[2+5*num].contents[0]
except IndexError:
runtime = ''
soup_nowrap = soup.find_all("td",nowrap="nowrap",class_=None)
#通過順
pas = ''
try:
pas = str(soup_nowrap[3*num].contents[0])
except:
pas = ''
weight = 0
weight_dif = 0
#体重
var = soup_nowrap[3*num+1].contents[0]
try:
weight = int(var.split("(")[0])
weight_dif = int(var.split("(")[1][0:-1])
except ValueError:
weight = 0
weight_dif = 0
weight = weight
weight_dif = weight_dif
soup_tet_c = soup.find_all("td",nowrap="nowrap",class_="txt_c")
#上がり
last = ''
try:
last = soup_tet_c[6*num+3].contents[0].contents[0]
except IndexError:
last = ''
#人気
pop = ''
try:
pop = soup_span[3*num+10].contents[0]
except IndexError:
pop = ''
#レースの情報
try:
var = soup_span[8]
sur=str(var).split("/")[0].split(">")[1][0]
rou=str(var).split("/")[0].split(">")[1][1]
dis=str(var).split("/")[0].split(">")[1].split("m")[0][-4:]
con=str(var).split("/")[2].split(":")[1][1]
wed=str(var).split("/")[1].split(":")[1][1]
except IndexError:
try:
var = soup_span[7]
sur=str(var).split("/")[0].split(">")[1][0]
rou=str(var).split("/")[0].split(">")[1][1]
dis=str(var).split("/")[0].split(">")[1].split("m")[0][-4:]
con=str(var).split("/")[2].split(":")[1][1]
wed=str(var).split("/")[1].split(":")[1][1]
except IndexError:
var = soup_span[6]
sur=str(var).split("/")[0].split(">")[1][0]
rou=str(var).split("/")[0].split(">")[1][1]
dis=str(var).split("/")[0].split(">")[1].split("m")[0][-4:]
con=str(var).split("/")[2].split(":")[1][1]
wed=str(var).split("/")[1].split(":")[1][1]
soup_smalltxt = soup.find_all("p",class_="smalltxt")
detail=str(soup_smalltxt).split(">")[1].split(" ")[1]
date=str(soup_smalltxt).split(">")[1].split(" ")[0]
clas=str(soup_smalltxt).split(">")[1].split(" ")[2].replace(u'\xa0', u' ').split(" ")[0]
title=str(soup.find_all("h1")[1]).split(">")[1].split("<")[0]
race_data = [
current_race_id,
soup_txt_l[4*num].contents[1].contents[0],#馬の名前
soup_txt_l[4*num+1].contents[1].contents[0],#騎手の名前
soup_txt_r[1+5*num].contents[0],#馬番
runtime,#走破時間
soup_txt_r[3+5*num].contents[0],#オッズ,
pas,#通過順
num+1,#着順
weight,#体重
weight_dif,#体重変化
soup_tet_c[6*num].contents[0][0],#性
soup_tet_c[6*num].contents[0][1],#齢
soup_tet_c[6*num+1].contents[0],#斤量
last,#上がり
pop,#人気,
title,#レース名
date,#日付
detail,
clas,#クラス
sur,#芝かダートか
dis,#距離
rou,#回り
con,#馬場状態
wed,#天気
w,#場
place]
race_data_all.append(race_data)
print(detail+str(x+1)+"R")#進捗を表示
if yBreakCounter == 12:#12レース全部ない日が検出されたら、その開催中の最後の開催日と考える
break
#1年毎に出力
#出力先とファイル名は修正してください
with open('data/'+str(year)+'.csv', 'w', newline='',encoding="SHIFT-JIS") as f:
csv.writer(f).writerows(race_data_all)
print("終了")こちらがスクレイピングする為のコードとなります。
めちゃくちゃ時間掛かると思いますが心配ご無用!
こちらがデータとなります。
https://drive.google.com/drive/folders/1JVO5lSYBznTvlBfl9oUh_LKO3Ec_XHH1?usp=sharing
from google.colab import files
uploaded = files.upload()
import io
import pandas as pd
df = pd.read_csv(io.StringIO(uploaded['2023.csv'].decode('SHIFT-JIS')))
print(df.head())データをgooglecolab上にアップロードします。
"2023.csv"のところを変えればアップロードできます。
import pandas as pd
csv_files = ['2020.csv', '2021.csv', '2022.csv', '2023.csv']
dfs = [pd.read_csv(file, encoding='SHIFT-JIS') for file in csv_files]
df = pd.concat(dfs)
print(df.head())はい、4年分のデータを結合させます。
約160000件のレースデータがここに集結しました
df = df.dropna()欠損値は削除します!
確認しましたが大した数の欠損値では無かったはずです。
def time_to_seconds(time_str): #m :s.sを秒数に変換
minutes, seconds = map(float, time_str.split(':'))
return minutes * 60 + seconds
df['走破時間'] = df['走破時間'].apply(time_to_seconds)
df[['馬', '走破時間']].head()前項から始まっていましたがデータクレンジングです!
このセルでは走破時間を秒に変換します、
なぜなら:が文字列になるからです!
df['オッズ'] = df['オッズ'].astype(float)
df['性'] = df['性'].replace({'牡': 0, '牝': 1, 'セ': 2})
df['回り'] = df['回り'].map({'右': 0, '左': 1, '芝': 2, '直': 2})
df['馬場'] = df['馬場'].map({'良': 0, '稍': 1, '重': 2, '不': 3})
df['天気'] = df['天気'].map({'晴': 0, '曇': 1, '小': 2, '雨': 3, '雪': 4})どんどん数値化していきます!
オッズ、、、float型に変換。
性、、、とりあえず0,1,2で
回り、、、同じく0,1,2,で
・・・
# Define a function to label distances with numerical values based on the given criteria
def numerical_label(distance):
if 1000 <= distance <= 1400:
return 0 # 短距離
elif 1401 <= distance <= 1600:
return 1 # マイル
elif 1601 <= distance <= 2400:
return 2 # 中距離
else:
return 3 # 長距離
# Apply the function to the '距離' column to update the '距離ラベル' column with numerical values
df['距離ラベル'] = df['距離'].apply(numerical_label)
# Drop the '距離' column
df.drop(columns=['距離'], inplace=True)
# Display the first few rows of the dataframe to verify the changes
df[['距離ラベル']].head()距離、データで確認すると色んな距離の種類があるもんです、
なので、4つに分類。
df['場名'] = df['場名'].astype('category')
df['場名コード'] = df['場名'].cat.codes
venue_mapping = dict(enumerate(df['場名'].cat.categories))
df.drop(columns=['場名'], inplace=True)場名はコードを振り分けます。
df = df[df['芝・ダート'].isin(['芝', 'ダ'])]
df['芝・ダートコード'] = df['芝・ダート'].map({'芝': 0, 'ダ': 1})
df.drop(columns=['芝・ダート'], inplace=True)
df[['芝・ダートコード']].head()芝・ダートは結構重要みたいです。
が0,1でラベル付け。
df['年'] = df['日付'].str.extract(r'(\d{4})年').astype(int)
df.drop(columns=['日付'], inplace=True)日付、年さえあれば大丈夫!
特徴量では無い!
df.drop(columns=['レース名', '開催'], inplace=True)
df.head()レース名、開催、いらんでしょー!
df['クラスコード'] = df['クラス'].astype('category').cat.codes
passing_order = df['通過順'].str.split('-', expand=True).astype(float)
passing_order.columns = [f'通過順_{i+1}' for i in range(passing_order.shape[1])]
df = pd.concat([df, passing_order], axis=1)
df.drop(columns=['通過順', 'クラス'], inplace=True)
df.head()クラスはカテゴリ分け、通過順は四つの地点で測られてるので4分割。
jockey_stats = df.groupby('騎手').agg(
wins=('着順', lambda x: (x == 1).sum()),
total_races=('着順', 'count')
)
jockey_stats['win_rate'] = jockey_stats['wins'] / jockey_stats['total_races']
jockeys_less_than_20_wins = jockey_stats[jockey_stats['wins'] < 20]
df = df[~df['騎手'].isin(jockeys_less_than_20_wins.index)]
remaining_rows_after_filtering = df.shape[0]
remaining_rows_after_filtering特徴量がなんか足りないような感じがするので騎手の勝率を加えます!
あと、20勝未満の騎手は今回は学習させてません。
jockey_stats_filtered = df.groupby('騎手').agg(
wins=('着順', lambda x: (x == 1).sum()),
total_races=('着順', 'count')
)
jockey_stats_filtered['win_rate'] = jockey_stats_filtered['wins'] / jockey_stats_filtered['total_races']
df['勝率'] = df['騎手'].map(jockey_stats_filtered['win_rate'] * 100) # Convert to percentage
df['騎手ID'] = df['騎手'].astype('category').cat.codes
df[['騎手', '騎手ID', '勝率']].head()勝率は結構、大事でしょ、*100で%にしました。
df['馬ID'] = df['馬'].astype('category').cat.codes馬にはIDを振り分けましょう!
df.drop(columns=['通過順_2', '通過順_3', '通過順_4'], inplace=True)
remaining_columns = df.columns
remaining_columnsはい!ごめんなさい、
分割した通過順2,3,4に関しては
欠損値とNaN値が多かったので削除します。
df.drop(columns=['馬', '騎手', 'race_id'], inplace=True)
remaining_columns_after_drop = df.columns
remaining_columns_after_drop馬、騎手、race_idは削除!
df.drop(columns=['オッズ', '人気', '場id'], inplace=True)
remaining_columns_after_drop = df.columns
remaining_columns_after_dropオッズ、人気、場idは削除!
df.to_csv('数.csv',encoding='SHIFT-JIS', index=False)data = df.copy()ちょっと一息。。。
data['target'] = data['着順'].apply(lambda x: 1 if x <= 3 else 0)
X = data.drop(columns=['着順', 'target'])
y = data['target']
X.head(), y.head()ここはどうだろう。
とりあえず着順3位を目的変数に!
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
X_train_scaled[:5], y_train.head()訓練データとテストデータを8対2で分けて、数値の標準化をします。
import tensorflow as tf
from tensorflow.keras import layers, models
tf.random.set_seed(42)
model = models.Sequential()
model.add(layers.Dense(128, activation='relu', input_shape=(X_train_scaled.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(X_train_scaled, y_train, epochs=20, batch_size=32, validation_split=0.2)人間の作業はほぼここまでじゃないですか。
tensorflowとkerasの出番です。
訓練データの学習過程をエポック毎に可視化します。
結果がこちら
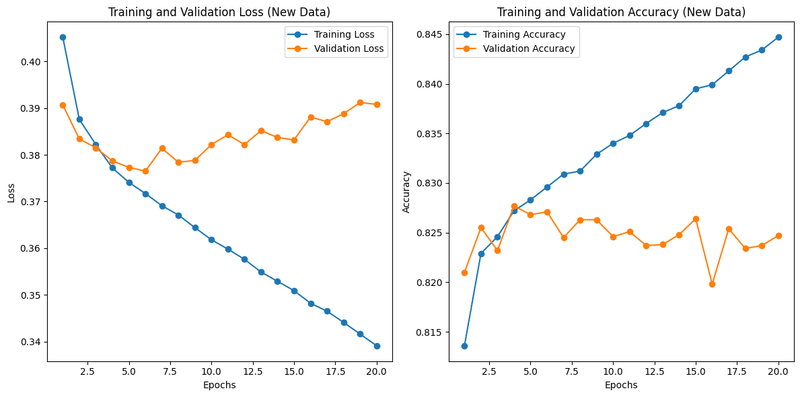
精度に関しても訓練データは順調ですが、
テストデータがイマイチ、過学習?
from tensorflow.keras import regularizers
model = models.Sequential()
model.add(layers.Dense(128, activation='relu', kernel_regularizer=regularizers.l2(0.01), input_shape=(X_train_scaled.shape[1],)))
model.add(layers.Dense(64, activation='relu', kernel_regularizer=regularizers.l2(0.01)))
model.add(layers.Dense(32, activation='relu', kernel_regularizer=regularizers.l2(0.01)))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(X_train_scaled, y_train, epochs=20, batch_size=32, validation_split=0.2)L2正則化で、、、結果がこちら
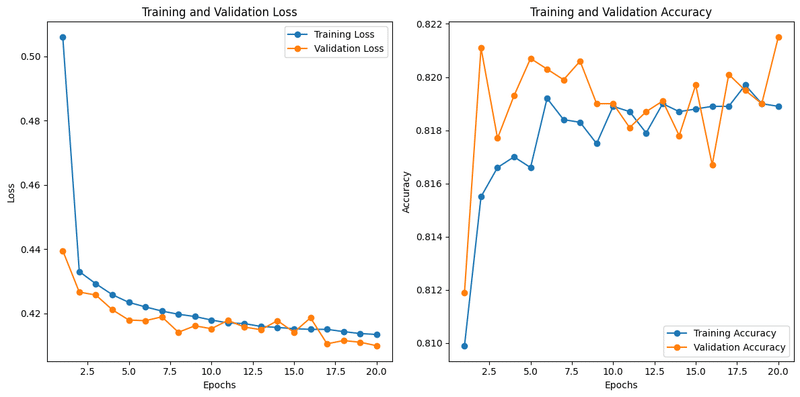
本当に僕は競馬、全然分かりません!
なので熟練の競馬ファンの方に特徴量の捉え方を教えて頂いたらもっといい数値になったかもしれません。いかんせん、ほぼGoogle検索で調べた位の知識ですので。
次はアプリ開発の講座を受講するつもりでありますので、またこれをいかして競馬予想アプリなんか作れればいいな〜、と思っています。
この記事が気に入ったらサポートをしてみませんか?