
Mac User向け。【Stable diffusion】Google Colaboratory WebUIで利用制限がかかり困っている人のためのアプリ「Draw Things App」の活用方法など(1)

2023年5月16日一部修正
1.はじめに
みなさん、初めまして!
2023年の3月くらいからTwitterでAI画像を投稿している(@EyesCandyofArts)と申します。
私はTwitterで見かけた写真がAIによって作成された画像だと知って自分でも理想の姿を作成してみたい!と思い自分なりに調べてなんとかAIで作成できるまでに至りました。
しかし私は、TwitterでAI画像について考察やモデルの作成・マージ、LoRAの作成などなど、日々熱心に研究されている諸先輩方と違って、原理も何もかも詳しいことは分かりません!!ので!その辺をもし質問とかされても答えることが出来ませんのでよろしくお願いします。
また、あまり世の中の常識などを勉強していないので、これから書く文章等でもし不適切だったり、これだめだよ?って言うものがありましたら訂正・削除しますのでお知らせください。
こういったものを作成するのが初めてなので、どうかみなさん生暖かい目で見守っていただけたら幸いです!!(願
2.Draw Things Appとは
Draw ThingsはAppleのApp Storeから無料でインストールができ、無料で使用することができる、iOSとmacOS用のAI GENERATION アプリです。
ですので、iPhone・iPad・MacBook・Macでダウンロードさえ終わっていればネット環境がなくともAI画像が生成することが出来ます。
試していないので確実には言えませんが、Windowsでは使用できないと思います。
また、最近わかったことなのですがIntel Mac(MacにIntelのCPU(PC/AT互換)を採用した製品群)はまだ実験的な段階で、安定して動作しないようです。
私の使用しているPCはMacBookProなのでこれから記載する使用方法等はMac及びMacBookのものになります。
使用PCのスペックは下記に示します。
MacBook Pro(14インチ、2021)
チップ Apple M1 Pro
メモリ 16 GB
コア総数 10(パフォーマンス:8、効率性:2)
では簡単にインストールから生成までの説明をしていきます。(UI等の細かい説明は次回。。。)
3.インストールから生成まで
(1) App StoreからDraw Thingsをインストール
ここは説明不要ですね!
App Storeの検索欄で DrawThings と入力すると出てきますので入手して下さい。

(2) modelのインポート
インストールが終わったらアプリを開きます。(確か自動で起動したような気がします)
自動で起動しない場合は
Launchpadの中にDraw Thingsのアプリアイコンがあるのでクリックして起動して下さい。

UIの左上にあるModelのプルダウンをクリックすると図2のように表示されます。
Manageを選択しクリックすると

図3のようなウインドウが開きます。
モザイクのところは初期状態だとgeneric(記憶が正しければstaible diffusion:v1.5)だけがインポートされています。
使用したいモデルをインポートするには赤丸のところをクリックします。
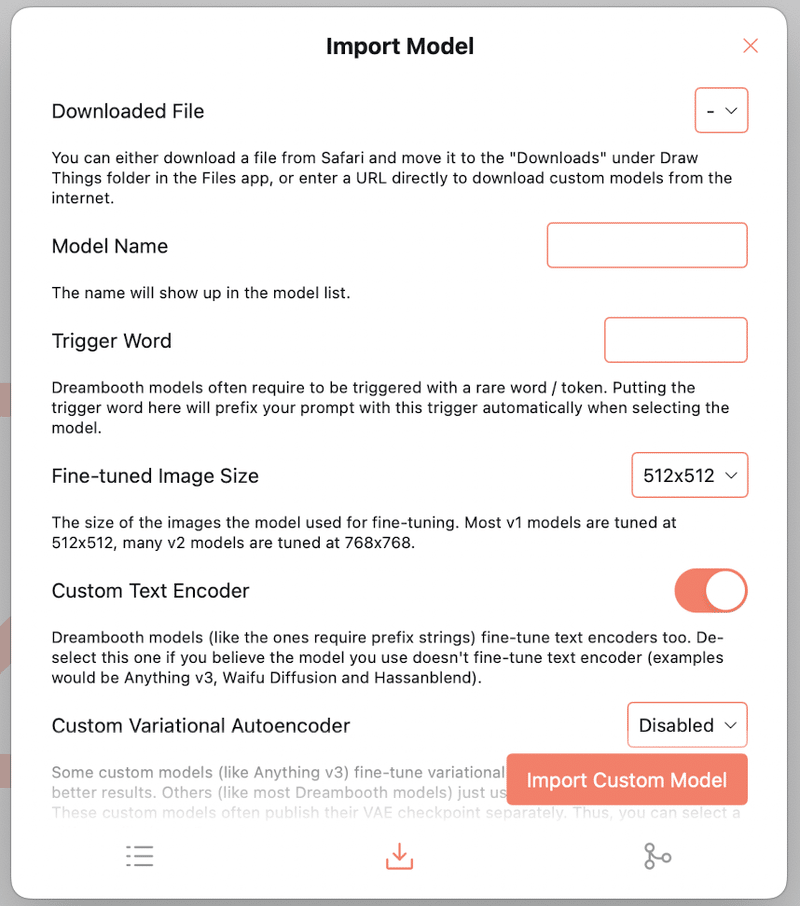
Downloaded Fileのプルダウンをクリックします。
英語の説明には
「Safari」からファイルをダウンロードして、「Files」アプリの「Draw Things」フォルダ内の「Downloads」に移動する方法と、インターネットからカスタムモデルを直接ダウンロードするためにURLを入力する方法の両方があります。と書いています。
今回はPCにダウンロードしてからインポートする方法を書いています。(URL入力の方法はやったことがありません。。。)
ですので、あらかじめ使用したいモデルをサイトからダウンロードしておく必要があります。
サイトからダウンロードしたファイルが格納される場所は、ダウンロードの際に設定を変更していなければ、Macintosh HD/user/user名/download のフォルダ内にあります。
downloadフォルダ以外にモデルファイルがある場合のやり方もあるのですが、今回はdownloadフォルダ内にモデルファイルを入れていて下さい。

プルダウンをクリックすると図5のような表示になります。
今回はLoadingを選択してクリックします。
注)一回クリックするとプルダウン表示が消え図4のように戻りますが慌てないでください!自分が最初え?なんで?ってなった為一応(笑)。
もう一度プルダウンをクリックしLoadingを選択すると

用意してあったモデルのファイル名が表示されるので、そのファイルを選択します。
今回は私も使用させていただいている@PleaseBanKaiさんのBRAV5を選択した画像を使わせていただいています。(問題がある場合は違うモデルの画像を使用しますのでご連絡ください。)

ファイルを選択すると、Model Nameは勝手に入力されます。手動変更可能です。
Trigger Wordはモデルには必要がないと思いますので空欄のまま。
Fine-tuned Image Sizeは SDv1.xであれば512*512。SD2.xであれば768*768になるそうです。
Custom Text Encodeは説明には
「Dreambooth」モデル(プレフィックス文字列が必要なモデル)もテキストエンコーダーを微調整しています。もし使用しているモデルがテキストエンコーダーを微調整していないと思われる場合は、このオプションを選択解除してください(例:Anything v3、Waifu Diffusion、Hassanblendなど)。
と書いています。ちょっと私にはよくわからないのでONにしたままにしています(汗)。
ウインドウを下にスクロールすると

Custom Variational Autoencoderがあります。これはインポートするモデルに好きなVAEを適用させるところです。説明には
一部のカスタムモデル(例:Anything v3)は、さらに良い結果を得るために変分オートエンコーダー(VAE)を fine-tune しています。その他のカスタムモデル(例:ほとんどのDreamboothモデル)はデフォルトのオートエンコーダーを使用しています。これらのカスタムモデルでは、通常、VAEのチェックポイントを別途公開しています。そのため、VAEには別のファイルを選択することができます。とあります。
残念ながら私はこの辺もよく分からないので使用する全てのモデルにvae-ft-mse-840000-ema-prunedのVAEを適応してインポートしています。(どなたか詳しい方がいらしたら教えていただきたい。。。。泣)
VAEファイルの選択のやり方も、モデルと一緒でまずダウンロードフォルダの中にあらかじめ用意しておきLoadingからファイルを選択します。図9

その他下にある項目はSDv2.xでの設定のようなので、おそらく皆様WebUIでご使用になっていたモデルはSDv1.5のものが多いはずなので触らなくて大丈夫かと思います。
VAEまで設定したらオレンジ色のボタン Import Custom Modelをクリックします。
これでモデルのインポートは完了します。
IntelMacの場合、このインポートの時点でアプリがクラッシュし強制終了してしまう場合があるそうです。またGENERATION時にも同様に強制終了してしまう場合が多くdiscoで作成者に問い合わせてみたのですが、改善するかはまだ分からないそうです。DiscordのDraw Things Officialチャンネルで
2023年5月16日 0:05のお知らせでIntelMacのモデルインポート時のクラッシュは修正されたそうです!
(3) LoRAのインポート
DrawThingAppでもLoRAを使用できます。
ただ、私の試行回数や使いこなせていない部分は大きいのですがWebUIで使用するよりLoRAが効いているのか分からなかったり、逆にすごい効きすぎて使用するには悩ましかったりします。
インポートの方法は、これもモデルとVAEと同じで

LoRAのプルダウンをクリックしManageを開きます。
LoRAリストの下の方に雲のマークがついているものはデフォルトでクリックするとインポートできるものがあります。(使ったことがありませんが)

ここもまたダウンロードフォルダにLoRAファイルをあらかじめ用意しておき、Loadingを2回クリックしLoRAファイルを選択します。
Nameは自動で入ります。手動変更可能です。
Trigger Wordはダウンロードしたサイトに記載しているものや、説明テキスト等にあるものをコピペで入力します。
設定が終わったら、オレンジ色のImport LoRAをクリックします。

LoRAはプルダウンボタンの右隣の+ボタンをクリックしていくといくつも使用できるようになります。
(4) Textual Inversion(TI)のインポート
TIも使用できます。
TIのインポートもモデル・VAE・LoRAと同様です。
Bad Point2など一部のTIはデフォルトで入っていますのでまず覗いてから必要なTIファイルをダウンロードしてきて下さい。

TIの場所は左側のUIを一番下までスクロールすると出てきます。
水色のボタンをクリックすると

インポート画面が出ますので、これまでと同じようインポートして下さい。
TIの使用方法はポジティブ系ならポジティブの場所に、ネガティブ系ならネガティブのテキスト入力欄に<>を入力します。
そうすると入力欄の下のテキスト欄に<>の場所にクリップマークができます。図15・16


下のテキスト欄のクリップのマークのところで右クリックするとTIのリストが出てくるので、選択すると有効になります。図17・18

4.おわりに
以上で
今とりあえず制限がかかって思うように作成ができない!
今すぐはじめたいけどMacしか持っていない!
iPhone・iPadしか持ってない!(こちらの説明はしていませんがおそらく簡単にできると思います。)
という方々のお役に立てたらと思います。
UIの説明等は、また後日時間があれば書きたいと思ってます。
最後にどんな画像が出るか

お気付きになる方の突っ込みが聞こえそうなので先に
おそらく【Stable diffusion】Google Colaboratory WebUIで生成されている方々は画像サイズが512*768くらいだと思います。
WebUIは色々な処理ができるので(らしいので)そのサイズでもお顔の解像度が高い画像を生成できるようなのですが、DT(DrawThings)はどう足掻いてもそのサイズで太ももくらいまで入る人物を生成すると、お顔が崩れます。ですので私はある程度小さい画像サイズでバッチ数を増やし好みの構図が出たSeedで一度レイヤーを白紙にし画像サイズを上げて同じプロンプトを使用して作成しています。
もしこの記事を見て、DTを触る機会があるスペシャリストの方、これから始める方がいて、もっといい方法があるよ!!と教えていただける日が来ればいいなぁ。。と安直に考えて画像生成を楽しんでいます!
それではまた!
この記事が気に入ったらサポートをしてみませんか?