Pythonでグラフを描く①データセットの作成

このシリーズでは、pythonを使って(できる限り簡単なコードを使用して)グラフを描くための方法を紹介していく。グラフを描く前にシリーズ①では疑似的なデータセットを作成する。
まずはpythonのコードを書くために必要なライブラリーをセッティングすることから。
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')#グラフの背景を白くする
%matplotlib inlineデータセットを作成
こんかいは疑似的に平均値50、標準偏差20のデータを500行3列のデータセットを作成する。それぞれの列には、"Score1", "Score2", "Score3"という名前を作成しておく。
Col=["Score1", "Score2", "Score3"]
data=np.random.normal(50, 20, (500, 3))#平均値50 標準偏差20 500行3列の乱数
df=DataFrame(data, columns=Col)データセットを作成するのに参考にしたwebページ
・Numpy で乱数を生成する
https://pythondatascience.plavox.info/numpy/%E4%B9%B1%E6%95%B0%E3%82%92%E7%94%9F%E6%88%90
・【Pandas入門】pandasのindexの扱いと行に名前を付けるset_index!
https://www.sejuku.net/blog/75505
・【Pandas入門】DataFrame等の列の名前を指定できるcolumns引数!
https://www.sejuku.net/blog/75495
データセットの最初の5行を見てみる
df.head()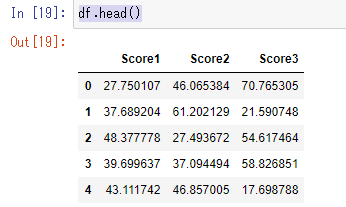
データセットが作成できたのが分かる。行が0からになっているので、1からに変更する。一度CSVファイルにはきだし、EXCEL上で1から始まる列を作成する。EXCELが使えるなら、pythonのコードだけに頼る必要は必ずしもないと考えている。
df.to_csv("sample.csv")CSVファイルのエクスポートに参考したwebページ
・Pandas のデータフレームを CSV ファイルやテキストファイルに出力する
https://pythondatascience.plavox.info/pandas/%E3%83%87%E3%83%BC%E3%82%BF%E3%83%95%E3%83%AC%E3%83%BC%E3%83%A0%E3%82%92%E5%87%BA%E5%8A%9B%E3%81%99%E3%82%8B
sampleというCSVファイルを作成した。CSVファイルを開いて、1から行数を振るidという列を作成する。

上書き保存をして、pythonで読み込む
df2=pd.read_csv('sample.csv')読み込んだCSVファイルのデータフレームの名前をdf2とした。
df2の最初の10行を見てみる。head()関数を使用して、()の中に10を入れる。
df2.head(10)
作成したCSVファイルをダウンロードできるようにしておく。このファイルを使って、ヒストグラムと散布図のグラフをこれから描いていく。
今日はこんな感じ。