Pythonでグラフを描く⑧Profiling Reportの活用

今回はProfiling Reportの機能を使って、統計量、ヒストグラム、相関図などを一気に出力する方法を纏めた。
このコードを使えば、データの特徴が把握できる。一つのデータに対して平均値を出したりヒストグラムを作成しなくても、一つのコードでデータ全体の平均値やヒストグラムを作成してくれる。データを扱う上ではかなり役にたつ機能だと考えている。
用いるデータは、Score1、Score2、Score3と三つのデータが存在し、それぞれのデータは平均値50(標準偏差20)で500行1乱数発生により作成した。また、乱数発生によりランダムに振り分けた性別(男性/女性)の情報が加わったデータセットを扱う。データセットのダウンロードは↓。
1. データのインポート
まずは、必要なライブラリーをインポートする。
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')#グラフの背景を白くする
%matplotlib inline次にサンプルデータの読み込み
df_all=pd.read_csv("sample5.csv")読み込んだデータの最初の5行を見てみる。
df_all.head()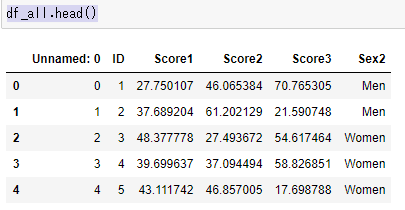
最初の行に「Unnamed:0」というよくわからない列が入っているので消去する。
df_all=df_all.drop(df_all.columns[0],axis=1)
df_all.head()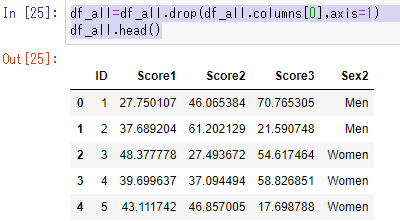
無事に削除できたことが確認できた。
2. Profiling Report
ここからが今日のメインイベントProfiling Reportを使用する。まずは、Profiling Reportを使用するためのライブラリーをインポートする。(注意:インポートするまえに、pipやcondaなどを使って事前にインストールしておく必要がある)
import pandas_profiling これで準備完了。早速pandas_profilingのコードを使用する。まず、pandas_profilingと書き、その後ドットを付けてProfileReportと書く。最後のカッコには使用するデータフレームの名前を入れる。今回は、df_allを用いている。
pandas_profiling.ProfileReport(df_all)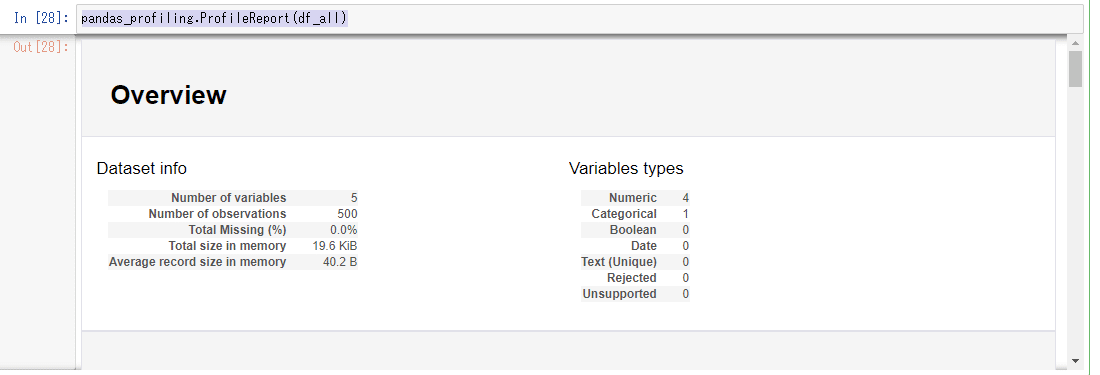
コードが実行されると↑の画面がjupyter notebook上に現れる。右端に見えるようにスクロールすると全体が見えるが、これだと見ずらいので、htmlファイルに保存してブラウザ上で結果を見てみる。pandas_profiling.ProfileReport(df_all)をPRという名前にして、sample5.htmlという名前のhtmlファイルを作成する。
PR=pandas_profiling.ProfileReport(df_all)
PR.to_file("sample5.html")作成されたhtmlファイルを開くと、↓のような画面が現れる。
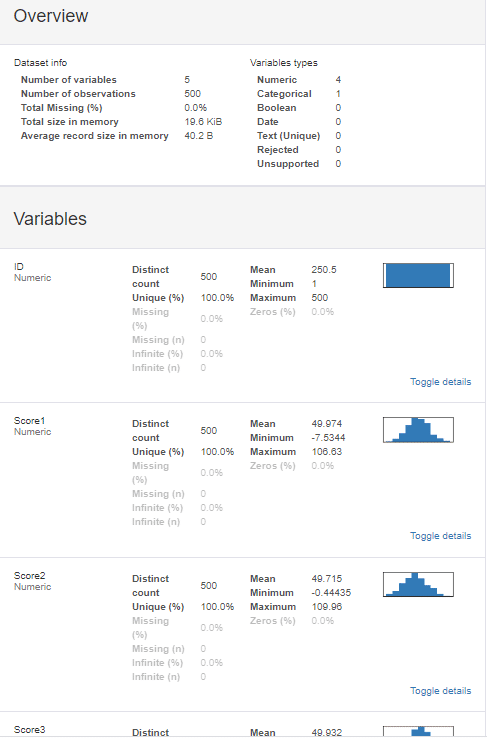
まずは、Score1のところを見てみると、データ数、平均値、最大値、最小値が表示されているのが分かる。数字の横には親切にもヒストグラムまで描かれている。これらのデータを抽出するには何行かのコードを書かないといけないところが、Profiling Reportならばたった一行でできる。今回は欠損値がないのでMissingは0%だけど、実際扱うデータには欠損値が含まれていることがあるので、その検出にも助かる。
もっと詳しく見てみるには、Toggle detailsというボタンをクリックする。クリックしてみると、
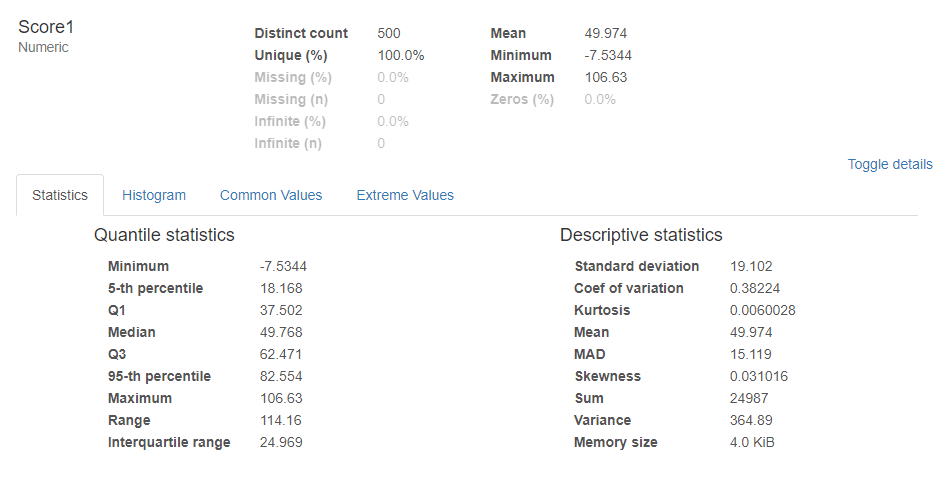
Statisticsの箇所には、分位数(Quantile)が記載された統計量と標準偏差などの記述統計量(Descriptive)が表示されている。
Histogramのボタンを押せば、ヒストグラムが表示される。

Extreme Valueには、外れ値に成りえるデータが示されている。

次に性別のデータを見てみる。性別が記載されたSex2の箇所のToggle detailsを見てみると↓のように表示される。
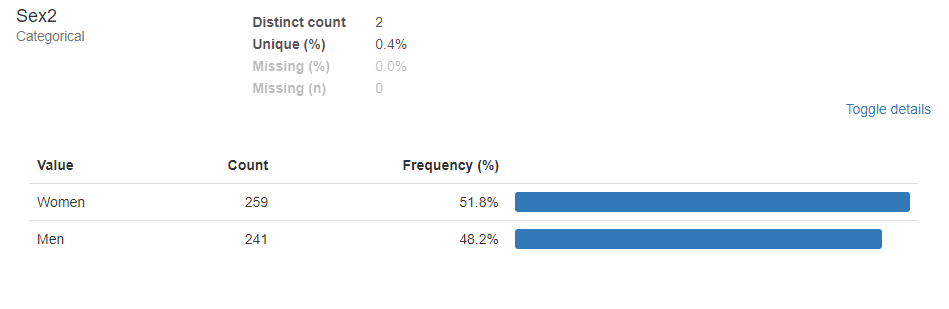
今回ランダムに作成した性別のデータには女性が259名、男性が241名含まれており、それぞれ全体の51.8%と48.2%であることが分かる。
このProfiling Reportには各データの統計量とヒストグラムだけでなく、データ同士の相関関係も表示してくれている。相関関係はピアソンとスピアマンが示されている。
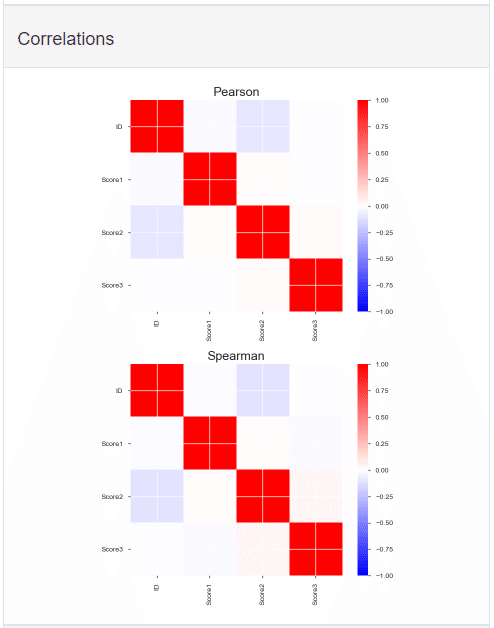
相関図を見てみると、Score1、Score2、Score3においては強い相関関係は認められないようだ。
pandas_profiling.ProfileReport(”データフレーム名")とい一行だけでこれだけの情報量が出力される。
データを扱う上でこれはかなり便利な機能。
3. 今日使った(重要な)コードのまとめ
import pandas as pd
import pandas_profiling
pandas_profiling.ProfileReport(df_all)4. 参考資料・文献
参考資料・文献
1. Pythonではじめる Kaggleスタートブック 講談社
2. 【Pythonメモ】pandas-profilingが探索的データ解析にめちゃめちゃ便利だった件
https://qiita.com/h_kobayashi1125/items/02039e57a656abe8c48f
3. pandas.DataFrameの行・列を指定して削除するdrop
https://note.nkmk.me/python-pandas-drop/
4. pandas-profilingで探索的データ分析
https://analytics-note.xyz/programming/pandas-profiling-eda/
5.【便利!】pandas-profiling(Python)による簡易データ解析
https://qiita.com/ryo111/items/705347799a984acd5d08
と今日はこんな感じ。