
JSアルゴリズム入門1. アナグラム

JavaScriptでアルゴリズムについてやっていくプログラミング入門です。
cyber-dojo というオンラインペアプログラミング・TDDをするサイトがあります。このサイトでは様々な言語とテストフレームワークを使い、お題を解きます。
もともとはオンラインモブプロをお試しでやったときに、題材として面白かったので、ここにまとめなおします。
アナグラム
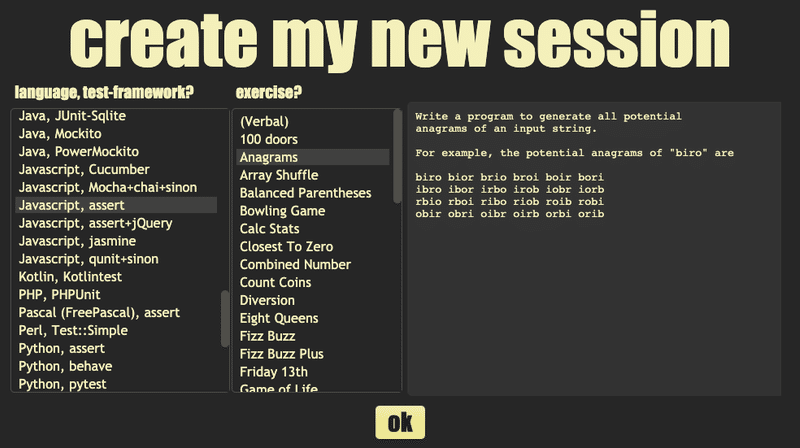
Write a program to generate all potential
anagrams of an input string.
For example, the potential anagrams of "biro" are
biro bior brio broi boir bori
ibro ibor irbo irob iobr iorb
rbio rboi ribo riob roib robi
obir obri oibr oirb orbi orib
与えられた文字列の順番を入れ替えたいわゆるアナグラムを作れというお題です。
考え方
このサンプルであれば "b" と "i" と "r" と "o" という4文字があり、それを先頭に持ってきたあと、"b" が先頭ならば、残りの文字は必ず "i" "r" "o" のどれかがきます。次の文字が "i" ならその次は "r" か "o" で、最後は使われなかった文字ということになります。
つまり、4 × 3 × 2 × 1 で 24 通りの組み合わせがあります。こういう問題の場合、だいたいループ処理でいけそうだと推測できると思います。
const firstLetters = ['b', 'i', 'r', 'o']
for (let i = 0; i < firstLetters.length; i++) {
console.log(firstLetter[i])
}1文字目はこのように取り出せるはずです。2文字目を取り出すためには、1文字目で使わなかった文字の配列を作成し、同じようにループを回せば良いのです。
const secondLetters = ['i', 'r', 'o']
for (let i = 0; i < secondLetters.length; i++) {
console.log(letter[i])
}ループ処理自体は全く違いはなく、単に与える配列に違いがあるだけですね。
思いつく限り一番愚直な実装方法は以下のような4重ループでしょうか。
const letters = [ 'b', 'i', 'r', 'o']
const answers = []
for (let i = 0; i < 4; i++) {
for (let j = 0 ; j < 4; j++) {
for (let k = 0 ; k < 4; k++) {
for (let l = 0; l < 4; l++) {
if (i === j || i === k || j === k ||
i === l || j === l || k === l) {
// 文字がかぶるので処理をすっ飛ばす
continue
}
answers.push(letters[i] + letters[j] + letters[k] + letters[l])
}
}
}
}このような簡単なやり方でも、文字数が4文字であると決め打ちしていいなら実装が出来ました。
これをより汎用的にするのであればどうすればいいでしょうか?
まず、使った文字を消すという処理、たとえば、[b, i, r, o] の b を使えば [i, r, o]が帰ってくる関数があれば話は簡単になります。
const removeLettter = (letters, ch) => {
const index = letters.findIndex(letter => letter === ch)
return [
...letters.slice(0, index),
...letters.slice(index + 1)
}
//別バージョン
const removeLetter = (letters, ch) => {
const index = letters.findIndex(letter => letter === ch)
const copyed = [...letters]
copyed.splice(index, 1)
return copyed
}処理としては前者の方がわかりやすいかもしれません。後者で使っているArray.splice関数は破壊的な動作をするため、使い勝手はよくありません。
それではこの関数と4重ループであれば以下のような実装になります。
const removeLetter = (letters, ch) => {
const index = letters.findIndex(letter => letter === ch)
return [
...letters.slice(0, index),
...letters.slice(index + 1)
]
}
const letters = ['b', 'i', 'r', 'o']
const answers = []
for (let i = 0; i < letters.length; i++) {
const secondLetters = removeLetter(letters, letters[i])
for (let j = 0 ; j < secondLetters.length; j++) {
const thirdLetters = removeLetter(secondLetters, secondLetters[j])
for (let k = 0 ; k < thirdLetters.length; k++) {
const fourthLetters = removeLetter(thirdLetters, thirdLetters[k])
answers.push(letters[i] + secondLetters[j] + thirdLetters[k] + fourthLetters[0])
}
}
}ほんの少しだけすっきりしたものの、まだ4文字という決め打ちを解消出来ていません。これを解決するやり方には主に二種類あります。
・ 関数の再帰呼び出し
・ スタックやキューを使う
スタックやキューを使う
スタックは FILO/LIFO、キューはFIFOのデータ構造のことですが、ぶっちゃけ今回の用途であれば、FIFOでもFILOでもLIFOでも処理は変わりません。
まず push / pop (つまりスタック)を使ってみます。
const removeLetter = (letters, ch) => {
const index = letters.findIndex(letter => letter === ch)
return [
...letters.slice(0, index),
...letters.slice(index + 1)
]
}
const letters = ['b', 'i', 'r', 'o']
const queue = [[letters, []]]
const answers = []
let counter = 0
while (queue.length > 0) {
const [notFixed, fixed] = queue.pop()
console.log(notFixed, fixed)
if (notFixed.length === 0) {
const answer = fixed.join('')
answers.push(answer)
console.log(' -> answer:', answer)
} else {
notFixed.forEach(letter => queue.push([removeLetter(notFixed, letter), [...fixed, letter]]))
}
}
考え方としては、キューには、まだ固定してない文字群 notFixed と、固定した文字群 fixed という二要素のタプル(配列)をぶちこみます。
たとえば、一番最初の時点では、固定してない文字群は [b, i, r, o] で、固定した文字はまだないため [] というタプルがキューに入ります。
最初にキューから取り出すと、それは、先程入れたばかりの [ ['b', 'i', 'r', 'o'], [] ] です。ループの中では、未確定文字群でさらにループ (forEachメソッド)を実行し、取り出した未確定文字を、確定済みの文字へ移動させます。
[ 'b', 'i', 'r', 'o' ] []
[ 'b', 'i', 'r' ] [ 'o' ]
[ 'b', 'i' ] [ 'o', 'r' ]
[ 'b' ] [ 'o', 'r', 'i' ]
[] [ 'o', 'r', 'i', 'b' ]
-> answer: orib
[ 'i' ] [ 'o', 'r', 'b' ]
[] [ 'o', 'r', 'b', 'i' ]
-> answer: orbi
[ 'b', 'r' ] [ 'o', 'i' ]
[ 'b' ] [ 'o', 'i', 'r' ]
[] [ 'o', 'i', 'r', 'b' ]
-> answer: oirb
[ 'r' ] [ 'o', 'i', 'b' ]
[] [ 'o', 'i', 'b', 'r' ]
-> answer: oibr
[ 'i', 'r' ] [ 'o', 'b' ]
[ 'i' ] [ 'o', 'b', 'r' ]
[] [ 'o', 'b', 'r', 'i' ]
-> answer: obri
[ 'r' ] [ 'o', 'b', 'i' ]
[] [ 'o', 'b', 'i', 'r' ]
-> answer: obir
[ 'b', 'i', 'o' ] [ 'r' ]
[ 'b', 'i' ] [ 'r', 'o' ]
[ 'b' ] [ 'r', 'o', 'i' ]
[] [ 'r', 'o', 'i', 'b' ]
-> answer: roib
[ 'i' ] [ 'r', 'o', 'b' ]
[] [ 'r', 'o', 'b', 'i' ]
-> answer: robi
[ 'b', 'o' ] [ 'r', 'i' ]
[ 'b' ] [ 'r', 'i', 'o' ]
[] [ 'r', 'i', 'o', 'b' ]
-> answer: riob
[ 'o' ] [ 'r', 'i', 'b' ]
[] [ 'r', 'i', 'b', 'o' ]
-> answer: ribo
[ 'i', 'o' ] [ 'r', 'b' ]
[ 'i' ] [ 'r', 'b', 'o' ]
[] [ 'r', 'b', 'o', 'i' ]
-> answer: rboi
[ 'o' ] [ 'r', 'b', 'i' ]
[] [ 'r', 'b', 'i', 'o' ]
-> answer: rbio
[ 'b', 'r', 'o' ] [ 'i' ]
[ 'b', 'r' ] [ 'i', 'o' ]
[ 'b' ] [ 'i', 'o', 'r' ]
[] [ 'i', 'o', 'r', 'b' ]
-> answer: iorb
[ 'r' ] [ 'i', 'o', 'b' ]
[] [ 'i', 'o', 'b', 'r' ]
-> answer: iobr
[ 'b', 'o' ] [ 'i', 'r' ]
[ 'b' ] [ 'i', 'r', 'o' ]
[] [ 'i', 'r', 'o', 'b' ]
-> answer: irob
[ 'o' ] [ 'i', 'r', 'b' ]
[] [ 'i', 'r', 'b', 'o' ]
-> answer: irbo
[ 'r', 'o' ] [ 'i', 'b' ]
[ 'r' ] [ 'i', 'b', 'o' ]
[] [ 'i', 'b', 'o', 'r' ]
-> answer: ibor
[ 'o' ] [ 'i', 'b', 'r' ]
[] [ 'i', 'b', 'r', 'o' ]
-> answer: ibro
[ 'i', 'r', 'o' ] [ 'b' ]
[ 'i', 'r' ] [ 'b', 'o' ]
[ 'i' ] [ 'b', 'o', 'r' ]
[] [ 'b', 'o', 'r', 'i' ]
-> answer: bori
[ 'r' ] [ 'b', 'o', 'i' ]
[] [ 'b', 'o', 'i', 'r' ]
-> answer: boir
[ 'i', 'o' ] [ 'b', 'r' ]
[ 'i' ] [ 'b', 'r', 'o' ]
[] [ 'b', 'r', 'o', 'i' ]
-> answer: broi
[ 'o' ] [ 'b', 'r', 'i' ]
[] [ 'b', 'r', 'i', 'o' ]
-> answer: brio
[ 'r', 'o' ] [ 'b', 'i' ]
[ 'r' ] [ 'b', 'i', 'o' ]
[] [ 'b', 'i', 'o', 'r' ]
-> answer: bior
[ 'o' ] [ 'b', 'i', 'r' ]
[] [ 'b', 'i', 'r', 'o' ]
-> answer: biro次に push / unshift (FILO) を使ってみます
const removeLetter = (letters, ch) => {
const index = letters.findIndex(letter => letter === ch)
return [
...letters.slice(0, index),
...letters.slice(index + 1)
]
}
const letters = ['b', 'i', 'r', 'o']
const queue = [[letters, []]]
const answers = []
let counter = 0
while (queue.length > 0) {
const [notFixed, fixed] = queue.shift()
console.log(notFixed, fixed)
if (notFixed.length === 0) {
const answer = fixed.join('')
answers.push(answer)
console.log(' -> answer:', answer)
} else {
notFixed.forEach(letter => queue.push([removeLetter(notFixed, letter), [...fixed, letter]]))
}
}こちらは、少しわかりやすい順番で処理されます。
[ 'b', 'i', 'r', 'o' ] []
[ 'i', 'r', 'o' ] [ 'b' ]
[ 'b', 'r', 'o' ] [ 'i' ]
[ 'b', 'i', 'o' ] [ 'r' ]
[ 'b', 'i', 'r' ] [ 'o' ]
[ 'r', 'o' ] [ 'b', 'i' ]
[ 'i', 'o' ] [ 'b', 'r' ]
[ 'i', 'r' ] [ 'b', 'o' ]
[ 'r', 'o' ] [ 'i', 'b' ]
[ 'b', 'o' ] [ 'i', 'r' ]
[ 'b', 'r' ] [ 'i', 'o' ]
[ 'i', 'o' ] [ 'r', 'b' ]
[ 'b', 'o' ] [ 'r', 'i' ]
[ 'b', 'i' ] [ 'r', 'o' ]
[ 'i', 'r' ] [ 'o', 'b' ]
[ 'b', 'r' ] [ 'o', 'i' ]
[ 'b', 'i' ] [ 'o', 'r' ]
[ 'o' ] [ 'b', 'i', 'r' ]
[ 'r' ] [ 'b', 'i', 'o' ]
[ 'o' ] [ 'b', 'r', 'i' ]
[ 'i' ] [ 'b', 'r', 'o' ]
[ 'r' ] [ 'b', 'o', 'i' ]
[ 'i' ] [ 'b', 'o', 'r' ]
[ 'o' ] [ 'i', 'b', 'r' ]
[ 'r' ] [ 'i', 'b', 'o' ]
[ 'o' ] [ 'i', 'r', 'b' ]
[ 'b' ] [ 'i', 'r', 'o' ]
[ 'r' ] [ 'i', 'o', 'b' ]
[ 'b' ] [ 'i', 'o', 'r' ]
[ 'o' ] [ 'r', 'b', 'i' ]
[ 'i' ] [ 'r', 'b', 'o' ]
[ 'o' ] [ 'r', 'i', 'b' ]
[ 'b' ] [ 'r', 'i', 'o' ]
[ 'i' ] [ 'r', 'o', 'b' ]
[ 'b' ] [ 'r', 'o', 'i' ]
[ 'r' ] [ 'o', 'b', 'i' ]
[ 'i' ] [ 'o', 'b', 'r' ]
[ 'r' ] [ 'o', 'i', 'b' ]
[ 'b' ] [ 'o', 'i', 'r' ]
[ 'i' ] [ 'o', 'r', 'b' ]
[ 'b' ] [ 'o', 'r', 'i' ]
[] [ 'b', 'i', 'r', 'o' ]
-> answer: biro
[] [ 'b', 'i', 'o', 'r' ]
-> answer: bior
[] [ 'b', 'r', 'i', 'o' ]
-> answer: brio
[] [ 'b', 'r', 'o', 'i' ]
-> answer: broi
[] [ 'b', 'o', 'i', 'r' ]
-> answer: boir
[] [ 'b', 'o', 'r', 'i' ]
-> answer: bori
[] [ 'i', 'b', 'r', 'o' ]
-> answer: ibro
[] [ 'i', 'b', 'o', 'r' ]
-> answer: ibor
[] [ 'i', 'r', 'b', 'o' ]
-> answer: irbo
[] [ 'i', 'r', 'o', 'b' ]
-> answer: irob
[] [ 'i', 'o', 'b', 'r' ]
-> answer: iobr
[] [ 'i', 'o', 'r', 'b' ]
-> answer: iorb
[] [ 'r', 'b', 'i', 'o' ]
-> answer: rbio
[] [ 'r', 'b', 'o', 'i' ]
-> answer: rboi
[] [ 'r', 'i', 'b', 'o' ]
-> answer: ribo
[] [ 'r', 'i', 'o', 'b' ]
-> answer: riob
[] [ 'r', 'o', 'b', 'i' ]
-> answer: robi
[] [ 'r', 'o', 'i', 'b' ]
-> answer: roib
[] [ 'o', 'b', 'i', 'r' ]
-> answer: obir
[] [ 'o', 'b', 'r', 'i' ]
-> answer: obri
[] [ 'o', 'i', 'b', 'r' ]
-> answer: oibr
[] [ 'o', 'i', 'r', 'b' ]
-> answer: oirb
[] [ 'o', 'r', 'b', 'i' ]
-> answer: orbi
[] [ 'o', 'r', 'i', 'b' ]
-> answer: oribいかがでしょうか?未確定文字から一文字ずつ確定文字へ移動している様がわかりやすいと思います。
関数の再帰呼び出し
ある関数から自分を呼び出すことを再帰呼び出しといいます。ややこしいものの中には、別の関数を経由して再帰呼び出しをすることもあります。
const removeLetter = (letters, ch) => {
const index = letters.findIndex(letter => letter === ch)
return [
...letters.slice(0, index),
...letters.slice(index + 1)
]
}
const getAnagrams = (letters) => {
if (letters.length === 0) {
return ['']
}
const res = []
letters.forEach(letter => {
getAnagrams(removeLetter(letters, letter)).forEach(fixed => {
res.push(letter + fixed)
})
})
console.log('result:', res)
return res
}
// getAnagrams(['b', 'i', 'r', 'o'])
getAnagrams('biro'.split(''))再帰呼び出しの場合、一番最後の文字から順に確定してくことになります。
result: [ 'o' ]
result: [ 'r' ]
result: [ 'ro', 'or' ]
result: [ 'o' ]
result: [ 'i' ]
result: [ 'io', 'oi' ]
result: [ 'r' ]
result: [ 'i' ]
result: [ 'ir', 'ri' ]
result: [ 'iro', 'ior', 'rio', 'roi', 'oir', 'ori' ]
result: [ 'o' ]
result: [ 'r' ]
result: [ 'ro', 'or' ]
result: [ 'o' ]
result: [ 'b' ]
result: [ 'bo', 'ob' ]
result: [ 'r' ]
result: [ 'b' ]
result: [ 'br', 'rb' ]
result: [ 'bro', 'bor', 'rbo', 'rob', 'obr', 'orb' ]
result: [ 'o' ]
result: [ 'i' ]
result: [ 'io', 'oi' ]
result: [ 'o' ]
result: [ 'b' ]
result: [ 'bo', 'ob' ]
result: [ 'i' ]
result: [ 'b' ]
result: [ 'bi', 'ib' ]
result: [ 'bio', 'boi', 'ibo', 'iob', 'obi', 'oib' ]
result: [ 'r' ]
result: [ 'i' ]
result: [ 'ir', 'ri' ]
result: [ 'r' ]
result: [ 'b' ]
result: [ 'br', 'rb' ]
result: [ 'i' ]
result: [ 'b' ]
result: [ 'bi', 'ib' ]
result: [ 'bir', 'bri', 'ibr', 'irb', 'rbi', 'rib' ]
result: [ 'biro',
'bior',
'brio',
'broi',
'boir',
'bori',
'ibro',
'ibor',
'irbo',
'irob',
'iobr',
'iorb',
'rbio',
'rboi',
'ribo',
'riob',
'robi',
'roib',
'obir',
'obri',
'oibr',
'oirb',
'orbi',
'orib' ]注意点
再帰呼び出しの場合、末尾再帰ではないので、文字数が増えるとメモリ使用量などが爆裂する恐れがあります。スタック・キューを使うのが素直でしょう。
コードを見ても、多分スタック・キューで書いたやつの方がわかりやすいと思います。
あと、アルゴリズムについての記事だったため、cyber-dojo的なテストプログラムや、関数の仕様については触れていません。
この記事が気に入ったらサポートをしてみませんか?