Pythonで便利なラムダ関数を使ってみよう

原題:"What are Lambda Functions? A Quick Guide to Lambda Functions in Python"
原文は以下より:
ラムダ関数ってそういえば大学のプログラミングの授業でやったなー、とふと思い出した。当時はいまいち使いどころがわからないというか、確かに動いたけどわかったようなわからないような?って狐につままれたまま終わったのだけど、今回上記の記事内容をひととおり読破してもなおやっぱり狐につままれたままである。とりあえずアウトプットしてみたら多少は身につくかも、ということで記事内容を以下にざっくり紹介していく:
はじめに
forループってPythonに限らずどのプログラミング言語でも絶対習うし必要なものだと思うけど、面倒だしめっちゃ処理遅くなりがち。かといって代わりになるものがあるかっていうと、ラムダ関数ってのがある。
ラムダ関数を使うと、Pythonコードがすっきりして機械学習も速くできる。でもラムダ関数って、特に初心者には理解しづらいと思うし自分もそうだったけど、一旦理解したらとても簡単で強力。なのでこの記事で、どんな風に役立つのか、どうやって使うのかをぜひ知ってもらいたい。
ラムダ関数ってなに?
ラムダ関数とは、単一の式を含む小さな関数である。ラムダ関数は、名前を持たない無名関数として振る舞う関数でもある。このことは、短いコードで小さな処理を行いたいときに非常に役に立つ。
なるほどわからん。
ラムダ関数自体は、様々なプログラミング言語で導入されている概念である(そもそも提唱されたのが1930年代らしい)が、ここではPythonにおけるラムダ関数の使用方法にフォーカスしたい。
Pythonにおけるラムダ関数の文法は、以下のようになる:

Keywordは、lambdaと記述することが決まっているので、ここは変えられない。
Bound Variable(束縛変数、要は関数に与える引数)とBody(関数の処理内容)については、任意に与えることができる。
通常のdef構文を使った関数と比較しながら、ラムダ関数の特徴を見ていこう。
ラムダ関数と通常関数の比較
# ラムダ関数
lambda x: x+3
# 通常の関数
def add3(x):
return x+3ラムダ関数はキーワードlambdaによって定義され、引数はいくつでも与えられるが処理は一文のみである。返り値は関数オブジェクトとなり、これを変数に代入することもできる。
defを使用した通常の関数は、ご存知の通り引数も処理も好きなだけ記述でき、一般的にはより大きな処理ブロックを作成したい場合に用いる。
※関数オブジェクトで返ってくるというのが少しとっつきにくいけど、以下のようにしてみると確かに変数に関数オブジェクトが代入されていることが実感できる:
>>> spam = lambda x: x+3
>>> spam(1)
4ラムダ関数を使ったIIFE
IIFEとはImmediately Invoked Function Expressionsのことで、要は記述したその場ですぐ実行される関数記述のこと。Pythonのラムダ関数の動作を一番手っ取り早く確認するため、以下のようにしてラムダ関数を用いたIIFEを書いてみよう:
>>> (lambda x: x*x*x)(10)
1000やったぜ!
様々な関数とともにラムダ関数を使おう
IIFEだけだといまいちラムダ関数の効果を実感しにくいので、色々やってみる。原文ではJupyter NotebookとPandasを使用しているようだけど、面倒なのでここではPandasのみ使う。
といってもまずPandasが未インストールだったので、ターミナルで以下コマンド実行してインストール:
$ pip3 install pandas※ここから先は、Pandasの使い方がわかっていないとよくわからないかもしれない。私もPandas未経験なのでよくわからんがとりあえず手順通りに進めていく。
今回いろいろ操作をしていくDataFrameを定義する:
>>> df=pd.DataFrame({
... 'id':[1,2,3,4,5],
... 'name':['Jeremy', 'Frank', 'Janet', 'Ryan', 'Mary'],
... 'age':[20,25,15,10,30],
... 'income':[4000,7000,200,0,10000]
... })>>> df
id name age income
0 1 Jeremy 20 4000
1 2 Frank 25 7000
2 3 Janet 15 200
3 4 Ryan 10 0
4 5 Mary 30 10000名前と年齢と収入のデータベースらしい。
apply()でラムダ関数を使おう
例えば上記データには実は誤りがあって、年齢が全て実際よりも3低くなっているとする。この場合、正しいデータに修正するには上記データフレームのageすべてに3を足さなくてはならないが、こういった処理をPandasのapply()関数とラムダ関数を用いることで実現できる:
>>> df['age'] = df.apply(lambda x: x['age']+3, axis=1)
適用後:
>>> df
id name age income
0 1 Jeremy 23 4000
1 2 Frank 28 7000
2 3 Janet 18 200
3 4 Ryan 13 0
4 5 Mary 33 10000apply()関数は、データフレームの行・列の各方向にラムダ関数による処理を適用するものである。axis=1とすることで、行方向に適用していくように指定している。
同じ処理は、以下のようにPandas seriesに直接適用する形式でも可能。(こっちの方が個人的にはわかりやすい)
df['age'] = df['age'].apply(lambda x: x+3)filter()でラムダ関数を使おう
18歳より高い年齢のみをリストアップしたい、というときにはfilter()関数とラムダ関数を使おう。ラムダ関数がTrueかFalseを返すようにしてfilter()に与えれば実現できる:
>>> list(filter(lambda x: x>18, df['age']))
[23, 28, 33]Trueとなった要素のみがリストに反映されるので、必然的にフィルタ適用前の要素数以下の大きさのリストが返ってくる。
map()でラムダ関数を使おう
全員の収入を20%上げたいとする(やったぜ)。つまり、データフレーム内のすべてのincomeをそれぞれ20%大きな値に変更する。こういった処理はmap()関数とラムダ関数によって実現できる:
>>> df['income'] = list(map(lambda x: int(x+x*0.2), df['income']))>>> df['income']
0 4800
1 8400
2 240
3 0
4 12000
※なお同じ処理がapply()でもできるんでは、と思ってやってみたらやっぱりできた:
>>> df['income'] = df['income'].apply(lambda x: int(x + 0.2*x))reduce()でラムダ関数を使おう
全員の収入の合計値を求めたいときに、reduce()関数とラムダ関数を使って以下のようにできる:
(reduce()関数はfunctoolモジュールに含まれるため先にimportしておく必要がある)
>>> import functools
>>> functools.reduce(lambda a,b: a+b, df['income'])
25440reduce()関数は、与えられたシーケンスの先頭2つに対してラムダ関数の内容をまず適用して、この得られた結果とシーケンスの次の値に対して同じくラムダ関数を適用し、また得られた結果と次の値を・・・という処理をするものらしい。使いこなせる気がしない。
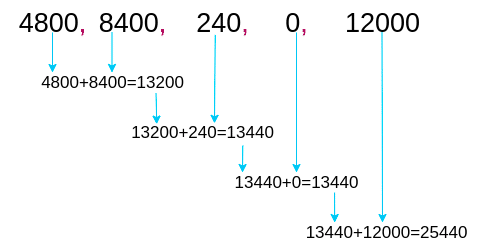
なお列の合計値を求めるならPandasでできるんじゃないの?と思って調べたらsum()関数でできた:
>>> df['income'].sum()
25440
ますますreduce()関数の使いどころがわからない。
ラムダ関数を用いた条件分岐
if & elseのような条件分岐もラムダ関数で使うことができる。例えば先ほどのデータフレームで、年齢が18歳以上だったら'Adult'、そうでなければ'Child'とする新たなデータ列を追加したい場合、以下のようにすれば良い:
>>> df['category']=df['age'].apply(lambda x: 'Adult' if x>=18 else 'Child')>>> df
id name age income category
0 1 Jeremy 23 4800 Adult
1 2 Frank 28 8400 Adult
2 3 Janet 18 240 Adult
3 4 Ryan 13 0 Child
4 5 Mary 33 12000 Adultまとめ
ここにちょっと簡単な関数式欲しいな、でもdef使うほどの内容じゃないし・・・というときにはlambdaを使うと良いのですかね。
少し補足というか余談として、自分のようなPandas初心者はすごく混乱したのだけど、filter()やmap()はPandasの関数ではなくPythonの一般関数なのね?(apply()はPandasのDataFrameが持つメソッド)
なので、自分Pandas使わねぇし・・・という場合でも、一般的なリストやタプルの処理にfilter()およびmap() + lambdaが使えるということで、これらはセットで頭に入れときましょう。要は、ラムダ関数はfilter()やmap()と組み合わせて本領を発揮するということ!