
誤解訂正:Leonardo.Ai のImage to Image 処理が無償でも利用出来ると分かったので。

Leonardo.Ai に新設されたImage to Image 処理について、そのメニューの
複雑さから有償契約なしには利用出来ないと思ってしまっていましたが
実は一連の新設機能の中でImage to Image 処理だけは無償利用出来る
と知りました。
先人様が先行されている事例を拝見しながら、そこで動画生成に1日の
回数制限に触れておられた上で、それでもなおかつImage to Image 機能で
他の描画サービスから画像を取り込んでおられるのと拝見して、
「ん?何か違ってる??」とようやく気が付きました。
それで再度オペレーションをじっくり見て行きました。
(このサイトは機能追加の都度、GUI 仕様が建て増し的に複雑に
なって行き過ぎで、今回もそれがあっての誤解となったようです。)
まず画面の左ペイン下方の「Image to Image」ボタンにカブるように
「Show me !」のダイアログがあり、そのボタンを押すと、画面右方に
料金プランの入り口が出て来るのは、以前記事にした訳でしたが…。
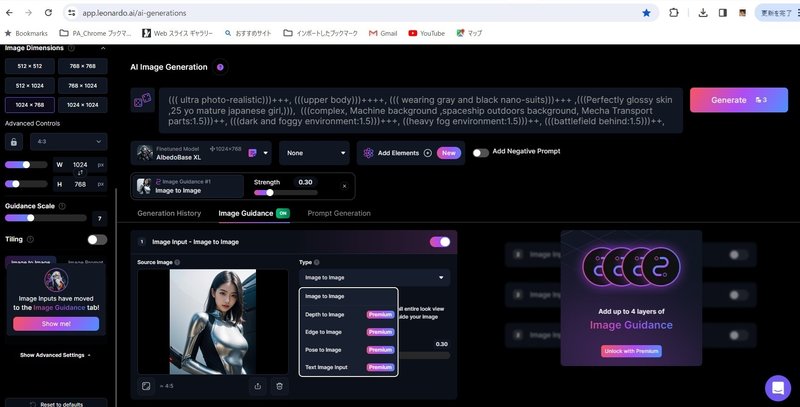
元画像をドラッグ入力した画面の右に処理を選ぶ「Type」を展開すると、
5つの処理メニューの中で、Image to Image だけは「Premium」の
表示がありません。

「じゃあ無償で使えるんじゃないの?」となった訳ですが、どのように
そこから処理をスタートさせるのかが分かりませんでした。
試しに他のCheckPoint での描画と同じく「Generate」を押すと
瞬時に処理が終わり、描画履歴にImage to Image 結果が出ました。
(このあたり本当に建て増し続きでデザインがダンジョン化したGUI
をどこかで整理するべきではないかと思えます。)

その時点でそれまで描画していたCheckPoint ファイル、AlbedoBase XL
のニュアンスが加味されてしまっていましたので、処理の「Strength」
を最大の0.9 まで上げて再度処理しました。

縦横サイズはLeonardo.Ai 側で指定していたために、上下は切れましたが
元画像とほぼ変わらずの画像取り込みが出来ました。

こちらがローカルPC のStable Diffusion Web UI で描画した元画像です。

描画するCheckPoint をLeonardo Diffusion XL に代えても「Strength」
が0.9 の状態では、ほぼ結果変わらずでした。
この処理を3 トークンで可能となれば、事情は大きく変わってきます。
最近ではローカル描画での人物像には遠いが、Leonardo.Ai の人物像
にも慣れて来て、別ものとしてLeonardo.Ai 内で閉じて、静止画生成
と簡易動画生成を楽しもうか、とそろそろ思えてきた矢先でした。
が、こうなると、ローカルでの描画をどんどん取り込んで、その詳細
ニュアンスの減損もない簡易動画を作る専用に Leonardo.Ai を使えば
良いではないか、という先日に一旦断念した目論見が大復活出来る
ことになりました。
Image to Image に3トークン/ 画 を使うので、150 トークン / 日 の
無償範囲では、1日当たりローカル描画8 画をImage to Image 処理で
取り込んで(または5 画を取り込んで残りはLeonardo.Ai で描画)、
各4 秒の5 動画を生成、それで20秒の動画になるので、
最近YouTube で60 秒以下の縦構図動画はショート動画になる仕様
追加があったのを避けるために、3 ~ 4 日分コンテンツを蓄積・編集
をする必要がある、ということになりそうです。
あまりにその作業に遣り甲斐が出るなら、この価値だけで
Leonardo.Ai の有償契約も考えても良いかもしれません。
ただ最低限の有償契約で何の制約が外れるのか、対比表では現時点で
あまり良く分かっていませんでしたので、この機会に深堀りしてみました。

12 ドル / 月 を支払っても(年払いだと10 ドル / 月)月間 8500 トークン。
多いように見えて、およそ平均 274 ~283 トークン / 日 で1 日当たりの
簡易動画生成が6 画から平均で10 ~11 画になる程度か。
(毎日休みなく使ったとして。きっと使うと思う。1 日単位で制限が
かかる訳ではないが、月末にトークンが無くなって寂しいのも、
うーん。微妙…。)
それに動画化といっても、ローカルでの動画生成よりましな仕上がり
とはいえ、あくまで簡易動画なので単純な動きや内容に飽きが来る
ことも想定しておかねばならないでしょう。従来通り、記事中で静止画
をバンバンと次々表示させるほうがインパクトがある場合もあるで
しょうから。
ただ展望は再び大きく変わりました。
ローカルPC でとことん突き詰めた静止画描画のニュアンスを減損する
ことなく動画化出来ることで、「ローカルPC での静止画制作」と
「クラウドでの動画制作」が1つの作業として統一化出来るのです。
正直のところ、先日の一旦断念の状態では、1つの新たなライフワーク
だったものが、2つの別々の作業に分化した感じに落ち着かない気分が
否めませんでした。
留意事項としては、プロンプト入力欄がローカルPC のStable Diffusion
Web UI (AUTOMATIC1111 版)やmage.Space、Tensol.Art に比べて小さく、
記述語の理解の幅が狭いようなので、元画像を描画する時点で、
プロンプトを極力整理しておく必要がありそうです。
与えたプロンプトを使ってtxt2img で描く正解が元画像という関係
(=元画像を描いたプロンプトが入力欄に収まり、解釈エラーが無い
状態)にしておかねば Image to image の「Strength」が0.9 で
あっても、処理後にきっと画に変化が出てしまうでしょうから。
….その後試してみましたが、その点を神経質にならずに済みそうです。
「Strength」が0.9 だとプロンプトからの影響は受けないみたいです。
ローカルPC のNMKD Stable Diffusion GUI ではtxt2img との齟齬は
txt2img が画に影響したように思いましたが…。まあそれはそれで
使い易いとも言えますか。何か成功例のプロンプトが1 つあればそれを
Image to Image 処理で毎回使えば良い訳ですから。
追記:
本話題に関してはLeonardo.Ai のGUI のダンジョン化から来る仕様把握
の困難さもあって、記事内容を何度か訂正していますが、また訂正が
あります。さらに別記事で新たな訂正をかけるのも如何なものか
と考え、この記事内に追記します。
Image to Image 処理に使うCheckPoint ファイルによって、必要トークン数
は違ってくることも後で分かりました。
(上掲の1 日当たりの枚数計算にも影響しますが…。
例えば150 トークン / 日 を動画化5 本に使った後も、残りの25 トークンを
Image To Image 処理と描画に最大25 件振り分け可能です。)
たまたま最近お気に入りのAlbedoBaseXL を設定していた状態で、
Image to Image 処理を試した流れだったのでしたが、それが3 トークン
必要だった、ということで、例えば1 トークンしか使わない
Absolute Reality V16 を使っても処理は実行出来ました。
ただ、微細な部分を比べますと、やはり3 トークン必要なAlbedoBaseXL
のほうが精緻な再現があるようです。描画対象によってうまく使い分け
したいものです。(下記はどちらも処理の「Strength」は最大の0.9 )
こちらが3 トークン必要なAlbedoBaseXL でのローカルPC での木星カリスト
情景の Image to Image 処理結果です。

こちらが1 トークン必要なAbsolute Reality V16 でのローカルPC での
木星カリスト情景の Image to Image 処理結果です。

木星の雲の渦巻き内部の質感にも若干の差がありますが、カリストの
都市の塔先端のシャープさには、より目立った差があります。
しかしそれらが動画化された後、対象が動くことを考えますと、その差
を無視できるかどうかは描く対象によって違って来そうです。
今はトークン節約のために不要なテストでの動画化はしませんが、当面は
1 トークン使っての Image to Image 処理で充分かと考えています。
動画化の際に微細な描写が気になるようであれば、その時点でその元画像
に対して、3 トークンと使ったImage to Image 処理を追加すれば良いか
と考えます。
ご覧いただきありがとうございます。
この記事が気に入ったらサポートをしてみませんか?