
Stable DiffusionとDALL-Eの比較

※アイキャッチ画像は「Stable Diffusion」で自動生成しました。
はじめに
テキストから画像を生成するStable Diffusionがリリースされました。
絵を描くのが苦手な人でも、「こういう絵がほしい」というのを文章にすると、自動的にAIが絵を描いてくれます。
僕はアイキャッチ画像とか用意するのが苦手なので、これで画像を探す手間が不要になりそうです。
そのうちフリー画像サイトと競合してくるかもしれませんね。
先にリリースされたDALL-Eも同じくテキストから画像が生成できますが、Stable DiffusionとDALL-Eの結果を比較してみました。
参考(実行手順)
実行するまでの手順は以下にまとめました。
内容は多少重複しますが、noteのほうは実行手順は省略して結果と考察を中心に記載します。
※以下の手順はローカルのPCで実行しています。
結果
まず1つ目の比較です。
お題は以下の文章をStable DiffusionとDALL-Eに入力した結果の画像を比較します。
お題①
プロンプト: 「ピカチュウが川で釣りをしている北斎の絵。背景には富士山と東京タワーが見える夏の夕方。」
Stable Diffusion

たしかにピカチュウです。
釣りをしているかどうかは微妙ですが、長い竿のようなものを持っています。
画風も葛飾北斎っぽくなりました。
ただ、東京タワーと富士山は残念ながら省略されてしまったようです。
いっぽうDALL-Eだと以下のようになります。
DALL-E

Stable Diffusionと違ってDALL-Eのほうはピカチュウは残念な感じになりました。
でも、DALL-Eのほうが富士山と東京タワーは指示内容をくみ取って描画されていました。
このあたりはプロンプト(指示)内容によると思いますが、比較的短い文章でもDALL-Eのほうが指示の単語を正確にとらえて描画しているように感じます。
次のお題にいきましょう。
お題②
プロンプト: 「フラットでシンプルデザインのピカチュウがテニスをしているアイコン」
Flat and simple design Pikachu playing tennis icon
Stable Diffusion

これもたしかにピカチュウです。
でもテニスはしていません。
またもやStable Diffusionは指示に従ってくれないようです。
仮に指示内容を知らずにこの絵を見ただけであれば、よくできた絵に見えますね。
DALL-E
いっぽう同じ文章をDALL-Eで実行した絵は以下になります。
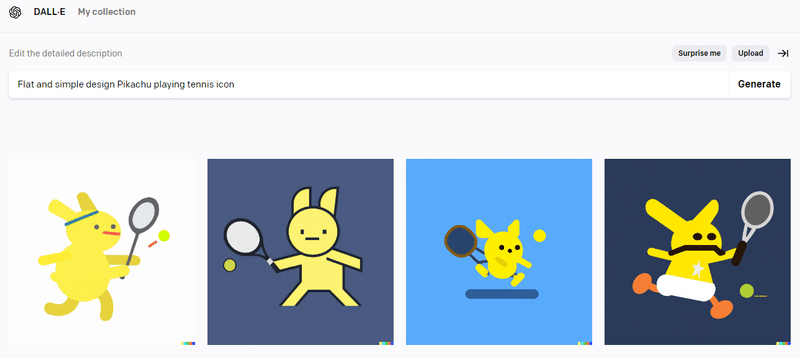
ピカチュウかというと残念な感じになりましたが、「フラットデザイン」、「シンプル」、「テニス」という指示内容は忠実に再現して描画してくれていいます。
もしかしたらDALL-Eはピカチュウをわかってない疑惑が出てきたので、試しに以下のプロンプトをDALL-Eで実行してみました。
プロンプト: 「スーパーサイヤ人になったピカチュウ」
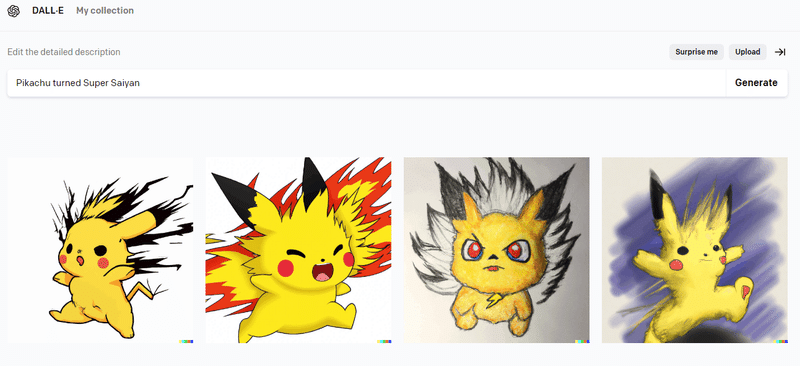
DALL-Eでもちゃんとしたピカチュウが出てきました。
DALL-Eがピカチュウをわかってないというわけではなさそうですね。
次のお題にいきましょう。
お題③
プロンプト: 「任天堂のマリオのフラットデザイン」
Stable Diffusion
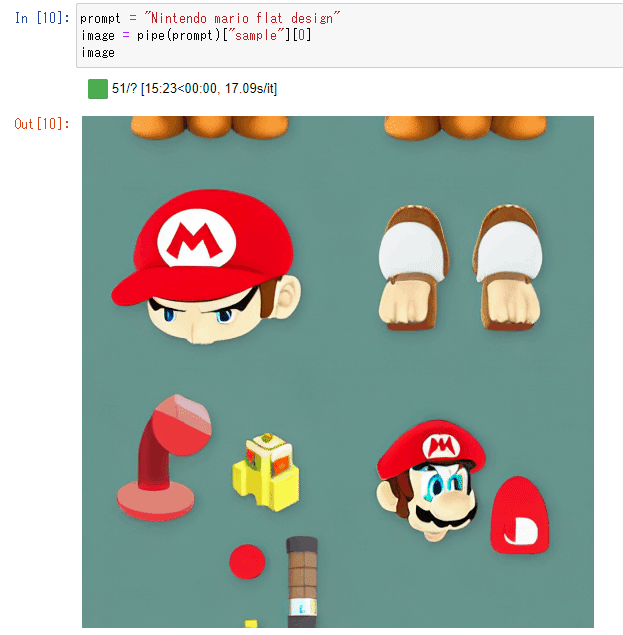
いちおうマリオにはなりましたが、マリオ以外のイラストは何なのかよくわかりません・・・
DALL-E
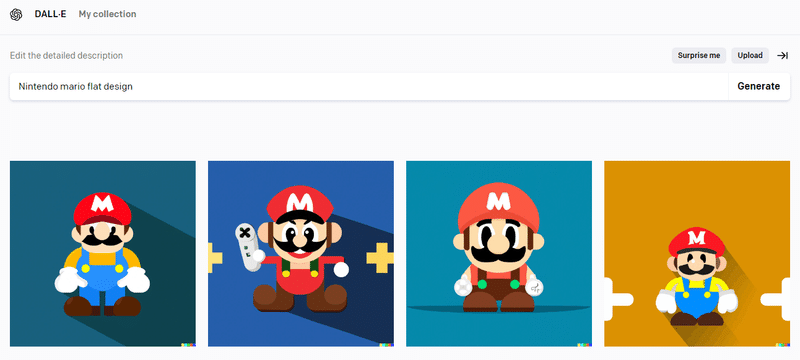
これはいいですね。すぐにでも商品のデザインで使えそうなイメージが出てきました。
「フラットデザイン」を忠実に再現してくれているようです。
次のお題にいきましょう。
お題④
プロンプト: 「ピカチュウがサッカーをしているピカソ風の水彩画」
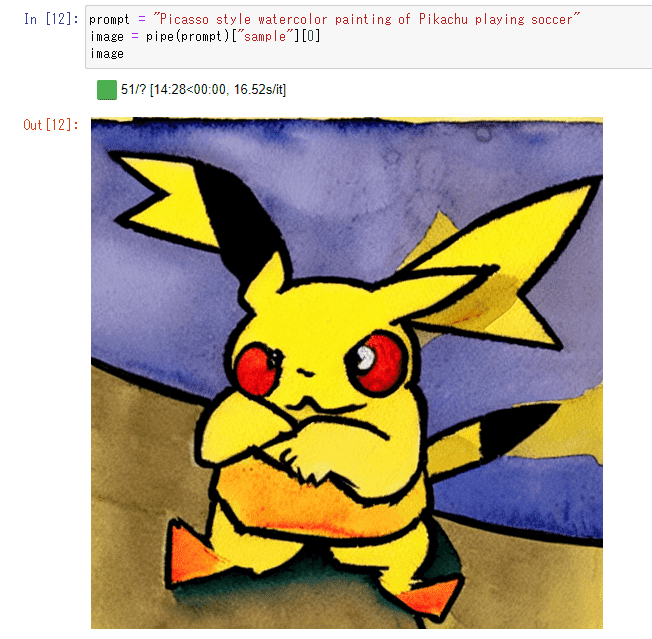
これもたしかにピカチュウです。ピカソが入ってるかは微妙ですが、ピカソ風になるようにがんばった結果かもしれません。
でもサッカーはしてません。
やはり、Stable Diffusionは指示内容を無視して、「ピカチュウ」のようにメジャーなものに注力してしまうような感じはしますね。
DALL-E

ピカチュウっぽさはだいぶ無くなりましたが、ちゃんとサッカーはしています。水彩画という指示も再現してくれていますね。
お題➄
プロンプト: 「トラの葛飾北斎風のフラットデザイン」
Stable Diffusion

もはやトラではなくなってしまいました。
これはこれでイラストとしてはアリかもしれません。
画風は北斎というキーワードから日本画のようなものをイメージしてそうです。
DALL-E
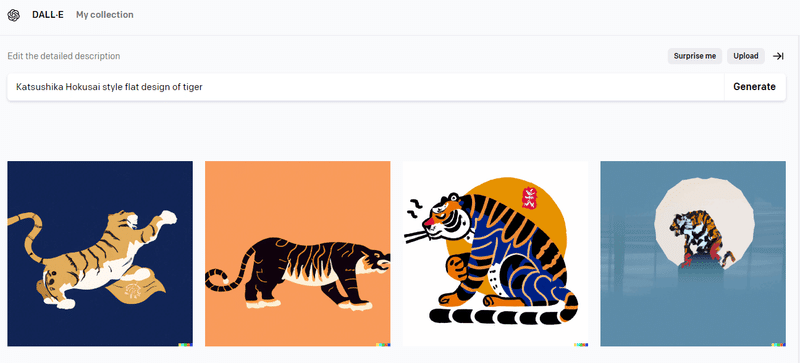
DALL-Eのほうは「トラ」、「フラットデザイン」とか意識できているようです。
北斎というよりは年賀状でそのまま使えそうなイラストが出てきました。
まとめ
改めて説明するまでもないですが、僕は今回まったく絵は描いていません。
すべてAIのツールが描いてくれました。
最近、テキストTo画像生成のAIが立て続けにリリースされていますが、テキストの文章を与えただけでここまで精度の高い描画ができるようになりました。
Stable Diffusionは、自分のパソコンなどローカル環境で実行できるのがいいですね。
Stable Diffusion、DALL-Eとも描画する絵の特徴というか、プロンプトに対する受け止め方の個性のようなものはありますが、検証した範囲ではDALL-Eのほうが指示内容を忠実に再現してくれる画像が多かったように思います。
このあたりは、プロンプトの文章の書き方で、生成される画像も変わってくると思いますので、「プロンプトエンジニア」のような技術が必要になってくるかもしれませんね。
コツをつかめば自由自在に自分の欲しい画像ができる時代になりました。
この記事が気に入ったらサポートをしてみませんか?