
コピー機学習法で作るスライダーLoRA

キャラクターを作れるタイプのゲームはスライダーを左右に動かすだけで、お好みの体型に出来ますよね?
それなのにstable diffusionはちょっとlarge breastsとかPromptに書くと、勝手に年齢を上げたり全体の肉付きを増やしてきたりします、許せませんね。
今回はあのスライダーみたいな調整が出来るLoRAを作ってみようという話と見せかけて、コピー機学習法ってすげー!とかそういう話です。
はじめに(成果物の提示)
先に成果を出しておく。その方が説明しやすいので。
以下、ツイート(ポスト?)にある頭身スライダーをベースに説明する。
頭のサイズ(≒頭身)を調整するLoRAをバージョンアップしました。
— エマノン (@Emanon_14) September 10, 2023
精度向上と余計な影響の排除が主な目的です。https://t.co/RDeKUEFM32
さすがに前回(5月)より様々な知見が蓄積されているので、上位互換と言って差し支えないかと。 pic.twitter.com/Y7jxFUxUtP
そもそもコピー機学習法とは?
Kohya氏と月須和氏の記事を参照してください。
ボクもふわっとした記事を書いていたので一応載せておきますが、上2つ読んだら完全に理解したって顔になってるはずなので、飛ばしてもいいです。
概要
今回は頭のサイズのみをLoRAのWeightによってシームレスに変化させることが目的なので、必要な教師データは頭が小さい画像と頭が大きい画像の2種。
手順は下記のようなイメージ。
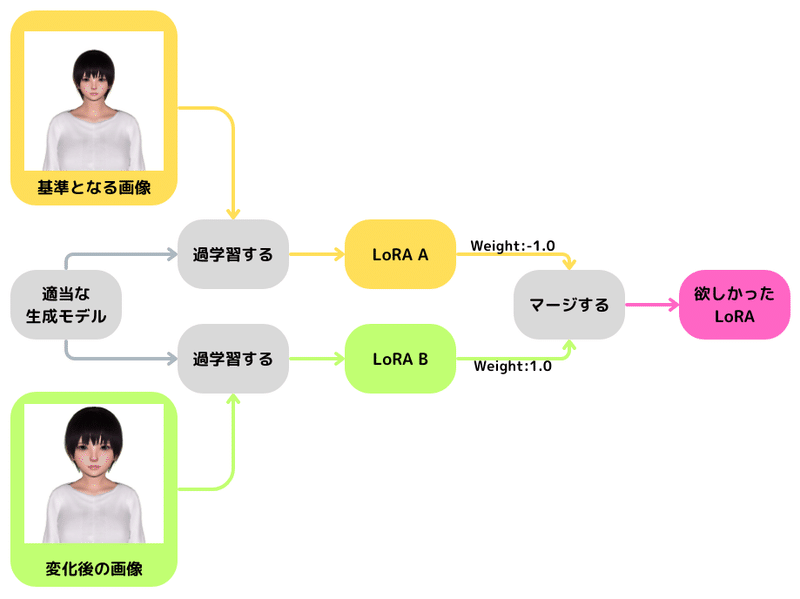
コピー機学習法には2つの手法がある。
①ベースモデルに基準となる画像を学習したLoRAをベースモデルにマージし、そのマージモデルに変化後の画像を学習してLoRAを作る
②「ベースモデルに基準となる画像を学習したLoRA A」と「ベースモデルに変化後の画像を学習したLoRA B」の差分を取る
※今回行ったのは②の手法
一概にどちらの手法が良いとは言えないので、お好きな(結果が良い)手法を選んでね。
ポイントとなるのは生成結果が限定される(同じ画像しか出ない)状態にすることで、欲しい要素(頭のサイズ)以外での差異が生じないこと。
以下、フロー図の順を追って説明する。
手順0:教師データの準備
オイオイ、コイツいきなりフロー図に存在しない話始めたぞ。
率直に言って最も重要なのは教師データの準備なので。
とはいえ通常の学習と違って必要な画像はたったの2枚(場合によっては2枚を別アングル等で数セット)である。
実際、頭身スライダーで使用した画像は下記の2枚。

教師データのポイントとしては変化させたい箇所以外はピクセル単位で同一な画像を用意すること。
また、変化がわかりやすい程すんなり学習するので、画角をいい感じに調整すること。ここはもうトライ&エラーするしかない。
手順1:基準となる画像を学習する
まず、学習対象とする生成モデルについて。
コピー機学習法の場合、生成結果がもれなく教師データと同一になるように学習するので、生成モデルはなんでもOK、お好きにどうぞ。
学習の設定について。
繰り返し回数は100としている(教師データを入れるフォルダの名前を「100_girl」としている)
だいたい1,000Step~3,000Stepで良い感じになる(個人の感想です)ので、30epochの学習で10epochごとに保存している。
dimは4~16の間から、教師データの変化がわかりやすいかによって変えている。頭のサイズはわかりやすいので4とした(雰囲気)
テキストエンコーダに学ばせることなど無いのでUnet Onlyにする。
後は適当でいいんじゃないですかね。
learning_rate 0.001
resolution 512
train_batch_size 2
max_train_epochs 30
network_dim 4
network_alpha 1
save_every_n_epochs 10
optimizer_type "AdamW"
lr_warmup_steps 250
bucket_no_upscale
lr_scheduler "cosine_with_restarts"
network_train_unet_only
noise_offset 0.1
multires_noise_discount 0.3学習が完了したら結果をチェックすること。
学習中に画像を作らせてもよいが、ボクは出来上がったLoRA(10epochごとの3種)をX/Yプロットで並べて生成して見比べている。念のためね。
チェックする時はPromptには何も入れないこと。
「基準となる画像」と同じ画像しか出ない状態になっていれば合格。
手順2:変化後の画像を学習する
手順1と同様に変化後の画像を学習させる。
手順1と同様に結果をテストする。今度は「変化後の画像」と同じ画像のみが生成されれば合格。
手順3:作ったLoRAをマージする
LoRA AとLoRA Bをsvd mergeでマージする。
なんでsvd mergeかというと偉い人がそう言ったからです。ボクはよくわかりませんが、単純に足したり引いたりすると変になるらしいです。
venvをアクティベートしてから下記のように入力する。
見やすいように改行したが、実際は1行で書くこと。
python networks\svd_merge_lora.py
--save_to c:\hogehoge\LoRA Kansei.safetensors #完成品のLoRAの保存場所
--models c:\hogehoge\LoRA B.safetensors c:\hogehoge\LoRA A.safetensors #LoRA AとLoRA Bの場所
--ratios 1.0 -1.0 #LoRA Bを1.0、LoRA Aを-1.0
--new_rank 8 #rank(dim)は2倍にする
--device cudaLoRA BからLoRA Aを引きたいので、LoRA Bを1.0、LoRA Aを-1.0でマージすること。
rank(dim)は元の2倍(今回は元が4だったので8)にすること。
手順は以上。これほとんどただのコピー機学習法の説明では?
【2023年10月1日追記】
最新のmerge_lora.pyは劣化無く結合できるようになりました(SDXLブランチ限定でしたが、SDXLブランチがメインにマージされました)
rank(dim)の指定自体が必要無いので「今回作ったLoRAはrankが4じゃなくて8だったわ!」みたいなことも無くなりますね、ありがとうございます。
詳細は下記ツイートと公式のリポジトリを参照してください。
sdxlブランチを更新し、sdxl_merge_loraおよびmerge_loraでLoRAの結合が劣化なしでできるようになりました。コピー機学習等にご利用ください。PRをいただいたlaksjdjf氏に感謝します。https://t.co/4Z9YJjrJ2h
— Kohya Tech (@kohya_tech) October 1, 2023
おわりに
記事を書いている途中で「あれ、差分抽出ってどうやるんだっけ?」という、お前記事書いてる場合じゃない、記憶喪失か?という事態に見舞われましたが、Kohya氏の助けで記憶を取り戻すことができました、ありがとうございました。
そして、改めて記事を見直すと冒頭で引用した記事を読めばこの記事読む必要ないのでは?ということに気づきました。無断で引用させて頂いたKohya氏と月須和氏に感謝します。
まあ、記憶喪失になる程度の理解度でも差分抽出はできるよ!ということで。
おしまい
この記事が気に入ったらサポートをしてみませんか?