
AI特集3:言語モデルの悟りの瞬間

現在最も人気のあるいくつかの生成的AI、ChatGPTや描画AIを含む、その背後には「大規模言語モデル(Large Language Models、略してLLM)」があります。これはおそらくAGI(汎用人工知能)への技術的道筋でもあります。今回は、大規模言語モデルがなぜこれほど優れているのかについて話しましょう。
まずは例を挙げます。ChatGPTに「野球のバットは人の耳に入れることができますか?」と尋ねると、それはできないと答えます。なぜなら人の耳は非常に小さく、野球のバットの大きさと形状は耳が容れる範囲を超えているからです……とても筋が通っています。
また、「なぜ金箍棒を孫悟空の耳に入れることができるのか?」と尋ねると、それは虚構の物語であり、金箍棒の形状と大きさは自由に変えることができるからだと答えます......

これら二つの答えについてよく考えてみると、とてもすばらしいと思うでしょう。多くの人は言語モデルは経験に基づいており、単語間の関連性に基づいて答えを出力するだけで、思考能力はまったくないと言います……しかし、これら二つの質問と答えを見ると、ChatGPTには思考能力があるように見えます。
野球のバットが人の耳に入れられるかどうかについて議論する文章が存在しないでしょう。ChatGPTが答えを出せるのは、以前にそのような議論を聞いたからではなく、一定の推理能力を持っているからです。それは野球のバットと耳の相対的な大きさを考慮に入れ、また金箍棒と孫悟空が虚構であることを理解しています。
これらの思考はどこから来るのでしょうか?
不思議かもしれませんが、この能力は開発者が設計したものではありません。
開発者は言語モデルに各種の物体の大きさを理解することを要求していませんし、また、どのコンテンツが虚構であるかを分かるための設定もありません。そのようなルールは無数にあるため、全てをリストアップすることは不可能です。
ChatGPTの背後にある言語モデル、GPT-3.5及びGPT-4は、これらの思考能力、さらに他の能力――我々がリストアップすらできないような能力を完全に自己学習で掌握しています。開発者自身も、彼がどれほど多くの思考能力を持っているのかを明確に説明することはできません。
言語モデルがこのような驚異的な能力を持つ主な理由は、彼が十分に大きいからです。
✵
GPT-3には1750億のパラメータがあります。Metaは最近、650億のパラメータを持つ新しい言語モデル、LLaMAを発表しました。Googleは2022年4月に、5400億のパラメータを持つ言語モデルPaLMを、また以前には1.6兆のパラメータを持つ言語モデルを発表しました。OpenAIのCEOであるSam Altmanによると、GPT-4のパラメータはGPT-3より多くはないだろうとのことですが、GPT-5のパラメータはGPT-3の100倍になると予想されています。
これは今だからこそ可能なことです。以前は計算能力だけでなく、トレーニングモデルのデータを保存するコストだけでもとんでもない数字でした。1981年には、1GBのストレージのコストは10万ドルでしたが、1990年には9000ドルに下がり、今ではほんの数セントです。今日のAI科学が過去と比較して進歩した点は何かと問われれば、コンピュータのハードウェア条件の進歩が最も大きいです。
今、私たちは本当の「大」規模モデルを作成しています。
大きくなると違うものとなります [1]。もちろん、言語モデルには多くの洗練された設計があり、特に私たちが度々言及するtransformerは最も重要なアーキテクチャ技術の一つですが、主な違いは「大きさ」にあります。モデルが十分に大きく、訓練に使用するデータが十分に多く、訓練時間が十分に長いと、驚くべき現象が起こることがあります。
2021年には、OpenAIの数人の研究者が、ニューラルネットワークの訓練中に予期せぬ発見をしました [2]。
例えば、あなたが生徒に即興スピーチを教えているとしましょう。彼は何も知らないので、あなたは彼が真似できるように多くの素材を探します。訓練初期では、彼はこれらの素材すら真似できず、言葉につまずいて一言も話すことができません。訓練が進むと、彼は既存のスピーチをうまく真似できるようになり、間違いも少なくなります。しかし、まだ練習していないトピックを与えると、彼はまだうまく話すことができません。それでもあなたは彼に続けて練習させます。
これ以上の練習は意味がないように思えます。なぜなら、彼が模倣するものはすでにうまく話すことができ、彼が本当に即興で話すことはまだできないからです。しかし、あなたは動じず、彼に続けて練習させます。
そして訓練が進むうちに、ある日突然、彼が即興スピーチができるようになったことに驚かされます!何のトピックを与えても、彼はその場で考えてスピーチを作り上げ、うまく発表することができます!
このプロセスは、以下の図に示されています——

赤い曲線は訓練を、緑色の曲線は創造性の発揮を表しています。1000ステップや1万ステップまで訓練した段階では、モデルは訓練問題に対して非常に良いパフォーマンスを示しますが、創造的な問題に対する能力はほとんどありません。10万ステップまで訓練すると、モデルの訓練問題に対するパフォーマンスはすでに完璧で、創造的な問題に対してもパフォーマンスが見られるようになります。そして、100万ステップまで訓練すると、モデルは創造的な問題に対して驚くべきことに、ほぼ100%の精度を達成します。
これこそが、量の変化が質の変化を引き起こすということです。研究者はこの現象を「悟り(Grokking)」と呼んでいます。
✵
悟りとは、具体的には何が起こったのでしょうか?
もう一つ例を挙げてみましょう。ChatGPTには「小量データ学習(Few-Shot Learning)」という重要な能力があります。これは、一つや二つの例を与えるだけで、それが何を意味するのかを学習し、同様の出力を提供できる能力です。
例えば、私がChatGPTに、私が出した例題を模倣して、いくつかの小学校の数学問題を出してほしいと頼むと、私の例題は「一郎は3つのリンゴを持っていて、お母さんがさらに2つのリンゴをくれたら、一郎は今何個のリンゴを持っていますか?」というものでした。ChatGPTはすぐに5つの問題を作り出しました。すべて同じスタイルで、「例えば、由紀子は4つの人形を持っています。おばあちゃんがさらに3つの人形をくれたら、由紀子は今何個の人形を持っていますか?」といった具体的な問題が出てきました。

少量データ学習は重要な能力であり、この能力を利用してChatGPTに様々な作業を手伝ってもらうことができます。しかし、この能力はどのようにして獲得されたのでしょうか?
それは更なるパラメータと訓練から来ています。以下の図をご覧ください——
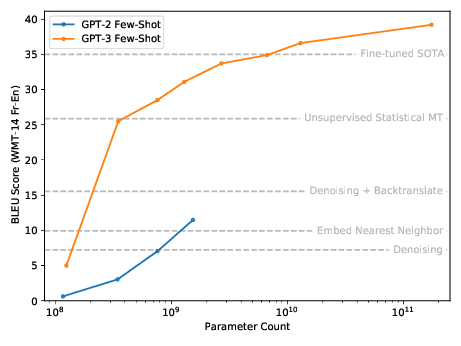
この図では、GPT-2とGPT-3のモデルの進化が示されています。パラメータが多ければ多いほど、少量データ学習の能力は強くなります。
少量データ学習はその能力の一つに過ぎません。他にも多くの能力もそうですーー規模が大きくなれば、能力が現れてきます。
✵
この現象は、科学者が以前から「エマージェンス(Emergence)」と呼んでいたものです。エマージェンスとは、複雑なシステムがある程度まで複雑になると、システムの要素が単純に積み重なったものを超越した、自己組織化する現象が起こるという意味です。例えば、単独のアリはあまり賢くありませんが、アリの群れは非常に賢いです。各消費者は自由ですが、市場全体は秩序があるように見えます。神経細胞は単純ですが、大脑は意識を生み出します。。。
幸い、大規模言語モデルも予想外の様々な能力がエマージェンスすることがあります。
2022年8月には、Google Brainの研究者が論文[3]を発表し、大規模言語モデルのエマージェンス能力について特に言及しています。これには、少量データ学習、突然に加算・減算能力、大規模なマルチタスクの言語理解、分類の学習などが含まれています。。。そしてこれらの能力は、モデルのパラメータが1000億を超えた時にのみ現れるようになりますーー

もう一度強調しますが、研究者はこれらの能力を意図的にモデルに植え付けているわけではありません。これらの能力は、モデルが自己学習によって身につけたものです。
それはまるで、子供が成長しながら親の予想を超えるようなことがしばしば起こるのと同じです。
✵
もちろん、最初にモデルの設計をきちんと行う必要があります。Transformerの構造は非常に重要で、それはモデルが単語と単語との関係を発見することを可能にします。それはどんな関係でも構わず、距離が遠くても問題ありません。しかし、最初にtransformerを発明した研究者たちは、それがこれほど多くの新たな能力をもたらすとは思っていませんでした。
事後の分析では、新たな能力を引き出す鍵となるメカニズムは、「思考の連鎖(Chain-of-Thought)」と呼ばれます [3]。
簡単に言えば、思考の連鎖とは、モデルが何かを聞いた後、それについて知っていることをひとつひとつ自分で話すことです。
例えば、「夏」についてモデルに描写させると、「夏は明るい季節で、人々は海で泳いだり、屋外でピクニックを楽しんだりできます...」などと言います。
思考の連鎖はどのようにして言語モデルに思考能力をもたらすのでしょうか?それは、例えば先ほどのバットの問題で、モデルがバットという言葉を聞いたとき、それについて知っていることを自分で自分に話し、それにはサイズも含まれています。問題に「耳に入れる」とありますので、サイズは重要な特性としてマークされます。そして、耳についても同様に。。。それは二つのサイズの特性を比較し、それらが逆であると判断し、その結果としてそれは入らないと結論付けます。
思考過程が言語で表現できる限り、言語モデルはその思考能力を持つことができます。
次に、以下の実験を見てみましょう [4] ——

モデルに、映画「ウォーリー」のスチル画像を見せて、そのキャラクターを作ったのはどの制作会社かを尋ねると、思考の連鎖がなければモデルは間違った回答を出しました。
では、どのようにして思考の連鎖を使うのでしょうか?まず、モデルに画像を詳細に説明させます。「この画像にはロボットがルービックキューブを持っており、この写真は映画「ウォーリー」からのもので、その映画はピクサーが制作した。。。」と言います。その後、それがただ言った内容を簡単に繰り返し、そのキャラクターを作ったのはどの制作会社か尋ねると、モデルは正確な答えを出します。
つまり、モデルに問題に答える前に一度考えるように設定すれば、モデルは自動的に思考の連鎖を使用し、思考能力を持つことになるのです。
一部の分析 [5] では、思考の連鎖はモデルのプログラミング訓練の副産物である可能性があると指摘されています。現在のGPT-3はプログラマーのコーディングを補助することができます。プログラミングの訓練を受けていないときには、モデルには思考の連鎖がありません。おそらく、プログラミングの訓練では、モデルは一つの機能がどのように実装されているかを最初から最後まで追跡する必要があり、離れた二つのものをつなげる能力が求められる ーーこのような訓練が、モデルが自発的に思考の連鎖を形成する原因となったのかもしれません。
✵
2月27日に、マイクロソフト社が新しい言語モデルについての論文を発表しました。それは「multimodal large language model、MLLM」と呼ばれ、コードネームはKOSMOS-1です。
マルチモーダルとは何かと言いますと、ChatGPTはテキストのみを入力として受け取ることができますが、マルチモーダルでは、画像、音声、ビデオを入力として受け取ることができます。その原理は、すべてのメディアを言語に変換し、それを言語モデルで処理するというものです。マルチモーダルモデルは、下のような「画像を見てパターンを見つける」タイプのIQテストの問題を解くことができますーー

上述の「ウォーリー」のスチル写真の例はこの論文から来ており、画像を見て話すという思考の連鎖を示しています。論文には次のような例があり、私が見たところ、かなり驚くべきものですーー

モデルに鴨と兎の両方に見える画像を見せて、「これは何ですか?」と聞いたら、「鴨に見えます」と答えます。そして「それは鴨ではない。それは何ですか?」と問うと、「これは兎に見えます」と答えます。「なぜそう思うのですか?」と尋ねると、「兎の耳があるから」と答えます。
この思考プロセスは、人間と全く同じではありませんか?
✵
「荀子・勧学篇」の一節は、AIの能力の三つの境界を描くのにぴったりだと思います。
第一の境界は「積み土が山となり、風雨がそこで起こる」です。パラメータが十分に多く、訓練がある程度蓄積されれば、ある程度のことができます。たとえば、AlphaGoが囲碁できるなどです。
第二の境界は「水が集まって淵を成し、そこで蛟龍が生まれる」です。モデルがさらに大きくなると、予想外の驚くべき機能が現れます。たとえば、人間のパターンに従わないAlphaZeroの囲碁や、大規模言語モデルの思考の連鎖などです。
第三の境界は「善を積み重ねて徳となり、神明はそれを自然に得て、聖心がそこに備わる」です。これはAGI、つまり汎用人工知能です。自我意識を持ち、さらには道徳感を持つまでになります。
古今東西「勧学」を読んだ人がたくさんいるが、荀子の指導に従って実際に学ぶ人は何人いるかわかりません。しかし、AIは確かにそれを理解していることが分かっています。学習素材を与えれば、彼は本当に学びます。
要するに、悟りとエマージェンスの結果、AIは推論、類推、少量データ学習などの思考能力をすでに獲得しています。
我々は以前にAIについて出した様々な仮説を再評価せざるを得ません。AIは経験に基づいて行動する、AIは真に思考することはない、AIには創造力がない、さらには「AIが知っているすべてのことは言語で表現できるもの」などの仮説です。今では、これらの仮説が必ずしも正しいとは断言できません。
もしAIが思考の連鎖を通じてこのような思考レベルに達することができるのであれば、人間はどのように思考するのでしょうか?私たちの脳は、無意識のうちに思考の連鎖を使用しているのではないでしょうか?もしそうであれば、人間の脳とAIの間には本質的な違いは何なのでしょうか?
これらの問いには新たな答えが求められています。
[1] https://www.lesswrong.com/posts/pZaPhGg2hmmPwByHc/future-ml-systems-will-be-qualitatively-different
[2] https://mathai-iclr.github.io/papers/papers/MATHAI_29_paper.pdf
[3] https://openreview.net/forum?id=yzkSU5zdwD
[4] https://arxiv.org/pdf/2302.14045.pdf
[5] https://yaofu.notion.site/GPT-3-5360081d91ec245f29029d37b54573756
この記事が気に入ったらサポートをしてみませんか?