
つくば市の人口密度ヒートマップを作る[Python, GeoPandas]

こんにちは。つくばに住む研究者です。
今回はいつも通りPythonを使い、公共のデータからつくば市の人口密度のヒートマップ(コロプレス図)を作ろうと思います。
データのダウンロード
つくば市は特に人口増加の著しい街です。どの地域で人口が増加しているのかを地図上でみてみましょう。市内の細かな地域の変化について確認するため、小地域(町丁レベル)での統計情報をe-Statからダウンロードします。
今回は2005年と2020年の2つの年度についてヒートマップを作ります。
データの読み込み
いつものとおり、ダウンロードしたデータを解答し、Google Drive上にアップロードします。地図情報を扱うためのPythonライブラリであるGeopandasをインポートし、Google Colabでデータを読み込みます。
まずはGeopandasをpipでインストールします。
!pip install --upgrade geopandas --q今回の作業に必要なライブラリをインポートします。
from google.colab import drive
import pandas as pd
import numpy as np
import shapely
import geopandas as gpd
import folium
from branca.element import FigureDriveをマウントし、データを読み込みます。
drive.mount('/content/drive')
dir_path = データをおいたパス
gdf = gpd.read_file(dir_path+'/A002005212020DDSWC08-JGD2011/r2ka08.shp',encoding='shift-jis')うまく読み込めているかチェックします。
gdf = gdf[gdf['CITY_NAME']=='つくば市'].reset_index(drop=True)
fig = Figure(width=400, height=300)
map = folium.Map(location=[36.1, 140.1] ,zoom_start=11)
fig.add_child(map)
folium.GeoJson(gdf["geometry"]).add_to(map)
map
つくば市の小地域のポリゴンが正しく表示されました。
さて、今回使っているデータフレームにはすでに地域毎の人口データも['JINKO']のカラムに入っています。地域の面積も['AREA']にはいっているため、この2つを使えば人口密度を計算できます。
gdf['人口密度'] = gdf['JINKO']/(gdf['AREA']*1/1000*1/1000)人口密度のヒストグラムを確認してみましょう。ヒートマップを作るにあたって、値域を決定する際の参考にします。
gdf['人口密度'].hist(bins=50)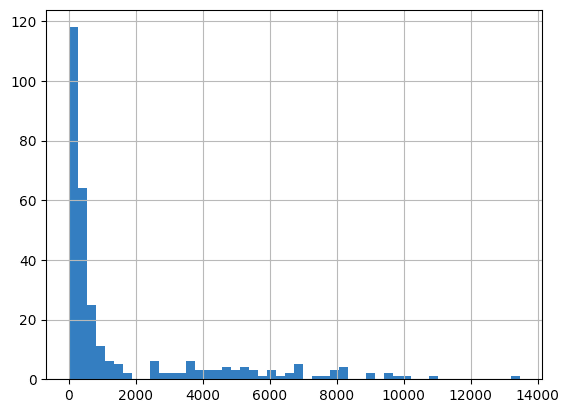
地域にはかなり広がりがあるようです。もっとも数が多いのは人口密度1000人/平方キロメートル以下の地域ですが、上はその10倍の地域もあります。ヒートマップはLogを使って色分けをした方が良さそうです。
今回もいつもの通り、値に応じた色をデータフレームに持たせ、その色を使って1つずつポリゴンを描写する作戦でいこうと思います。まずは100 ~15000程度の地域をLogspaceで40分割に区切り、それぞれに対応する色を作ります。今回は色スペースにはviridis反転されたviridis_rを使います。matplotlibには色々なcolor mapが用意されていますが、私はinfernoとviridisが特に気に入っています。

ついでに16進のHTML色表記と10進の色表記を変換する関数も用意しておきましょう。
import matplotlib.cm as cm
v = np.logspace(2,4.2, num=40, endpoint=True, base=10.0, dtype=None)
c = cm.viridis_r(range(0,250,int(250/len(v))))
def rgb_to_hex(rgb):
return '%02x%02x%02x' % rgb人口密度に応じた色を保持するようにします。
for i in range(0,len(gdf)):
r = float(gdf.iloc[i]['人口密度'])
id = sum(v <= r)
if id >= len(v) :
id = len(v)
elif id <= 0:
id = 0
r = c[len(v)-id]
r = tuple((r[0:3]*255).astype(int))
r = rgb_to_hex(r)
gdf.loc[i, '色'] = '#'+str(r)geopandasのデータフレームからそれぞれの形状と色を読み出し、地図上にプロットします。
sentence = ''
for i in range(0,len(gdf)):
sentence = sentence+'folium.GeoJson(gdf.iloc['+str(i)+'][\"geometry\"],style_function = lambda feature:{\"fillColor\": gdf.iloc['+str(i)+'][\'色\'],\"color\": \'#000000\',\"weight\": 0.5,\"fillOpacity\": 0.7}).add_to(map) \n'
idx = 80
fig = Figure(width=700, height=1000)
map = folium.Map(location=[36.1, 140.1] ,zoom_start=11.5)
fig.add_child(map)
exec(sentence)
map2020年のデータは以下のようになりました。
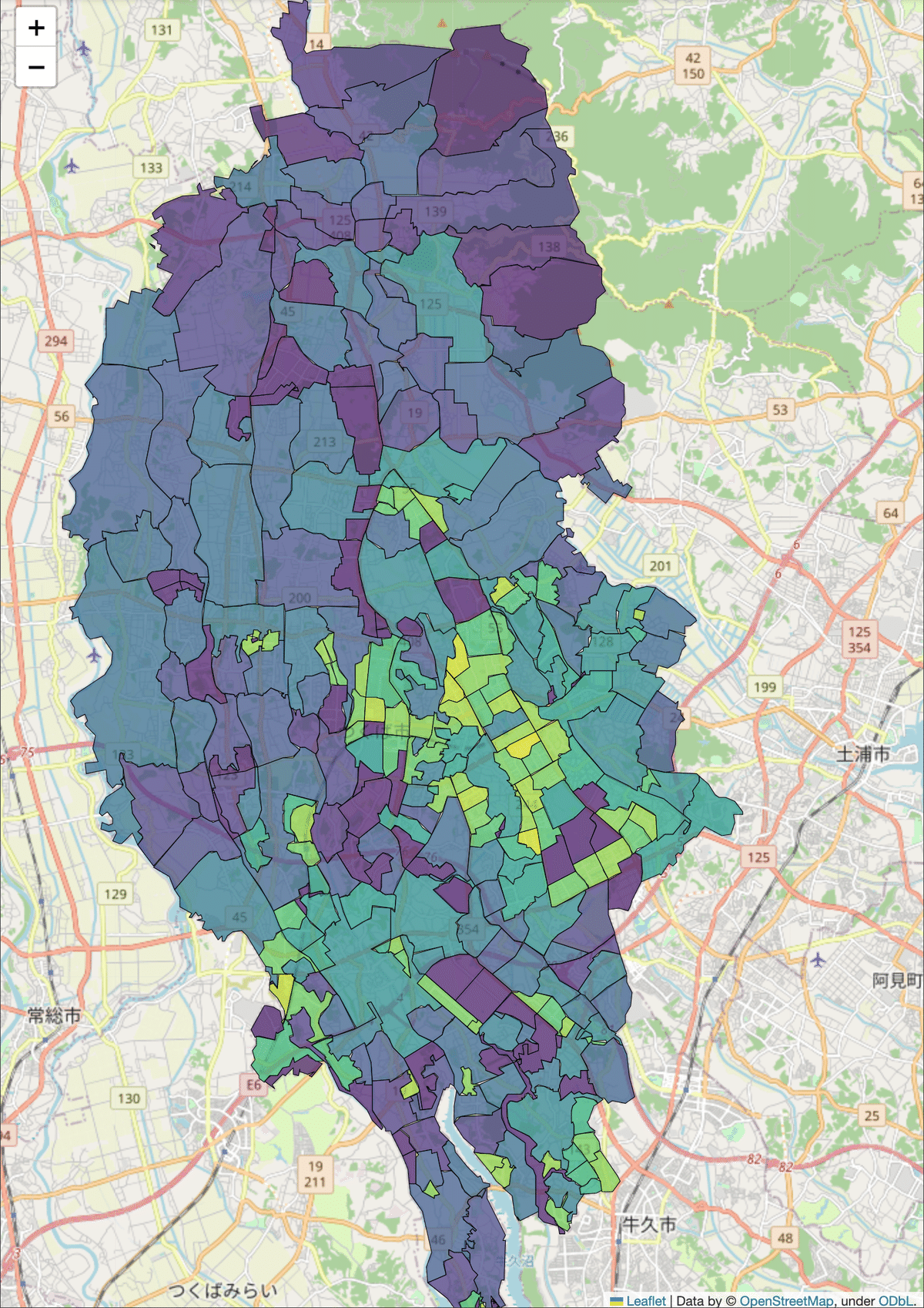
色の割り当てを確認してみましょう。カラーマップを可視化します。
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize = (10,6),dpi=100)
ax.imshow([c])
ax.tick_params(labelbottom=True, labelleft=False, labelright=False, labeltop=False, labelsize=20)
plt.show()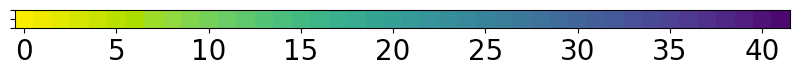
40区切りの色と対応する数値は変数vの中にあります。
print(v)
今回作った図では、人口が「0」となっている地区については一番くらい青色が当てられています。しかし、実際に0人であるわけではなく、単純にデータが入れられていないケースの方が多そうです。if文を使い、人口が0である場合は描写しない、などの工夫をしたほうが、より誤解の無い図になると思われます。
次に、同じ手順で2005年の人口密度ヒートマップを確認します。以下のようになりました。
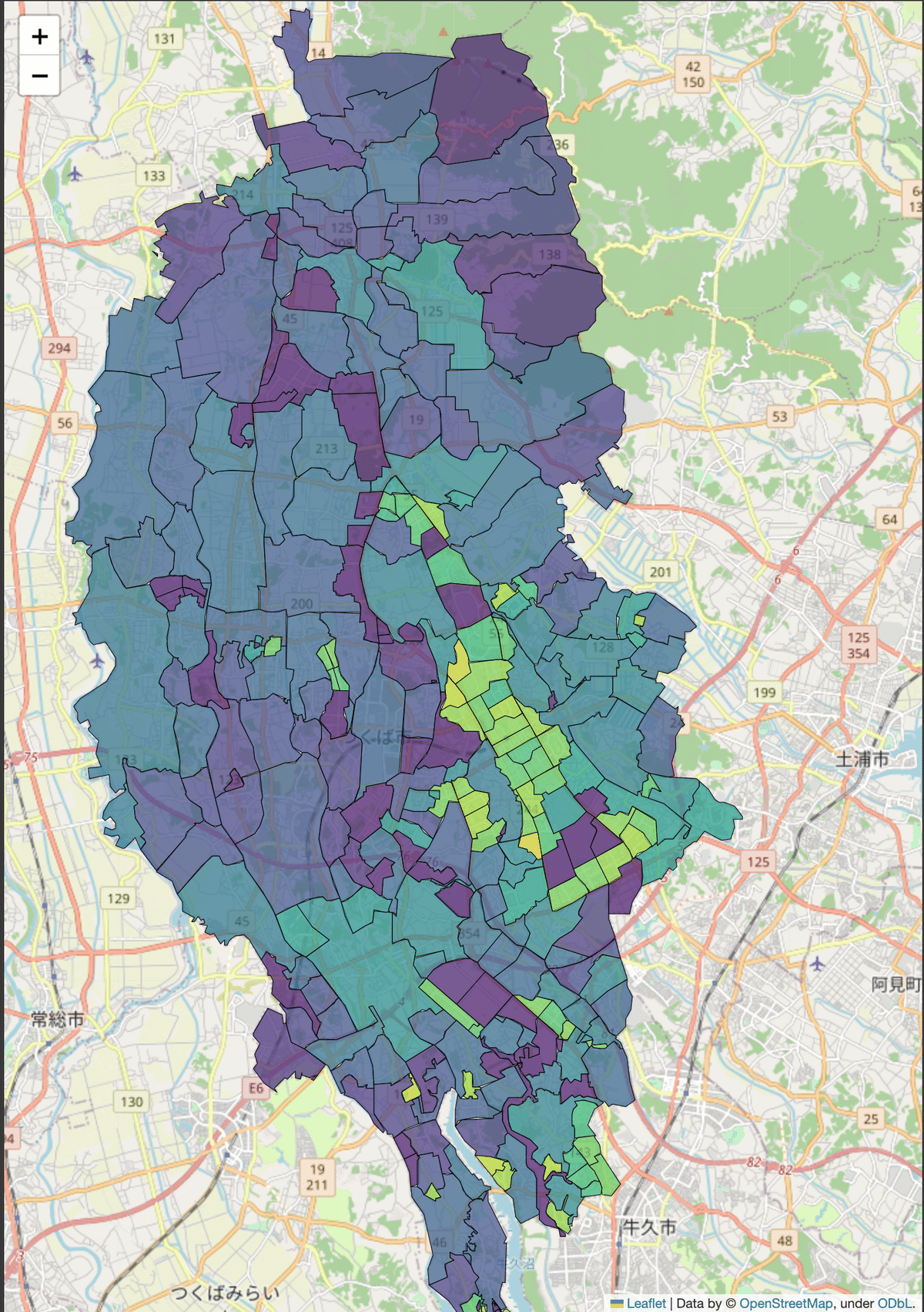
両者を比較してみると、2005年では人口密度が低かったいくつかの地域について、2020年では大きく上昇していることがわかります。該当する地域は主に鉄道駅の周辺のように見えます。鉄道路線と駅の地図情報も地図の中に書き込んでみましょう。国土地理院から鉄道の座標データをダウンロードします。つくば市のポリゴンを地図上に重畳させたときと同様に、Geopandasを使います。ただし、鉄道のデータはポリゴンではなく、ライン(点の集まり)であるため、描写の際には少し方法を変えてやる必要があります。
まずは駅をプロットします。今回はつくばエクスプレスの駅だけを見れば十分ですので、データの中から「常磐新線」の駅だけを抜き出します。常磐新線というのがつくばエクスプレスの正式な路線名だそうです。
df_st = gpd.read_file(path+'/N02-20_GML/N02-20_Station.shp',encoding='shift-jis')
df_st = df_st[df_st['N02_003']=='常磐新線'].reset_index(drop=True)
fig = Figure(width=400, height=300)
map = folium.Map(location=[36.1, 140.1] ,zoom_start=11)
fig.add_child(map)
folium.GeoJson(df_st["geometry"]).add_to(map)
map
問題なく描写できたようです。次に、路線を描写します。路線は点座標の集まりで表現されているため、結合させて線を作ったのちに描写してやる必要があります。
df_line = gpd.read_file(path+'/N02-20_GML/N02-20_RailroadSection.shp',encoding='shift-jis')
df_line = df_line[df_line['N02_003']=='常磐新線'].reset_index(drop=True)
fig = Figure(width=400, height=300)
map = folium.Map(location=[36.1, 140.1] ,zoom_start=11)
fig.add_child(map)
folium.GeoJson(df_line['geometry'].unary_union).add_to(map)
map
これで準備ができました。先ほどの図と重ねて表示してみましょう。
sentence = ''
for i in range(0,len(gdf)):
sentence = sentence+'folium.GeoJson(gdf.iloc['+str(i)+'][\"geometry\"],style_function = lambda feature:{\"fillColor\": gdf.iloc['+str(i)+'][\'色\'],\"color\": \'#000000\',\"weight\": 0.5,\"fillOpacity\": 0.7}).add_to(map) \n'
idx = 80
fig = Figure(width=700, height=1000)
map = folium.Map(location=[36.1, 140.1] ,zoom_start=11.5)
fig.add_child(map)
exec(sentence)
roads_style_function = lambda x: {
'color' : 'red',
'opacity' : 0.50,
'weight' : 3,
}
st_style_function = lambda x: {
'color' : 'red',
'opacity' : 0.50,
'weight' : 7,
}
folium.GeoJson(df_line['geometry'].unary_union, style_function = roads_style_function).add_to(map)
folium.GeoJson(df_st['geometry'], style_function = st_style_function).add_to(map)
map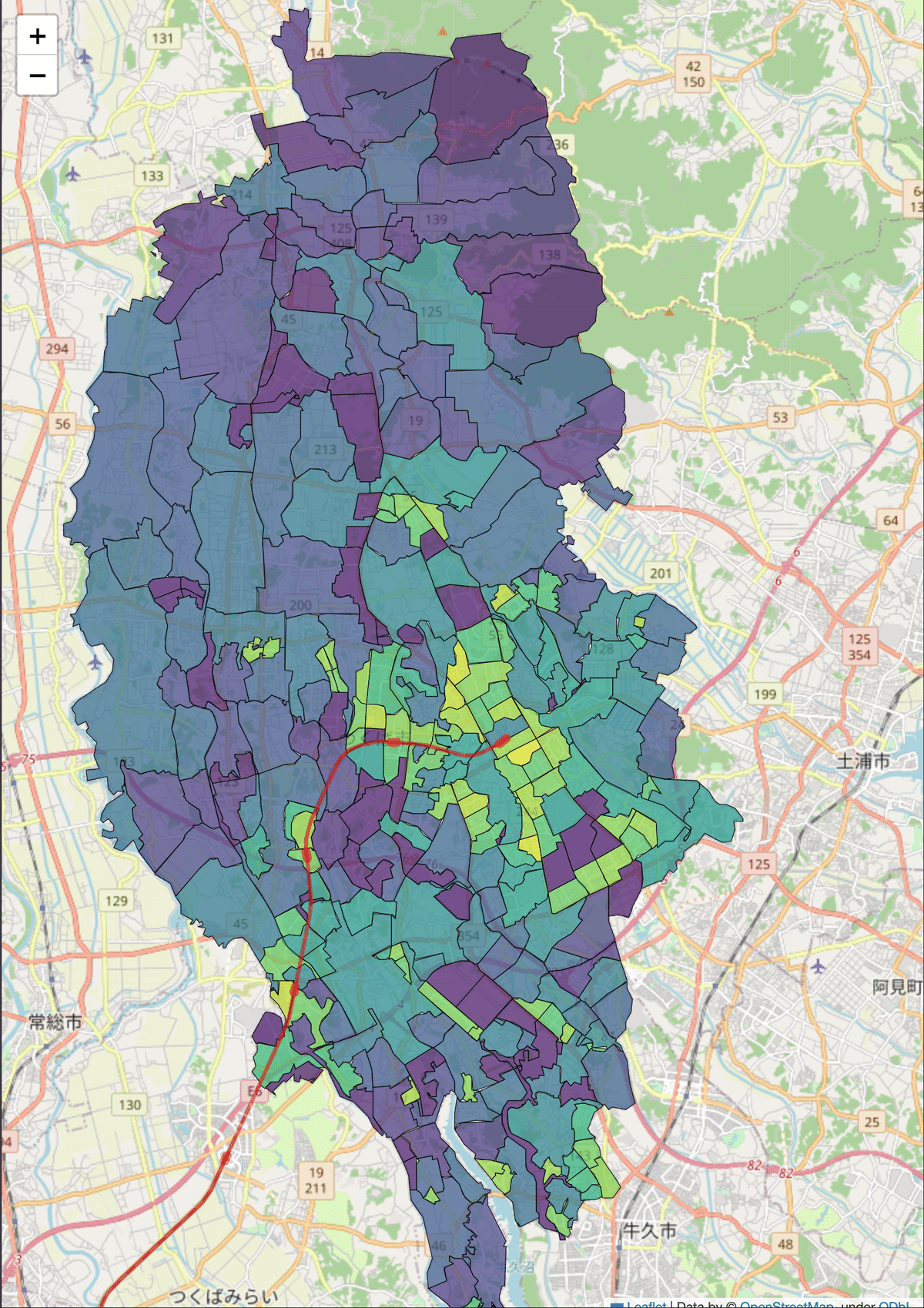
2つの年度のヒートマップを並べると次のようになります。
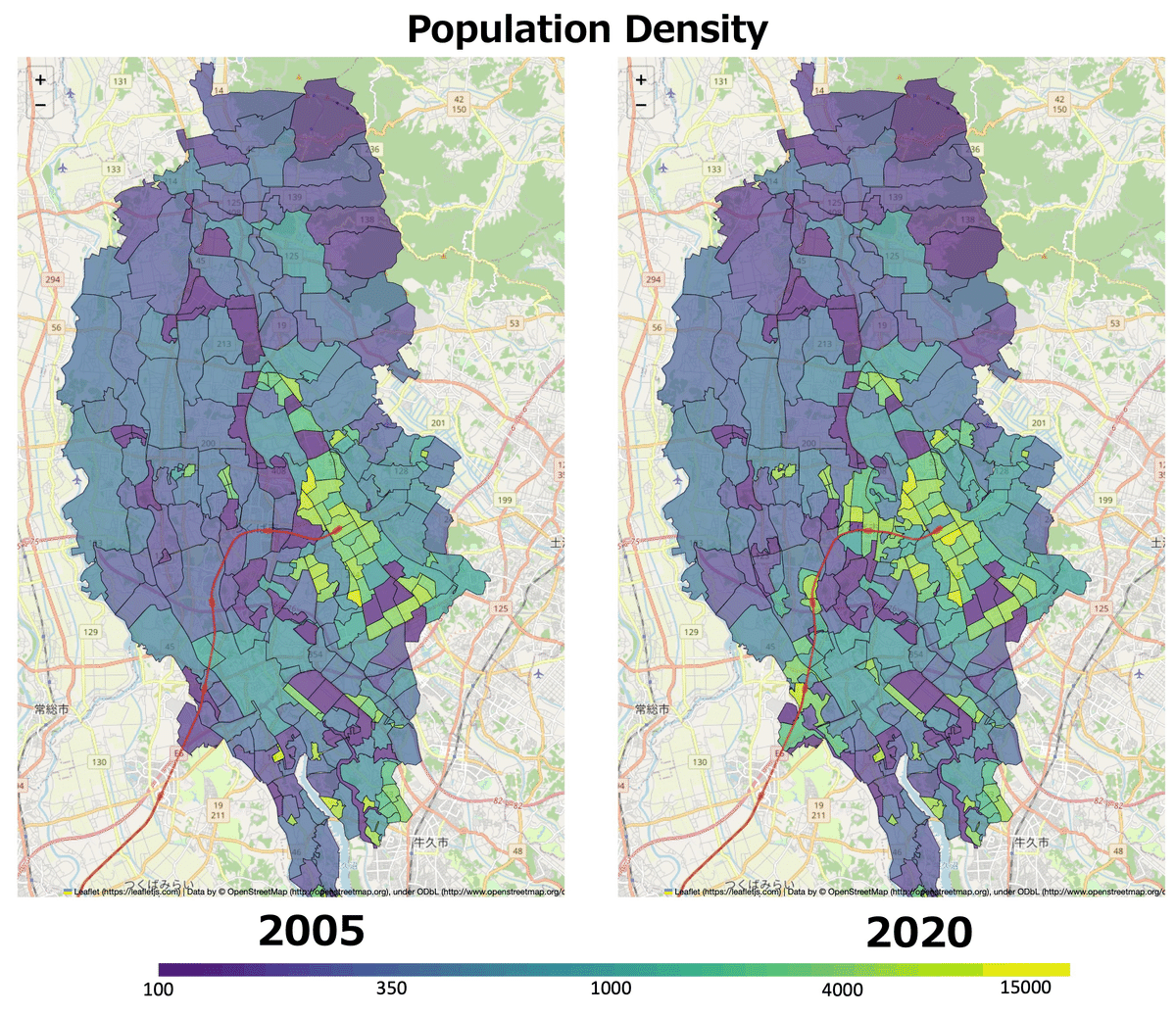
鉄道駅の周辺で特に人口増加が著しいことがわかります。
鉄道はすごい!
それでは。