
深層強化学習によるBTC-FXのトレード成績と手法

このnoteでは、筆者が実際に稼働させている深層強化学習BOTによるbitFlyer BTC-FXのトレード成績と、その手法についてや体験を記述しています。
ソースコードは載せていないため、すぐに稼働できるBOTや学習が回せるプログラムは用意していません。深層強化学習トレーディングを始めるためには、ご自身でデータ収集やプログラムを実装していただく必要があります。
また本記事では、筆者が稼働させている深層強化学習BOTについて一部記述していますが、設計の詳細や全ての情報は公開していません。
深層強化学習トレーディングは簡単に稼げるものではなく、戦略の獲得は時間が掛かります。
この記事をもとに実装したBOTによる損失については一切責任を負いかねます。自己責任でご利用ください。
1. 背景
現在、世界中で人工知能・AIの技術が実用化されています。最近では自動翻訳や画像認識の技術など、実際に人工知能が社会で使用され生活の一部となる機会が増えてきました。
また、シンギュラリティ(技術的特異点)や、AlphaGoといったような人間に勝てる人工知能も話題になりました。今後も人工知能の技術は発展していき、様々な分野で活用されると考えられます。
今回は、トレーディング(bitFlyer BTC-FX)について人工知能を応用できないかと考えました。
人工知能でトレーディングをしようとすると、価格の上がり下がりや騰落率の予測をもとに売買を行う方法などがあると思います。これらが高い予測精度で、それを維持することができれば長期的にプラスの収益をあげることができると考えられます。しかし、100%予測があたり続けることは基本的にはないため、外れた後の処理も戦略として考える必要があります。
そこで、ポジション発生後の行動や損切りのタイミングなども重要になることに注目し、今回は価格の予測やその後の売買行動の全てを人工知能に任せてしまう方法でシステムを実装していこうと思います。
2. 深層強化学習とは
人工知能によるトレーディングを実現するために、深層強化学習(Deep Reinforcement Learning)の手法を応用して実装しました。
深層強化学習を簡単に説明すると、自らデータを取得して失敗や成功を繰り返していくうちに徐々に進化していく人工知能・・・のようなイメージです。(ここでは軽く説明するため、詳しく知りたい方は他のサイトや書籍で確認してください)
機械学習のアルゴリズムの1つで強化学習と深層学習を組み合わせた技術になります。
(深層)強化学習の多くはゲーム環境で使用されています。
これまで「囲碁」「チェス」といったゲームを学習させた強化学習では、人間のパフォーマンスを超えたスコアが出ています。また「スーパーマリオ」「パックマン」「スマブラ」のような様々なゲームに対しても強化学習を適応した論文や動画が上がっています。
最近では下の映像のように、より現実に近い3D空間のゲーム「マインクラフト」に対して強化学習を適応させようと実験環境が用意されています。
強化学習は日々研究がされているため、多くの手法が出てきています。今回はこの強化学習のアルゴリズムの中でも有名な、DQN(Deep Q-Network)を使用していきます。
DQNとは、強化学習の1つであるQラーニングに深層学習を用いたものです。DQNには報酬の最大化を目指すエージェントがいます。このエージェントは与えられた環境の中で自ら行動し、未来の価値を最大化するように報酬の獲得方法を見つけていきます。未来の価値とは、行動後の即時報酬ではなく長期的な報酬に目をむけた価値のことです。この未来の価値を最大化するための行動価値関数(戦略)をエージェントが導き出すことができれば、報酬を最大化するエージェント(人工知能)が作成できます。
ここで、深層強化学習トレーディングを説明していくために、必要な用語を説明します。
・用語
深層強化学習で使用される用語として、エージェント(agent)、行動(action)、報酬(reward)、環境(environment)、状態(state)があります。
エージェント・・・与えられた環境の中で動くロボット
行動・・・エージェントの動ける範囲や指定された動作のこと
報酬・・・エージェントが最大化しようとするもの
環境・・・設計した仮想のフィールドや実際に行動する場所
状態・・・エージェントに見せて判断させる情報、入力データのこと
DQNではこれらを設定する必要があります。エージェントをどう成長させるかを考え、適切な行動・報酬・状態をエージェントに与えることが重要なポイントになります。
3. 目標

今回の目標はエージェントにトレード資産を最大化させることです。
収益を獲得する戦略を人工知能(エージェント)に学習させ、実際にトレード資産を増やしてもらいます。この手法がビットコインFXで実現できれば、他の仮想通貨や株式市場などのトレーディング環境にも応用できる可能性が出てきます。
4. 環境
今回はbitFlyer BTC-FXで検証します。一定期間学習させた後、実際にトレーディングをして、損益結果を出します。
また、上記の書籍を参考にプログラミング言語はPyhtonを使用し、深層強化学習(DQN)のライブラリはChainerRLを使用しました。環境についてはOpenAI Gymを使いシミュレーションとバックテストを行いました。
5. 方法
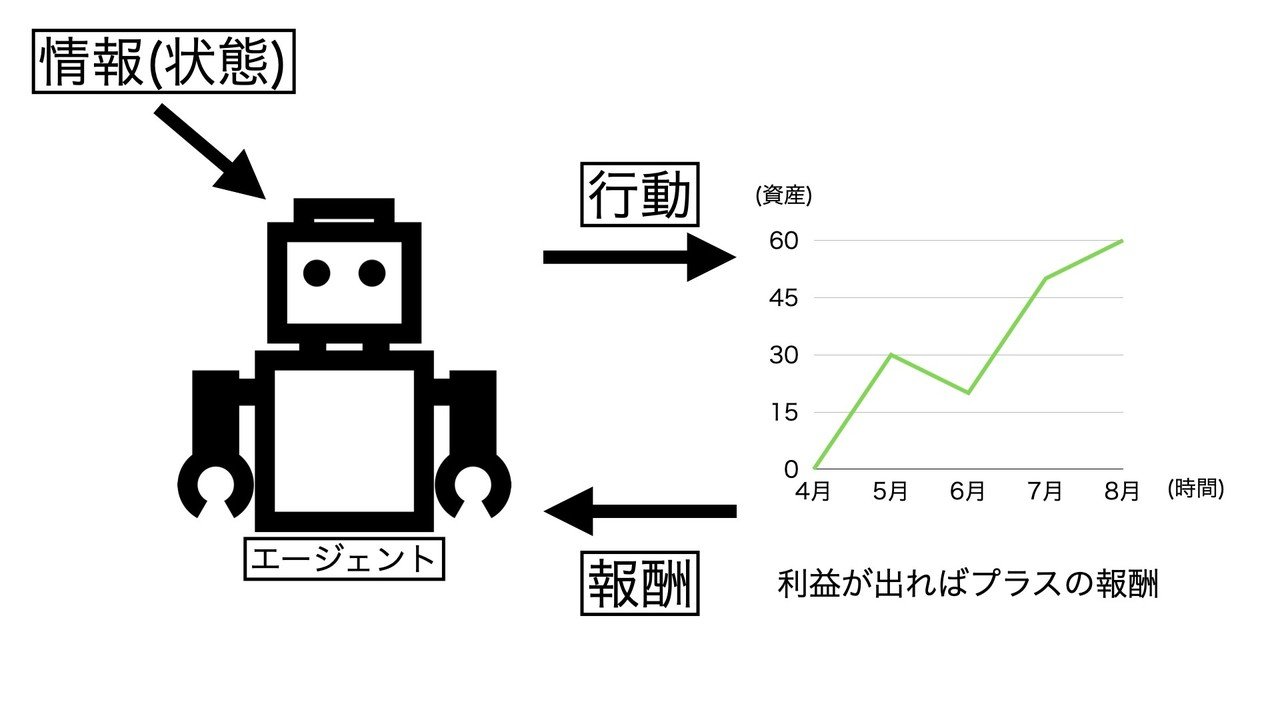
ここで、深層強化学習の応用方法の流れを説明します。トレードの仕方や目的によって設計は変わりますが、ここでは筆者が稼働させているBOTの応用方法について記述しています。
DQNでは、報酬を最大化するエージェントを作ります。この報酬は扱う環境や目的によって変わります。例えば”スーパーマリオ”であればゴールにたどり着くことが目的のため「右に進む」や「敵を倒す」が報酬になります。また”オセロ”であれば「自分の石の数」を報酬と置くことができます。
今回はトレーディングですので「売買損益」を報酬として設定します。売買損益を報酬に設定し、プラスの報酬である利益を獲得するようにエージェントに学習させれば今回の目的である「トレード資産を最大化するエージェント」を作ることができます。これを実装するためには、行動、報酬、環境、状態の設計をする必要があります。この4つの設定について1つずつ説明していきます。
・(1) 行動(action)
DQNを使用するには、まず行動を決める必要があります。行動を指定することでエージェントが動けるようになり、エージェントがその行動を組み合わせて戦略を立ててくれるようになります。
今回はトレーディングへの応用なので、エージェントには"BUY", "SELL", "HOLD" の行動をしてもらいます。"BUY", "SELL"は成行注文での行動です。
また、この3つの行動以外に、LOT数を変更するなど他の行動を増やすことは可能ですが、行動が多くなりすぎると学習が難しくなることが考えられるため、今回は単純に3つの行動に限定させています。
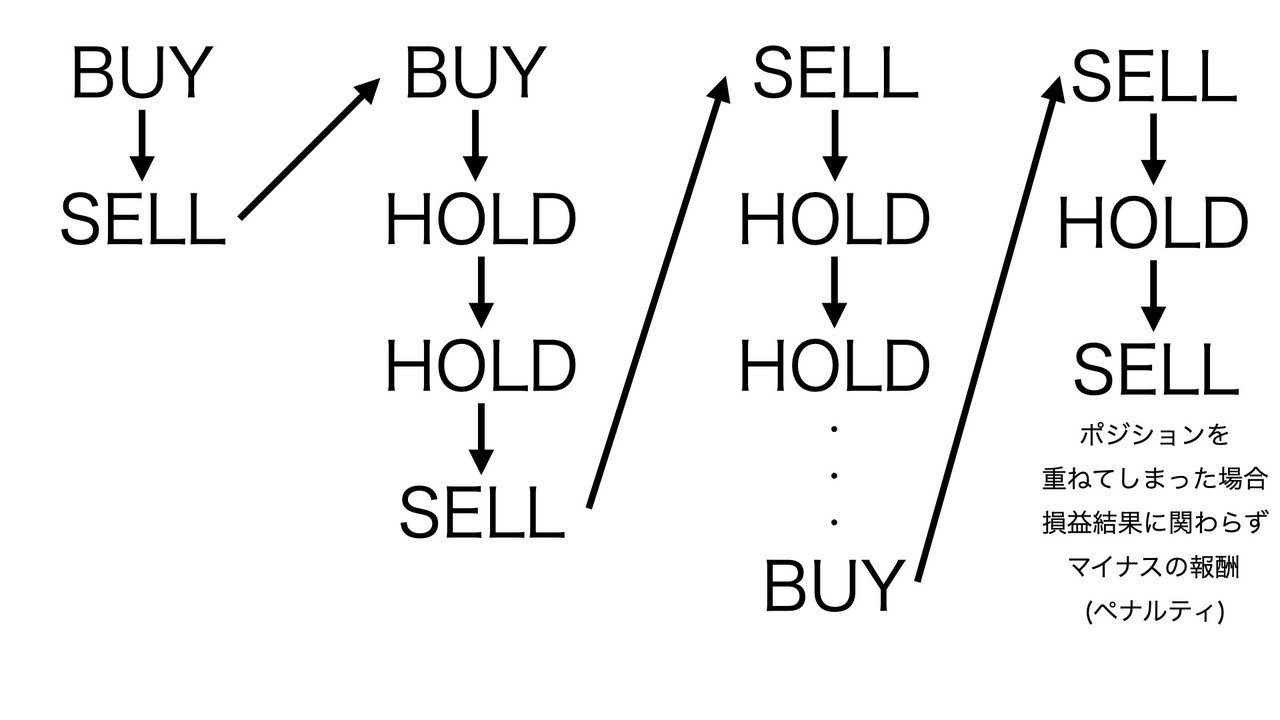
上図にあるように、例えば"BUY"をした後、次の行動で"SELL"を選択すればポジションが解消されトレードが完了します。
また"BUY"の後、次の行動で"HOLD"を選択すればポジションを持ったままになります。その"HOLD"の行動の後にまた"HOLD"を選ぶことができますが、"SELL"を選択するとその時点でトレードが完了します。
"SELL"から入った場合も同様に、"SELL"→"HOLD"or"BUY"のようなトレードの流れになります。
最後に、このままの行動設定では"BUY"を選択した後、次の行動でも"BUY"を選択することが可能になっています。エージェントには自由に行動してもらいたいのですが、ポジションを重ねてしまうとトレードが複雑になり、戦略の獲得が難しくなることが考えられます。
そのため、"BUY"の後に"BUY"や、"SELL"の後に"SELL"の行動をすることに対して規制をかける必要があります。そこで、報酬設計ではポジションを重ねるとマイナスの報酬が発生するように設定します。そうすると、エージェントは学習中にそれがダメなことだと学び、バックテストや本番環境では制御をすることが可能になります。
・(2) 報酬(reward)
次に報酬の設定です。報酬にはプラスの報酬とマイナスの報酬があります。エージェントはこの報酬を最大にしようと戦略を立てるため、良いことをしたらプラスの報酬、悪いことをしたらマイナスの報酬を与えることで制御していきます。
今回の目的はトレード資産を最大化することです。そのため(一例として)売買で利益がでたらプラスの報酬、損失がでたらマイナスの報酬を与えます。報酬を設定することでエージェントが"BUY", "SELL", "HOLD" の行動を組み合わせながら報酬を獲得して、最終的な収益が最大になるような行動をしようと頑張ってくれます。
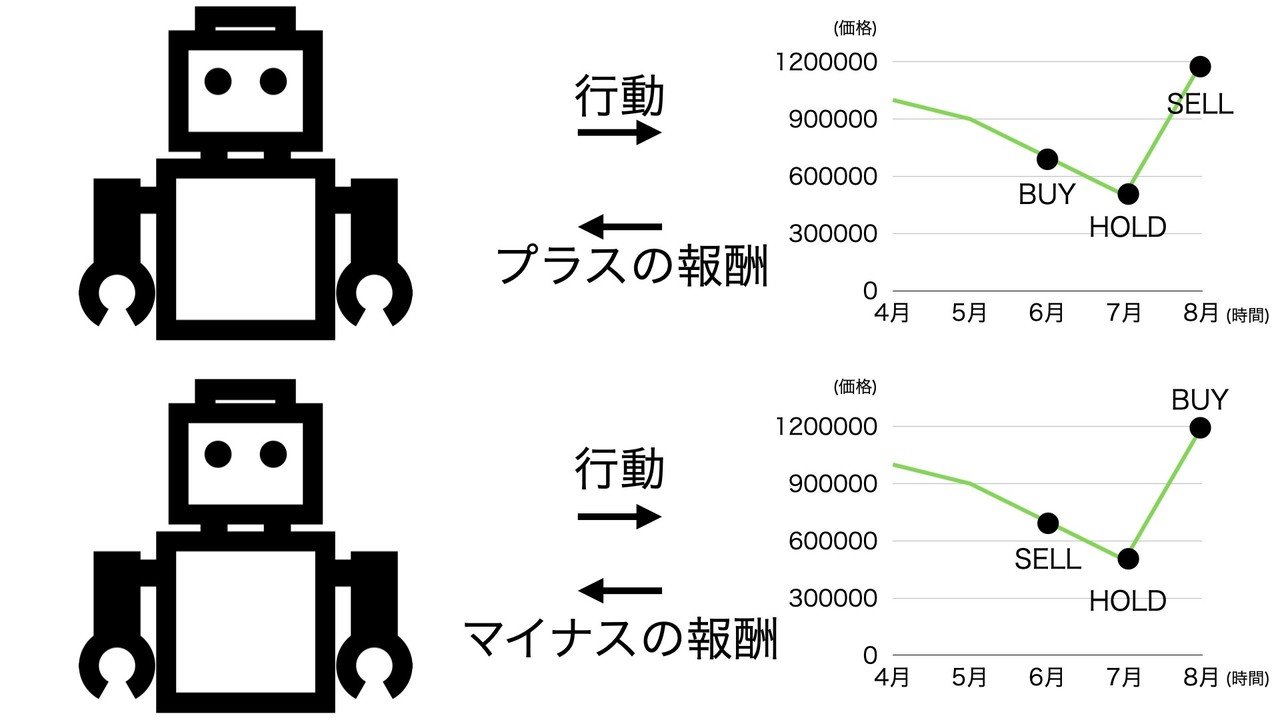
ここで報酬設定がある程度設定できたら、一旦エージェントを学習させてみます。このような単純な報酬設定ですぐに良い戦略が生成できれば良いのですが、エージェントはなかなか期待通りに動いてくれないと思います。エージェントが良い戦略を立てられない場合は、報酬の変更、追加、微調整を何度か試す必要があります。
適切な報酬を設定するためには、エージェントの行動履歴を可視化して補助的に報酬を追加したり、報酬の量を調節してみるとエージェントの動き方が変わってきます。また、強化学習を使って戦略が獲得できている他の環境(ゲーム環境など)の報酬パターンを参考にしてトレーディングに取り込んでみるのも良いと思います。
深層強化学習では報酬設定のチューニングが重要になってきます。報酬獲得までの道のりを長く設定してしまうと、エージェントがなかなか報酬を獲得できず学習に時間がかかってしまいます。また逆に、報酬の獲得機会を増やし過ぎてしまうと最終的な目的が達成できないまま、エージェントが途中の報酬を効率よく獲得しようと間違った努力をしてしまう可能性があります。報酬設定をする際は、ゴールまでの良い戦略を導いてくれるようにエージェントの気持ちを考え、優しい設計をする必要があります。
・(3) 環境(environment)
次に学習する環境を用意します。エージェントを行動させるフィールド作りです。エージェントは用意されたフィールド上で行動し報酬を獲得します。

今回のトレーディングでの環境はbitFlyer BTC-FXです。しかしながら、本番環境であるbitFlyer BTC-FXでいきなり学習させてしまうと、エージェントが良い戦略を学習する前に多くの損失を出してしまうことが考えられます。DQNの学習方法は、最初はランダムなアクションである程度データを集めていき、それからQ関数を更新していきます。
そのため上図にあるように、まずシミュレーション環境を用意し良いモデルができるまで学習させてから、一定期間バックテストでテストを行い、その後本番環境で実際に動かします。シミュレーション環境で使用する学習データは、バックテストのテストデータとは違う期間のデータを用意し、エージェントの性能を確かめる必要があります。また、テストデータとは別に用意してある検証データは、DQNのハイパーパラメータを調節するために使用します。
最終的に稼働させる実環境(bitFlyer BTC-FX)で、バックテスト通りの性能を発揮させるために、シミュレーション・バックテストの2つの環境は実環境に近いものを作成する必要があります。環境間に差があるとエージェントの行動に影響が出てしまいます。
・(4) 状態(state)
最後に状態を設定します。いわゆる説明変数、入力データの部分です。エージェントはこの情報をもとに行動の判断を行います。
状態の設定はエージェントに取らせたい行動や、行動頻度によっても変わってくると思います。良い特徴量を見つけ、エージェントが目的通りに動いてくれるように設定する必要があります。
6. 注意点

・(1) 行動の判断基準がわからない
深層強化学習を使う注意点として、入力データが多いとエージェントの売買行動の判断基準や判断理由がわからなくなります。エージェントがどの状態(入力データ)を手がかりにしてトレードを行っているかを把握できないということです。戦略のロジックが理解できていないと、エージェントがトレードで損失を出した時に、それが一時的なものなのか継続的なものなのかを判断できず安心してBOTを稼働し続けることが難しくなる場合があります。深層強化学習では、行動履歴と損益結果だけを頼りに良いエージェントを見つける必要があります。
・(2) 過学習
エージェントの学習データには過去の価格データを使用しています。
例えば、2019年の期間をシミュレーション環境で学習させるとします。何回もその期間を学習させれば、次第に良い戦略が見つかり利益を獲得できるようになります。さらにその期間で学習をさせ続ければ、もっと高いパフォーマンスで行動するエージェントが誕生します。しかし、学習データ期間の収益最大化だけを目指すことは実用上、全く意味のないことです。試しに2019年を完璧に学習したエージェントを2020年のデータで動かしてみると基本的には上手く収益が獲得できません。これは2019年を学習しすぎた、過学習を起こしているエージェントということになります。過学習を起こすと新しく与えるデータに対してはパフォーマンスの悪い結果が出てしまいます。
新しい期間で収益が獲得できなければ、実環境で稼働はさせられません。初めて見せる2020年の期間で最高の収益が出せるモデルを探す必要があります。(実稼働させる2021年以降の期間でも安心して運用できるように)
・(3) 実環境を再現する
環境の変化によりエージェントが期待通りに動いてくれないことがあります。シミュレーション・バックテスト・実環境は、エージェントにとって同じような環境を用意することが重要です。バックテストで良い成績が出ていても、実環境でエージェントに見せる状態の様子が違うと想定外の収益結果が出てしまいます。そのためバックテストと実環境の損益結果が近くなるまで環境整備をする必要があります。
実環境で、ある程度信頼できるエージェントができてから徐々にLOTを増やすことをおすすめします。
・(4) すぐに勝てるような戦略は生まれない
深層強化学習は設計がとても難しいです。戦略を見つけ出すのはエージェントの仕事ですが、設計をするのは人間の仕事です。この設計部分を上手く調整してあげないと、エージェントが良い戦略を獲得してくれることはほとんどありません。
例えば、深層強化学習トレーディングの学習を進めているとエージェントの戦略として「ずっと何もしない」という現象が時々現れます。トレードで負けないように頑張るあまり"HOLD"だけを選択してしまい「何もしなければ損をしない」と解釈してしまった結果です。
この他にもBUY注文からの行動しかしないエージェントや、ずっとポジションを解消しないエージェントもいました。このような現象はシミュレーション環境での学習中に起こります。
シミュレーション環境で良い成績が出せなければ、バックテストでテストする段階にもっていくことができません。
最初の関門として「シミュレーション環境で良い成績を出すこと」
次に「バックテストでも良い成績が出るような汎用性の高いエージェントを見つけること」
最後に「バックテストで良い成績が出るエージェントが今後の実環境でもそのパフォーマンスを保つこと」をクリアしていく必要があります。
7. メリット
深層強化学習トレーディングに対する期待を記述しています。現段階で実現できていないこともありますので、参考程度に見てください。
•(1) データ取得から利益確定までの戦略構築を任せられる
データ取得 → 分析 → 注文 → 分析 → 決済
深層強化学習を使用すると、この一連のトレード戦略を構築してくれます。エージェントに任せる部分が多いため、データ分析などの人間の負担する仕事を少なくすることが可能です。人間の介入が減ると、人工知能の自由な発想を生かすことができ、全く新しい未知の戦略の構築に期待することもできます。
しかし、実際はエージェントに与える報酬や情報の基盤は人間が考え、チューニングをする必要があるため、人間側には新たな仕事が増えることになります。
・(2) 実環境で成長させられる可能性がある
もし実環境で成長し続けるモデルができれば、BOTのメンテナンスが必要なくなるかもしれません。新しい期間で失敗しても、その失敗も学習できれば安心してBOTを放置することができそうです。
シミュレーション環境で学習させたエージェントがバックテストで良い成績が出たとしても、その後の実環境で良い成績が保ち続けられるとは限りません。実環境でもBOTが成長し続けることができればその問題を解決できる可能性がありそうです。
・(3) 未知の戦略を生成できる可能性がある
人間が発見していない新たな戦略を生成できる可能性があります。人工知能の考える新たな戦略からインスピレーションを得られるかもしれません。エージェントの判断基準や判断理由は直接的に人間にはわかりませんが、トレードしているところを実際に見たり、行動履歴を確認することはできます。エージェントのトレードを眺めることで、刺激をうけ、新たに人間がその戦略を発展させることができる可能性もあります。
・(4) 様々な戦略を得ることができる
人間は戦略を考えるために時間や体力を消耗しますが、深層強化学習を使えば、自動的にエージェントがたくさんの経験を積み戦略を考えてくれます。
戦略の生成工程として、行動、報酬、状態、及びハイパーパラメータなどを変更することで複数の異なる戦略のエージェントを生み出します。それらのエージェントの収益性をバックテストで確認し、最も良い成績のエージェントを選択することで、実環境で稼働するエージェントを1つ採用していきます。しかし、この選ぶ過程で採用されなかったエージェントの中にも、収益の出る個体が存在します。最も良い成績のエージェント以外にも、2番目、3番目に収益性がよかったエージェントには1つ1つ異なる戦略があるため、複数の戦略を得ることができます。
8. 成績
深層強化学習の応用方法やメリットを記述してきましたが「実際にトレードで収益が出せるのか」について、筆者が動かしている深層強化学習BOTのトレード収益を公開します。
2020年2月29日から2020年7月22日までの実際のbitFlyer BTC-FXでの深層強化学習BOTの損益結果です。初期の証拠金は40,000円、LOTは0.06btcで固定しています。行動は"BUY", "SELL", "HOLD"の3つだけです。
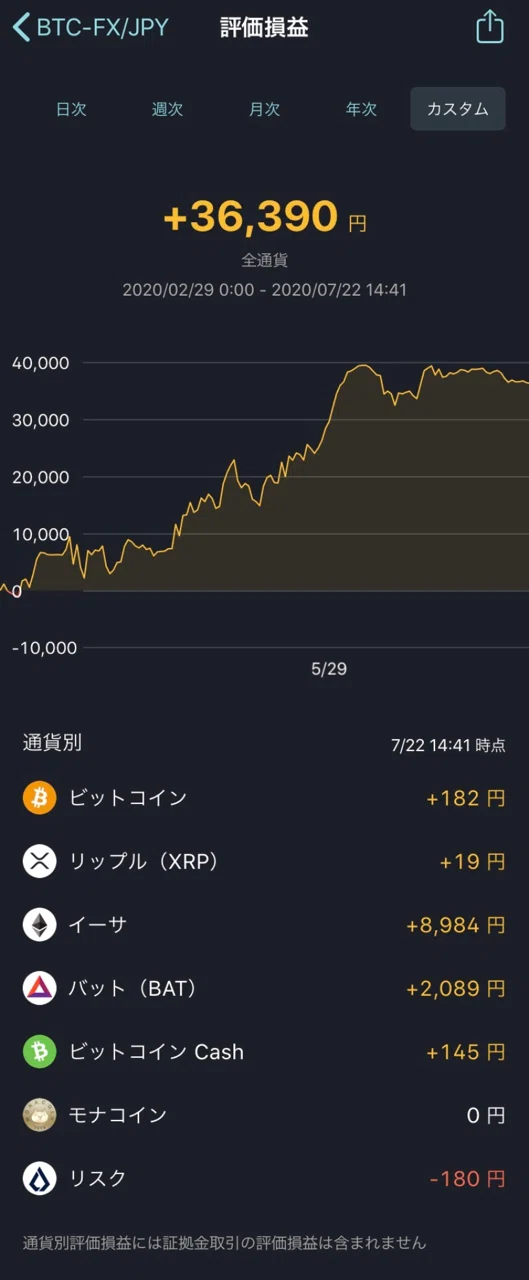
現物の損益結果を含んでいてわかりづらいですが、BTC-FXだけの利益は+25000円です。約5ヶ月の期間で63%のプラスの成績でした。深層強化学習を応用することで、少なくとも現段階では収益の獲得につながる戦略が生成できるようです。
※下図はBTC-FXのみの過去100日分の損益結果になります。

9. 実環境で成長するモデルを作る難しさ
・現段階で筆者は「実環境で成長するエージェント」は作成できていません
教師ありの機械学習ではある程度学習させた学習済みのモデルを使って、本番環境やテストデータに対してのターゲット予測結果を出します。予測結果を出す目的は、学習済みモデルの評価をして本番環境で使えるものかを把握するためです。そのため、評価中にモデルの学習は進行させず、テストデータでは評価のみを行います。評価中に学習済みモデルを成長させてしまうと評価の度に予測結果が変わってしまいます。
今回のモデルではエージェント自身の行動結果をもとに学習するため、事前に正解ラベルを用意する必要はありません。しかし、教師ありの機械学習と同じように更新を繰り返しながら成長するため、学習済みモデル(エージェント)を生成し、テストデータに対してのパフォーマンスを測定します。テストデータで評価をしている間にもエージェントを成長させることはできますが、評価のたびにエージェントの戦略が変わってしまい、正確なパフォーマンスを測定することができないため学習はフリーズさせます。(実環境でBOTが進化できるようにバックテストでも学習を進めてみましたが、うまくいきませんでした)
今のところ、シミュレーション環境で学習させたエージェントがバックテスト(テストデータ)でも良い成績を出せていれば実稼働をさせています。しかし、バックテストで用意した期間に対して良い成績が出ていただけで、今後も良い成績が出るとは限りません。BOTの完全放置は時間が経つにつれて不安になってきます。この問題を解決するためには実環境で進化していくBOTを作る必要があると考えられます。新しいデータで例え失敗しても、その失敗を学び続けてくれるなら安心して実環境でBOTを稼働させられそうです。
・ エージェントの学習と検証を自動化する
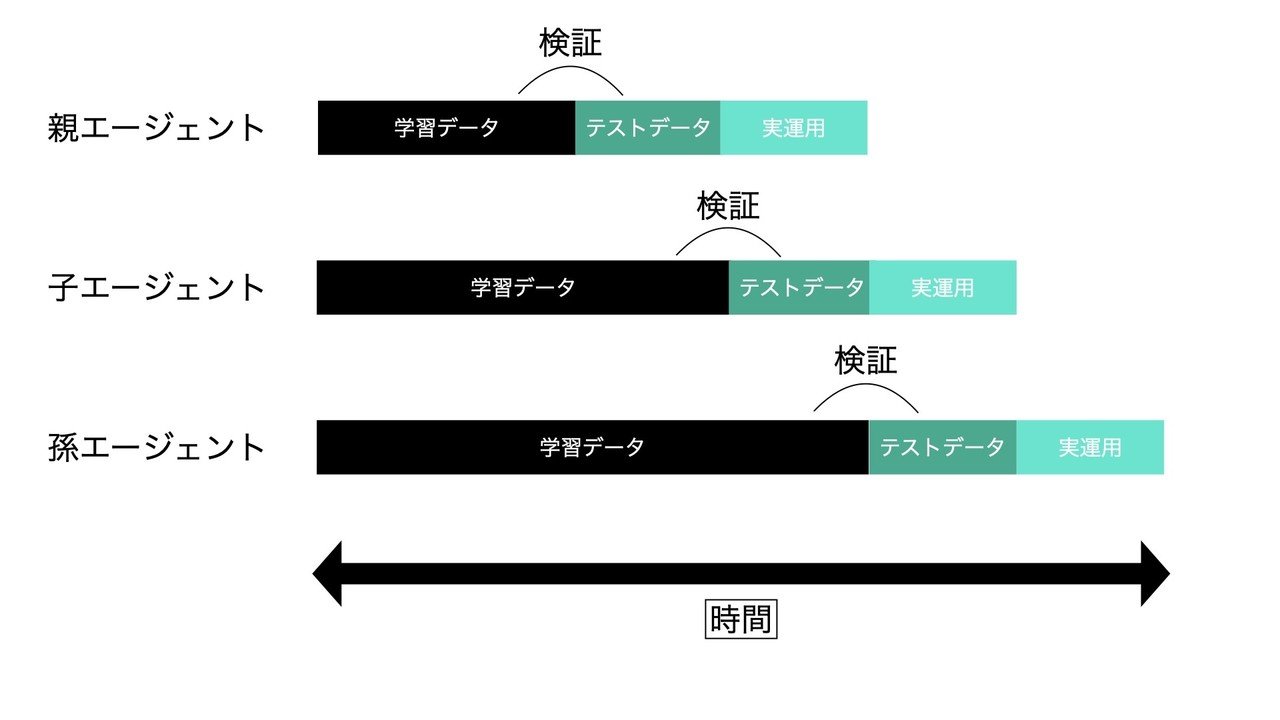
"実環境で運用している1つの親エージェント"と"その運用期間も含めて学習・検証を行わせた次世代の子エージェント"をある程度の期間で自動交換するシステムを作れば、実環境で成長するエージェントを作ることができます。自動的にシミュレーション(学習)とバックテスト(検証)を行い、現在稼働させているエージェントより優秀なものを見つけることができれば、それと交換することで実質成長させていることになります。
しかし、この方法を実現させるためには、各パラメータや報酬の調整なども自動化する必要があると考えられるため、学習・検証の繰り返しには相当な時間がかかります。
10. 過学習に対応するために
深層強化学習トレーディングでは、過学習に注意をする必要があります。「6.注意点 (2)」で説明したように、実環境のフィールドではエージェントは常に新しいデータに対応することになります。
・(1) データ量を増やす
過学習が起こる原因として、学習データが少ないことが上げられます。学習データが多ければエージェントは自然と汎化していきますが、学習データが少ないと過剰適合をしてしまう可能性が増します。これに対しては極力学習データの量を増やし、多くの期間を学習させる必要があります。
・(2) 学習データの中身を確認する
「上昇相場の多い学習データ」のような似たデータが集まると"BUY"注文の行動ばかりするエージェントが生まれてしまい、実環境での下落相場では期待通りのパフォーマンスが発揮できないことが考えられます。学習データの中身はしっかり確認し、データに偏りがないかをチェックする必要があります。
・(3) 適切なタイミングで学習を止める
機械学習では、過学習が起こる手前で学習をストップさせることで、テストデータに対して汎化性能の高いモデルを作成することがあります。今回の深層強化学習トレーディングでも汎化性能を落とさないように、学習が進む度にテストデータに対するパフォーマンスを確認します。
ここで学習が進む度というのは、学習データを一巡する”1エポック”ごとではなく、Q関数が更新されるごとなどの小さな期間で検証する必要があります。学習データ量が大きいと、学習データを1周する間に、検証データやテストデータに対して高いパフォーマンス成績のエージェントが生成されている可能性があるからです。
・(4) モデルを単純にする
ネットワークのモデルが複雑で自由度が高いと、学習データに特化したエージェントが生成されてしまう可能性があります。表現能力の高いネットワークは、学習すればするほど訓練時のデータに過剰適合してテストデータへの対応が困難になります。テストデータに対してのパフォーマンスが悪ければ、単純なモデルへの変更を検討する必要があります。
•(5) 汎化性能を高める理由
例えば強化学習を用いた「スーパーマリオ」で素早くゴールにたどり着くという目標を達成したいとします。まず、エージェントであるマリオは最初のステージである"1-1”を繰り返し何時間か学習します。その後、最終的にマリオが"1-1"を目標通り素早くゴールにたどり着くことができれば、目標は達成ということになります。
しかしトレーディングでは、"1-1”だけを何度か学習させた後、敵や障害物の配置の違うステージである"1-2"でもゴールにたどり着くように調整しなければいけません。
トレーディングでは与える学習データ期間に全ての値動きパターンが含んでいるとは限らず、未来には全く新しい値動きパターンが起こることが考えられます。トレーディングに深層強化学習を応用する際は、実環境に対応させるために汎化性能を高める必要があります。
11. "HOLD"しか選択しない問題
・(1) ε-greedy法
今回の方法のような3つの行動でエージェントを学習させていると、"HOLD"しか行動しないエージェントが生まれることがあります。エージェントは「"HOLD"を選択する方法」が最も良い戦略と勘違いしている可能性があります。
これを防ぐためには、たまにランダムな行動を入れて、何もしないことをやめさせます。ランダムな行動でまれに報酬がもらえれば、軌道修正することが可能になります。
DQNでは初期のQ値に依存しないように、ε-greedy法を使うことがあります。ε-greedy法はQ値という探索で得た知識を生かす行動と、色々とランダムに行動してみる行動を混ぜるために使われます。このε-greedy法を、学習初期は大きな発生確率に設定し、学習が進むごとに小さな発生確率にしていくことで効率的に最適な行動を獲得してくれます。
このε-greedy法を用いることで"HOLD"しか行動しないエージェントを強制的に刺激させることができ、"HOLD"以外の新しい行動を取れるようになります。
・(2) 報酬設定を見直す
報酬の追加や報酬量の調整することで"HOLD"以外の行動を取ってくれるようになります。例えば「"HOLD"を長期間しているとマイナスの報酬が発生する」や「ポジション発生時のプラスの報酬を与える」など、報酬設定は工夫次第でいくつも組み合わせを考えられます。「5.方法 (2)報酬」にあるような方法で色々調節してみることで、3つの行動を組み合わせて収益を獲得してくれるようになります。
12. 良いエージェントを見つける
生成された複数のエージェントから良いエージェントを見つけます。
良いエージェントとは、同じ期間で比べたときに収益が多く、下落幅の小さい安定した個体のことです。
バックテストでの収益と最大下落幅を数値で出力し複数のエージェントから良いエージェントを選択します。また損益推移のグラフをプロットすると視覚的にも判断しやすくなります。
ここで最も良さそうなエージェントを選択しますが、実環境では遅延やバックテストにはないエラーが起こることがあります。また今回はエージェントの行動が成行注文のため、実環境では想定外の価格で約定してしまう場合があることも考えられます。そのため、実環境の損益結果とバックテストの損益結果がほぼ同じになるまで環境の整備をしてから、最終的にエージェントを選択する必要があります。
ある程度実環境との結果を近づけるために「注文時に少し不利な価格で約定させる」などをしてエージェントが負荷に耐えれるかを試しました。
バックテスト環境と実環境の差が十分少なければ、バックテストのような良い収益結果が実環境でも出せると思いますが、より安全に良いエージェントを見極めるために、少額のLOTでエージェントの行動を観察する期間を設けるチェックすると良いと思います。
13. その他の項目
本noteでは、筆者が実際に稼働させている深層強化学習BOTについて一部の情報を記述しました。
・活用データ
・報酬の設定
・状態の設定
・行動頻度
・各ハイパーパラメータ
・理想のモデル(今後の課題)
上記の項目については本noteには詳しく記述していません。(公開するかは検討中です)
最後に
検証結果と学びをアウトプットするためにnoteを書きました。
手がかりの少ない状態での深層強化学習トレーディングの実装は、エージェントの学習と検証がかなり難しく、実環境での検証期間を合わせると約2年ほど時間がかかりました。収益はプラスですが、納得のいくモデルはまだ完成できていないので、これからも開発を続けるつもりです。
今回使用したアルゴリズムはDQNでしたが、DQNより良いスコアの出る深層強化学習のアルゴリズムが出ていると思います。新しい技術を組み込むことでさらに収益性の高いエージェントが作れる可能性があります。このnoteを参考に深層強化学習に興味を持つ人が増えると嬉しいです。
Twitter (@dropQtuning)
この記事が気に入ったらサポートをしてみませんか?