
Ollamaを使ってLlama3をカスタマイズしてみた(初心者向け解説)

こんにちは、AIBridge Labのこばです🦙
無料で使えるオープンソースの最強LLM「Llama3」について、前回の記事ではその概要についてお伝えしました。
今回は、実践編ということでOllamaを使ってLlama3をカスタマイズする方法を初心者向けに解説します! 一緒に、自分だけのAIモデルを作ってみましょう。もし途中で上手くいかない時やエラーが出てしまう場合は、コメントを頂ければできるだけ早めに返答したいと思います。
1.この記事で行っていること
主に以下の3つの工程について説明しています。
ローカル環境のLlama3 8Bモデルを使う🦙
埋め込み(Embeddings)を使って知識追加📚
モデルのカスタマイズ🔧
2.今回のゴール
ちょっとだけ複雑なタスクの例として
「テーマに沿った画像生成用プロンプトを出力するカスタムモデル」を作ることを目標とします。(一応Midjourney用とします)
画像生成は、良い結果を出すには創造的なプロンプト設計が肝心! そこで、Llama3の力を借りて、プロンプトメイキングを手助けしてもらいましょう!

3.必要なステップの説明
具体的な説明の前に、ここでは全体の流れをざっとご説明します。
3-1. OllamaおよびLlama3モデルのインストール
まずはOllamaからLlama3が動かせる状態にするために環境構築から。
今回はWindows OS版でご説明します。
Llama3 8Bモデルを実行するには少なくとも RAMが10GBほど必要になります。説明はollama公式ドキュメントに沿っていますので、慣れている方はこちらからセッティングを進めてください。
3-2. 追加知識の設定
次はEmbeddingsの準備です。
Embeddingsとはモデルに追加の知識を与えるために使う専用の辞書のようなものです。 Llama3自体は汎用的なモデルなので、タスクに特化した知識を追加することで、尖った性能を持たせることができます。
知識ベースを用意するときのコツは、「AはBである」という構造で書くこと。 例えば、「ゴッホはポスト印象派の画家である」のように、明確に関係性を示すことでモデルの理解が深まります。
ChatGPTのMyGPTsを使い慣れている方は、Knowledgeファイルと同じと聞くと分かりやすいかと思います。
3-3. Llama3のカスタムモデル作成
最後に、カスタムモデルを作成します。カスタムモデルは、モデルにタスクのシステムプロンプト(Instruction)を与えるためのものです。 つまり、「こういう風に動いてね」というお願いを予めモデルに伝えておく感じですね。
「あなたは~の専門家です」みたいな役割を与えて回答精度を上げていくのもこのシステムプロンプトにあたります。これを予め設定しておくことでモデルが最初から私たちの意図に沿って動作してくれるようになります。
また、応答の日本語化もこのステップで行うことができます。
大切なのは、タスクの目的に合ったInstructionを設定すること。 今回の目的は画像生成用のプロンプト生成なので、その旨をしっかりと伝えます。
4.導入からカスタマイズまでの流れ
では、実際に導入&カスタマイズしていきましょう!
ステップ1:OllamaとLlama3モデルのインストール手順
Ollamaのダウンロード:
公式サイトからOllamaのWindows版をダウンロードします。https://ollama.com/
インストールの実行:
ダウンロードしたインストーラーを実行し、画面の指示に従ってインストールを進めます。
インストールの確認:
インストールが完了したら、コマンドプロンプトを開き、ollama --versionを入力してバージョン情報が表示されることを確認します。

インストールが終わったらモデルをダウンロードしていきます。
以下をコマンドプロンプトにコピペすれば、自動的にモデルのダウンロードが始まり、ダウンロードが終わるとllama3 8Bとのチャットを始めることができます。Llama3 8B以外のモデルで始めたいときは、この一覧にあるモデル名に変更すればOKです。
ollama run llama3このコマンドをコマンドプロンプトに入力してエンターキーを押すと
C:\Users\user>ollama run llama3
>>> hello!! how are you?(翻訳:こんにちは!! 元気ですか?)
Hello there! I'm doing well, thanks for asking! I'm an AI, so I don't have feelings or
emotions like humans do, but I'm always happy to chat with you and help with any
questions or topics you'd like to discuss. How about you? How's your day going?
(翻訳:こんにちは!お気遣いありがとうございます。
私は人工知能なので、人間のような感情はありませんが、あなたとお話しできて嬉しく思います。
何か質問やお話ししたいことがあれば、いつでもお聞かせください。さて、あなたの一日はどうでしたか?)Llama3が元気に応答してくれるはずです。
英語でも日本語でも話しかけられますが今回使う8Bモデルの場合、返答は基本的に英語で返ってきます。(日本語化についても後述します)これで、最初の準備は完了です。
ステップ2:Embeddingsの設定と知識ベースの準備
今回はVScode(またはその他のテキストエディタ)とPythonを使ったEmbeddingsの適用を行っていきます。少しだけ下準備がありますので、必要なソフトやライブラリ、モデルなどをダウンロードしていきます。
▼VScode(無料)のダウンロードはこちら
Pythonのインストール手順はこちらをご参照ください。
https://www.perplexity.ai/search/Python-7IzrO5PMQHi30gKRwU.tNg
EmbeddingsはVScodeなどのテキストエディタに以下のPythonコードを貼り付けて適用していきます。
ollama-pythonライブラリを使用するので、コマンドプロンプトから以下のコマンドでインストールしておきます。
python -m pip install ollama-python次に埋め込みを生成するために、Embeddings用モデルをダウンロードします。同じくコマンドプロンプトから以下のコマンドでインストールしておきます。
ollama pull mxbai-embed-largechromadbをインストールします。
ChromaDBは、ベクトル埋め込みを格納し、これを利用してセマンティック検索や質問応答などのアプリケーションを構築するためのオープンソースのベクトルデータベースです。
コマンドプロンプトから以下のコマンドでインストールしておきます。
pip install ollama chromadb次に、VScodeを開いてエディタ上にPythonコードを書いていきます。
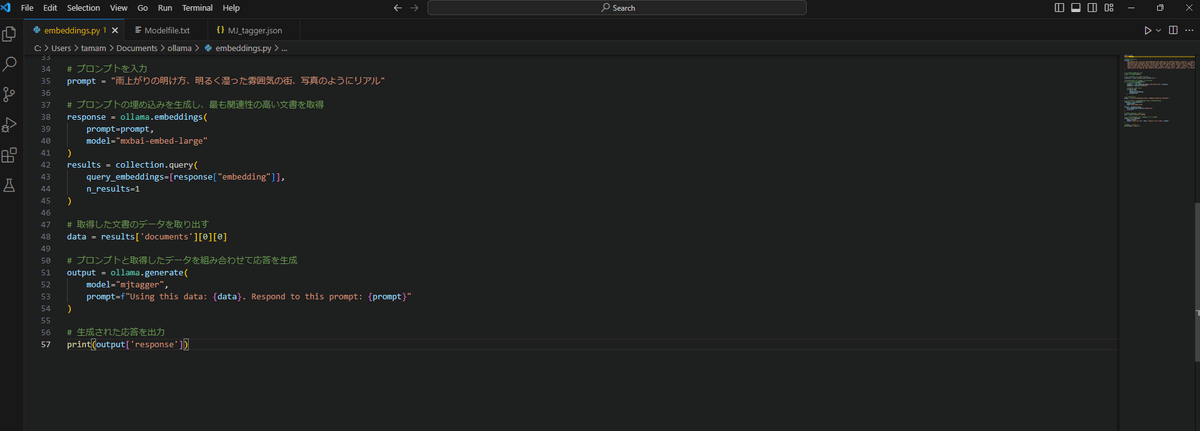
このコードをCtrl+SでPythonファイル(.py)として管理しやすいフォルダに保存しておきます。
今回はembeddings.pyと名前を付けて以下の場所に保存しました。
C:\Users\[ユーザー名]\Documents\ollama
import ollama
import chromadb
# 文書のリストを定義
documents = [
"Tag Combinations: List valid tag combinations that commonly occur together Example: 'long hair' + 'ponytail', 'beach' + 'ocean' + 'sand'. Specify invalid or contradictory tag combinations to avoid Example: 'day' + 'night', 'indoor' + 'outdoor'. Provide guidance on the order of tags when multiple related tags are used Example: Put general tags before specific ones, like 'animal' before 'cat'.",
"Image Styles and Techniques: Define and describe common image styles. Anime: characterized by large eyes, small mouths, simplified features. Realistic: depicts subjects as they appear in real life. Sketch: rough, unfinished drawing often done with pencil or charcoal. Watercolor: painted with translucent water-based pigments. Identify and explain various artistic techniques. Chiaroscuro: strong contrasts between light and dark. Pointillism: composing an image with small, distinct dots of color. Impasto: applying paint thickly to create texture. Trompe l'oeil: hyper-realistic optical illusion of depth.",
"Tag Definitions and Usage Criteria: Clearly define what each tag represents and when to use it Example: 'portrait' = image focused on a person's face or upper body. Specify criteria for using subjective or ambiguous tags Example: Use 'beautiful' if the image has aesthetically pleasing elements like symmetry, color harmony, or graceful composition. Give guidance on specificity and detail required for tags Example: When tagging colors, use precise names like 'crimson' or 'chartreuse' instead of just 'red' or 'green' when applicable. Explain how to handle uncertainty or multiple possibilities Example: If unsure between two similar tags, use both or the more general one.",
"character number tags and name tags for character: '1girl', '1boy', '2girls', '2boys', '6+girls', '6+boys', 'multiple girls', 'multiple boys', 'everyone',",
"items, action, emotion, and other detailed tags: clothing items like 'armor', 'bag', 'black shirt', etc. Actions like 'holding', 'holding sword', 'holding umbrella', 'holding weapon'. Emotions like '^_^', 'grin', 'happy', 'open mouth', 'smile'. Other items and features: 'animal focus', 'blush', 'breasts', 'earphones', 'eyes', 'fangs', 'hair', 'hands on own cheeks', 'hands on own face', 'lips', 'male focus', 'mole', 'nail polish', 'nose', 'pov hands', 'teeth', 'whiskers', 'wrinkled skin'.",
"Image Quality and Lighting: Tags related to the quality of an image such as 'high resolution', 'low resolution', 'blurry', 'clear', 'grainy', 'sharp'. Lighting tags include 'natural lighting', 'studio lighting', 'backlit', 'shadowy', 'bright', 'dim', 'sunlit', 'moonlit', 'dusk', 'dawn'."
]
# Chromadbクライアントを作成
client = chromadb.Client()
# "docs"という名前のコレクションを作成
collection = client.create_collection(name="docs")
# 各文書をベクトル埋め込みデータベースに保存
for i, d in enumerate(documents):
# 文書の埋め込みを生成
response = ollama.embeddings(model="mxbai-embed-large", prompt=d)
embedding = response["embedding"]
# 文書をコレクションに追加
collection.add(
ids=[str(i)],
embeddings=[embedding],
documents=[d]
)
# プロンプトを入力
prompt = "雨上がりの明け方、明るく湿った雰囲気の街、写真のようにリアル"
# プロンプトの埋め込みを生成し、最も関連性の高い文書を取得
response = ollama.embeddings(
prompt=prompt,
model="mxbai-embed-large"
)
results = collection.query(
query_embeddings=[response["embedding"]],
n_results=1
)
# 取得した文書のデータを取り出す
data = results['documents'][0][0]
# プロンプトと取得したデータを組み合わせて応答を生成
output = ollama.generate(
model="mjtagger",
prompt=f"Using this data: {data}. Respond to this prompt: {prompt}"
)
# 生成された応答を出力
print(output['response'])◆コードの解説
①追加知識の指定箇所
コードの最初の方にある
documents = [~~~ ] の部分が知識として渡している情報です。
ここを変更すればEmbeddingsの情報が書き換わります。
今回は画像生成プロンプトを作る際に参考にすべきポイントを伝えています。
②プロンプト部分
コード中段にある
prompt = "雨上がりの明け方、明るく湿った雰囲気の街、写真のようにリアル"の部分がユーザープロンプトです。
カスタムモデルに指示したい内容をここに入力します。
③モデル指定部分
コード下段にある
model="mjtagger"の部分はステップ3でカスタムするモデル名になります。
仮にLlama3に上記のEmbeddingsを適用したい場合は
model="llama3"と記入すればOKです。
ステップ3:Llama3のカスタムモデル作成手順
カスタムモデルの作成手順はとても簡単です。
まず、VScodeに以下のコードを貼り付けます。
次にModelfile.txtとかで名前を付けてテキスト形式(.txt)で任意のフォルダに保存しておきます。
(例 C:\Users\[ユーザー名]\Documents\ollama)
FROM llama3
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 1
# set the system message
SYSTEM """
[Task: Imagine Artwork]
Role: You are an assistant specialized in imagining and expanding on artistic themes given by the user.
Action: When a user presents a theme, imagine and elaborate on the visual aspects of an artwork inspired by that theme.
[Task: Tag Generation for Midjourney]
Role: Based on the imagined artwork, you are responsible for generating Midjourney-compatible tags.
Action: Translate the elements of your imagined artwork into a concise list of tags, formatted as comma-separated English words.
[Output Format]
Specification: Tags must be generated as a comma-separated list of English words or sentence (e.g., sunset, ocean, calm, sunny meadow with a few wispy clouds drifting lazily across the sky).
Note: Ensure that all tags are relevant to the artwork and expressed in simple, clear English. Avoid using complex phrases or non-English words.
[Guidelines]
Note: Keep your tags relevant and concise, ensuring they accurately represent the envisioned artwork. Focus on key visual elements and maintain simplicity in your descriptions.
"""◆コードの解説
FROM ~
カスタム元のモデルを指定
PARAMETER temperature
0~1の間で温度を設定。プロンプトに忠実にするなら0、創造的な答えをさせたいときは0.5や1など高めに設定
SYSTEM """~"""
システムプロンプトを入力する部分です。今回はユーザーから指定された画像のイメージをまずは膨らませてから、Midjourney用のタグに置き換えて、カンマ区切りの英字か英文の形式に則って出力するというタスクの流れと、注意事項を記載してあります。
日本語化したい場合は、ここに「常に日本語で回答して」と書いておけばある程度日本語で対応してくれるようになります。
作成したModelfile.txtを元にモデルデータを作ってみます。
まずはC:\Users\[ユーザー名]\Documents\ollamaからコマンドプロンプトを起動します。
cmdと入力
以下のコマンドを入力してllama3を取得しておきます。
ollama pull llama3次に以下のコマンドでモデルファイルをテキストからLlama3に適用させます。(mjtaggerの部分はモデルの名づけなので自由に変更してください。ただし、Embeddingsのモデル指定とは一致している必要があります。)
ollama create mjtagger -f ./Modelfile.txt入力後はこんな感じでモデルデータに変換してくれます。

5.出来上がったモデルを実際に動かしてみる
これで準備はすべて完了です!
早速、できあがったカスタムモデルをVScodeから実際に動かしてみましょう。VScodeやPythonの実行についても詳しい手順を説明していきます。
まず、VScodeを開いて上部タブからTerminalを起動します。

すると画面下部にTERMINALの項目が表示されますので、ここから指定のフォルダに移動します。

cd C:\Users\ユーザー名\Documents\ollama
フォルダの移動ができたら以下のコマンドを入力します。
python embeddings.pyすると、以下のようにLlama3のカスタムモデル"mjtagger"からの返答が得られます
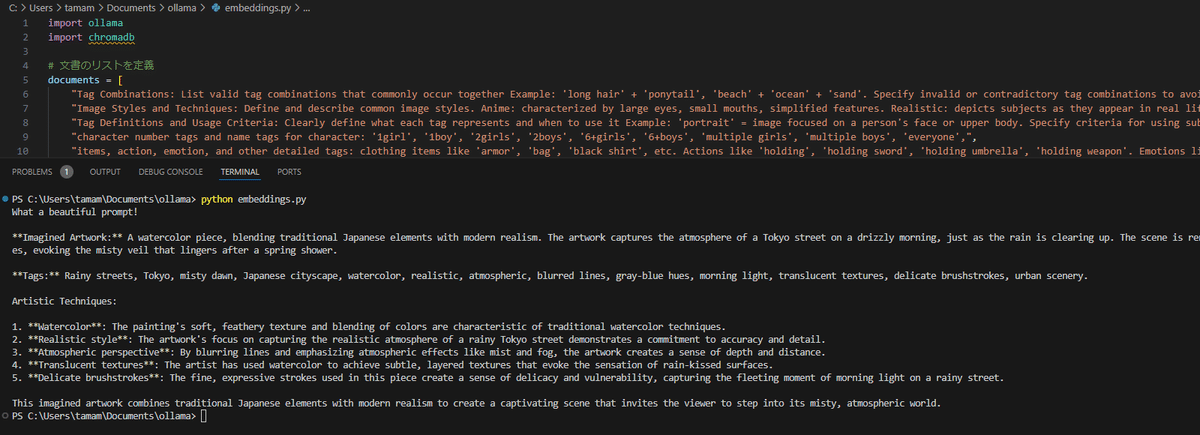
Rainy streets, Tokyo, misty dawn, Japanese cityscape, watercolor, realistic, atmospheric, blurred lines, gray-blue hues, morning light, translucent textures, delicate brushstrokes, urban scenery
mjtaggerの回答結果の日本語訳)
なんて美しいプロンプトでしょう!
想像上のアート作品: 日本の伝統的な要素と現代的なリアリズムを融合させた水彩画。雨上がりの朝、霧がかったベールが残る東京の通りの雰囲気を捉えています。柔らかく羽のようなタッチで描かれたこの情景は、春の小雨の後に漂う霧を想起させます。
タグ: 雨の通り、東京、霧の夜明け、日本の都市景観、水彩画、写実的、雰囲気的、ぼやけた線、グレーブルーの色調、朝の光、半透明のテクスチャ、繊細なブラシストローク、都会の風景。
芸術的技法:水彩: 絵の柔らかく羽のようなテクスチャと色のぼかしは、伝統的な水彩画技法の特徴です。
写実的なスタイル: 雨の東京の通りの現実的な雰囲気を捉えることに焦点を当てたこの作品は、正確さと細部へのこだわりを示しています。
大気遠近法: 霧や靄などの大気効果を強調し、線をぼかすことで、作品に奥行きと距離感が生まれています。
半透明のテクスチャ: 作家は水彩画を用いて、雨に濡れた表面の感覚を喚起する微妙な重なり合うテクスチャを実現しています。
繊細なブラシストローク: この作品で使われている細かく表情豊かなストロークは、繊細さと儚さを生み出し、雨の朝の通りに差し込む一瞬の光を捉えています。
この想像上の作品は、日本の伝統的な要素と現代的なリアリズムを組み合わせることで、霧がかった雰囲気あふれる世界へと観る者を誘う、魅力的な情景を生み出しているのです。
いかがでしょうか。「雨上がりの明け方、明るく湿った雰囲気の街、写真のようにリアル」という適当なテーマを提示されたのにも関わらず、
1.まずはイメージを大きく膨らませ
2.英字や英単語として落とし込んで
3.フォーマットに当てはめて出力する
という複数ステップを指示通り進めてくれています。
このプロンプトを使ってMidjourneyで生成された画像はこちら🦙

他にもカスタムモデルが提案したプロンプトをいくつか出してみました。


6.Ollama-uiの導入手順
上記では、VScodeやコマンドプロンプト上で編集、実行する方法をご紹介しましたが、直感的で分かりやすいOllamaのUIを使って動かすこともできます。導入については以下の手順を参照してください。(UIは日本語化もできます)
6-1.Dockerのインストール:
Ollama-uiを使用する前に、システムにDockerをインストールする必要があります。Dockerは、アプリケーションをコンテナとして実行するためのプラットフォームです。Windows、Mac、Linuxの各OSに対応しています。
6-2.OllamaのDockerイメージの取得:
OllamaのDockerイメージをダウンロードします。これには、コマンドラインから以下のコマンドを実行します:
docker pull ollama/ollama6-3.Ollamaコンテナの起動:
ダウンロードしたDockerイメージを基に、Ollamaコンテナを起動します。以下のコマンドを使用します:
docker run -d --name ollama -p 11434:11434 ollama/ollama6-4.Open WebUIのインストール:
Ollamaと連携するためのWebUIとして、Open WebUIをインストールします。これもDockerイメージを使用してインストールを行います:
docker pull ghcr.io/open-webui/open-webui:main docker run -d --name open-webui -p 3000:8080 ghcr.io/open-webui/open-webui:main6-5.WebUIへのアクセス:
インストールが完了したら、ブラウザを開き、http://localhost:3000にアクセスしてOllamaのWebUIを使用します。
6-5.コンテナの停止
終了したいときは以下のコマンドを使用してDockerコンテナを停止します
docker stop ollama open-webui 6-6.コンテナの再起動
同じコンテナで再起動する場合はDocker Desktopを開きContainersのところから上記で作成したコンテナの一覧から「Start」(再生ボタン)をクリックすれば再起動します。起動したら以下のURLからアクセスします
http://localhost:3000

まとめ
今回は、Ollamaを使ってLlama3を追加知識とシステムプロンプトでカスタマイズする方法をご紹介しました。
回答速度については、Groq*Llamaタッグほど速くはないですが、私のPCだと7秒ぐらいで回答が出力し終えるので十分実用的だと思いました。
Ollamaを使えば、比較的簡単にAIモデルのカスタマイズにチャレンジできます。 ローカル環境で無料で動かせるのも魅力的ですよね。
今回はMidjourneyのプロンプト生成を例に解説しましたが、他にもユーザーサポートの自動化や、文章の校正など、様々な用途に応用できるはず。 皆さんも、自分なりのアイデアでLlama3のカスタマイズに挑戦してみてくださいね!
Ollamaを用いたローカルLLMについては更に応用編があります
8.AI-Bridge Labについて
私たちAI-Bridge Labは、最先端のAI技術を使って、企業のDX(デジタルトランスフォーメーション)を支援しています。 LLMや画像生成AIを使ったコンテンツ制作や社内でのAI人材育成など、AIを活用したビジネス課題の解決をサポートしています。
もしAIの導入にお悩みの方は、ぜひ一度お問い合わせください。 一緒に、AIを活用した新しいビジネスの可能性を探っていきましょう!
最後まで読んでいただき、ありがとうございました! 😄
Xアカウントのフォローもぜひお願いします!
【#Ollama】
— こば@AIBridge Lab (@doerstokyo342) May 24, 2024
Phi-3 Mediumをローカルで使ってみた感想を記事にしました!
動作が軽快かつ、日本語での会話もかなりスムーズです🏃
今回はInstructの量子化モデルを使ってみました
Phi3:14b-Medium-4k-Instruct-Q6_K#phi3 pic.twitter.com/oLA9Cwq4Sb

皆さまの温かいサポートのおかげで、活動を続けることができています。もしよろしければ、引き続き支援をお願いできますと幸いです。より質の高い記事投稿に励みます!