フリーソフト&ノンコーディングでWebページ掲載情報をExcelに整理する方法

はやくも9月になり、私の母校ではそろそろ修論に向けたデータ収集や分析が本格化する時期です。
各省庁や業界団体がまとめて発表してくれている統計データも貴重なのですが、市場の生データとしては、ニュースサイトや価格情報比較サイト、口コミサイトなど、データを一覧できるWebページの情報もおもしろかったりします。
こうしたサイトから一括でデータを取り出すには、比較的簡単なプログラムを書いてWebスクレイピングを行うのが一般的です。とはいえ、たかだか数百件のデータを取り出すのにプログラミングをするのは煩雑ですし、ましてや非エンジニアにはハードルが高すぎます。
そこで、プログラミングすることなく手軽にWebのデータを整理するために普段使っている小技をまとめてみました。
ハーバード・ビジネス・レビュー(HBR)のバックナンバーページを例にやり方を紹介します。
<ご注意>
もちろん、Pythonなどでプログラミングができれば、もっと効率よくできます。
この小技は、
・プログラミング言語を触ったことがない
・PCにプログラミング環境を用意できない
・特定のWebページにある、たかだか数百件程度のデータを手っ取り早く表にしたい
…という人向けです。
概要

Webページのテキストをまるっとコピーして、テキストエディタ上で正規表現を使って整形、Excelに貼り付けるだけです。
この一文を読んですぐにやりかたを想像できる人には、これからご紹介する方法ではなく、せめてGoogle スプレッドシートのImportxml()関数を使った方法にチャレンジすることをおすすめします。
逆に「何を言っているのかわからない」という方へは、少し覚えないといけないことがあるので、順を追って説明します。
必要なツール
Sakura Editor や秀丸エディタ、CotEditorなど、正規表現を使って文字列検索・置換ができるプレーンテキストエディタが必要です。これらはいずれもフリーソフトとして使用することができます。
Windowsの方への個人的なおすすめはSakura Editorです。
ちなみに、Windows OSに最初からインストールされているメモ帳やワードパッドでは、正規表現を使った検索ができません。WORDも正規表現を使った検索・置換ができるのですが、さまざまな書式設定を自動で行ってしまうため、純粋に文字列だけを扱いたい場合にはかえって煩雑になってしまいます。
まずはプレーンテキストエディタをインストールしましょう。
テキスト→Excel表化の基礎知識
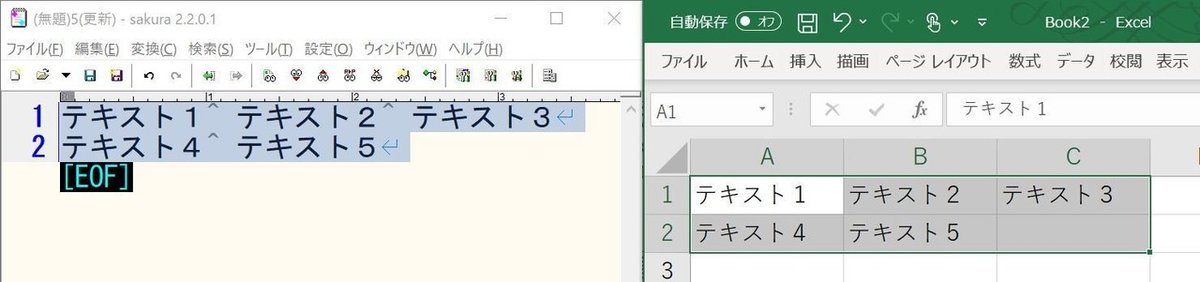
テキストをExcel表に貼り付けたときに、上手く列と行に分けるには次の2点が原則です。
1.タブ以降の文字は、Excelに貼り付けたときに次の列のセルに入力される
2.改行後の文字は、Excelに貼り付けたときに次の行のセルに入力される
この2点を利用すると、テキストをExcelにコピペした時に、下の図のようにセルごとに文字が入力されて表として扱えるようになります。
一つのセルの中にすべての文字がコピーされてしまうという場合は、Excelでセルを選択した時にセルの「編集モード」になってしまっていないか確認しましょう。
セルをダブルクリックすると、セル内に限定して編集ができるようになります。これがセルの編集モードです。この状態でテキストをコピペすると1つのセルの中にすべての文字が貼り付けられることになります。
テキストを表の形で貼り付けたい場合は、セルを選択してペーストするだけでOKです。
1.Webページからテキストエディタへ文字列コピー
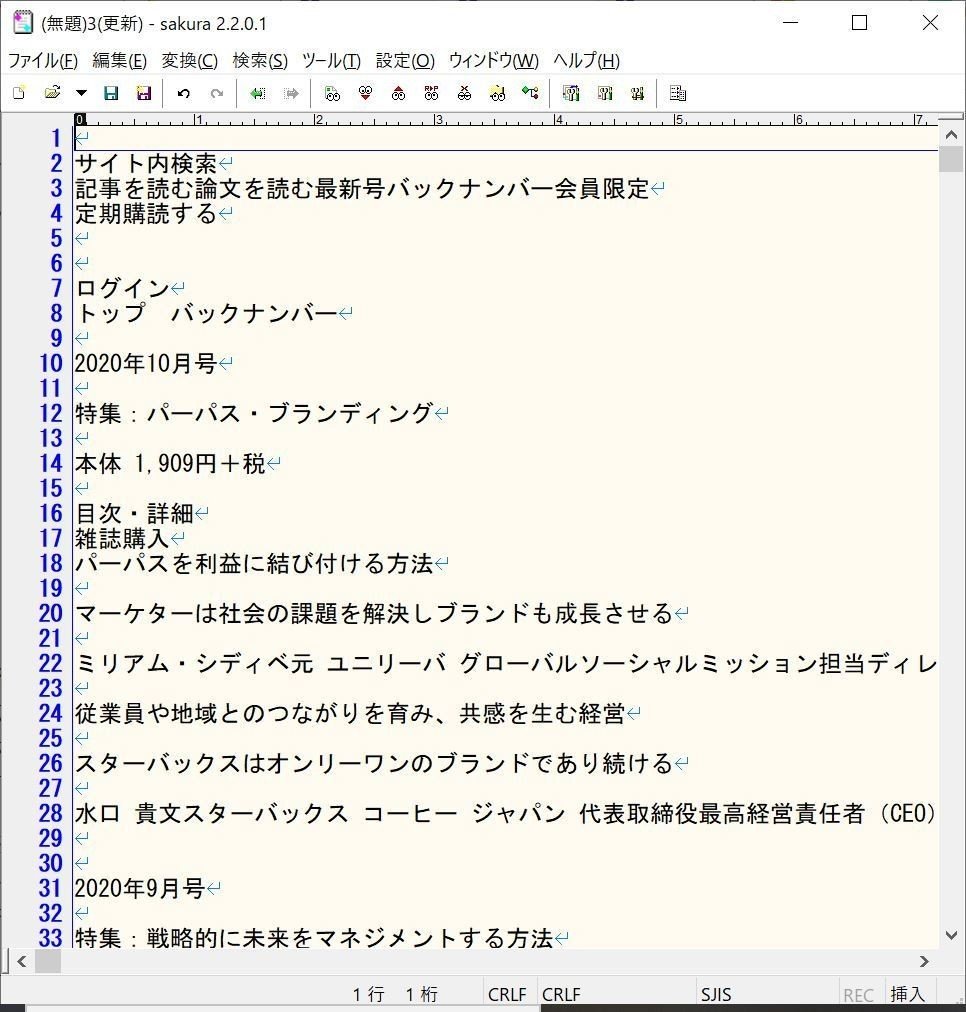
HBRのバックナンバーページを開き、文字列をすべて選択(Ctrl + a )し、コピー(Ctrl + c)、テキストエディタに貼り付けると、こんな感じになります。
テキストをExcelに貼り付けたときに表の形にするには、適切な位置にタブと改行が入っていることが条件です。
テキストエディタにコピペした結果を見ると、各号・各項目ごとに改行されているのですが、空白行も多く、このままExcelに貼り付けてもまとまりがなくなってしまいます。
これをテキストエディタ上で整形して、各号が1列に、各項目はタブで区切られるようにしていきます。
ところで余談ですが、HBRのバックナンバーページは12号ごと表示される形式になっています。
2ページ目のURLはこんな感じ。
https://www.dhbr.net/ud/backnumber?page=2&per_page=12
このper_page=12が1ページに表示するバックナンバーの数を表しているようです。そこで、この数字を適当に「100」にして再度ページを読み込んでみると、1ページに100件のバックナンバーが並びました。
過去の記事をぐっと遡って一覧で見たいときには便利です。
https://www.dhbr.net/ud/backnumber?per_page=100
2.正規表現を使った文字列検索と置換
整形に入る前に、どこで改行するか、どの文字をタブに置き換えるかの目ぼしをつけておきます。
この時に役立つのが「正規表現」です。
通常の文字列検索では、検索欄に入力した文字と完全一致するものしか検索できません。
正規表現を使うと、同じようなパターンで並んでいる文字列をまとめて検索することができます。例えば、「2020年9月号」、「2019年12月号」などの規則的な文字列であれば、「20\d\d年\d*月号」のように数字を書き換えることで一括検索できるようになります。
正規表現はテキストエディタによって、使える記号が多少異なります。そのため、使っているテキストエディタのヘルプで使用できる記号を確認しておく必要があります。
ただ、代表的なところはほとんど共通しています。大体、下記を覚えておくと多少、環境が違っても使えると思います。
\d 任意の数字
\s スペースなど空白文字
\t タブ
\r\n 改行(CRLF)
* 直前の文字の0回以上の繰り返し
. 任意の一文字
^ 文頭
$ 文末
Sakura Editorの正規表現はこちらを参考にしてみて下さい。
今回は、特集名や記事タイトル名ごとに改行されているので、まずはこの改行をタブに置き換えれば良さそうです。また、各号ごとに改行させたいので、シンプルに「yyyy年mm月号」の前に改行を入れたいと思います。
1. 不要な空白行を削除:文頭の改行を置換
画像はSakura Editorでの例です。文頭(^)直後の改行(\r\n)を指定して、置換後の欄は何も入力せずに「すべて置換」を実行します。

実行結果はこちら。余計な行がなくなりました。

2. 全項目をタブ区切りに変換:改行をタブに置換
改行(\r\n)をタブ(\t)に置き換えます。これを実行することで、すべてのテキストが改行なしの1行になることになります。

3. 各号の情報の先頭で改行:正規表現で号数を検索し、改行を挿入する
ここが少しポイントになります。
これまでは検索した改行記号をタブなどに置換してきました。今回は、雑誌の号数を検索して、号数情報の前に改行を挿入する必要があります。
まず、年月情報が入った雑誌号数を検索するには、正規表現を使って数字を\dに置き換えます。月は1桁と2桁が存在するので、ワイルドカード(*)を使って\dの0回以上の繰り返しとして表現します。
また、検索した雑誌号数は、それ自体も発行年月を示すデータなので残しておかなければなりません。Sakura Editorには検索した文字列を始点に、文字を挿入する機能がついているのでこれを利用します。
(下の図では、「置換対象」のラジオボタンで「選択始点(1)挿入」を選んで指定しています。)

CotEditorには、この機能がないのですが、検索結果を参照する変数として($1)が用意されています。置換後の欄に「\r\n$1」を指定すると、検索文字列の前に改行を挿入することができます。
実行結果がこちら。
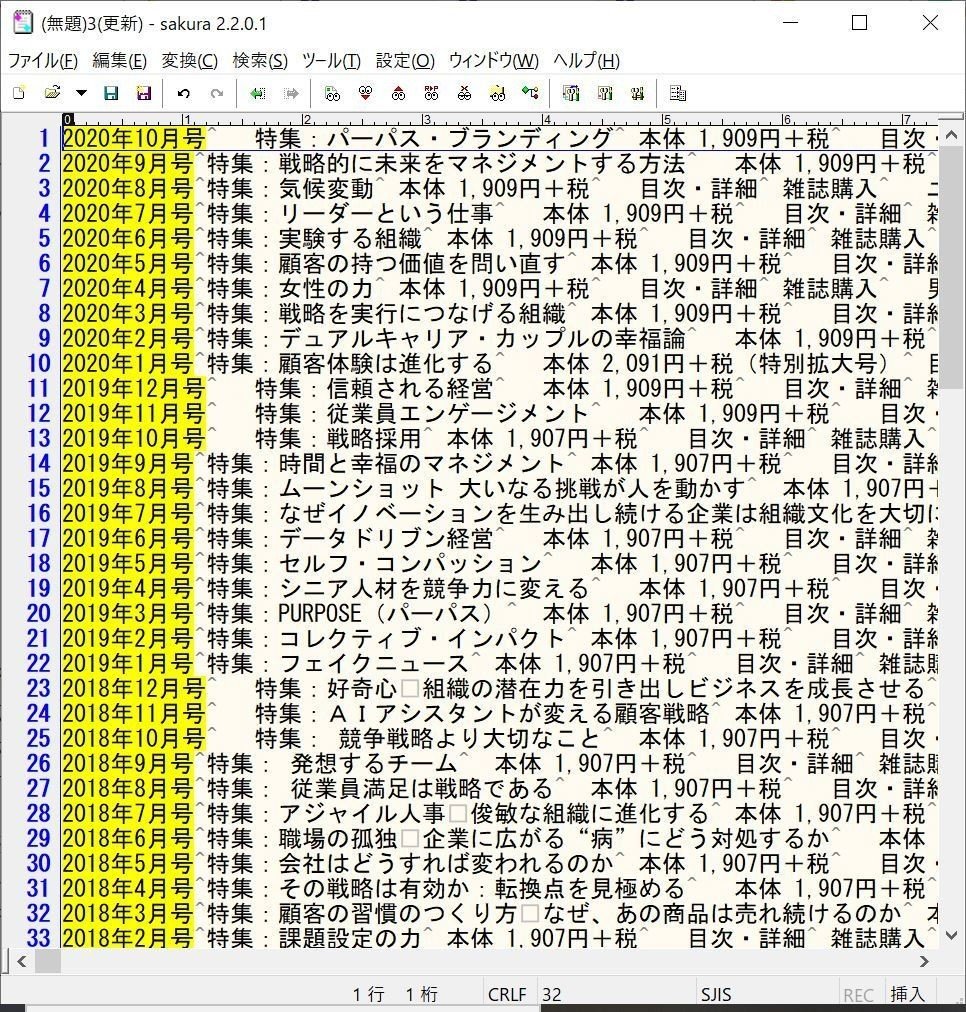
元のWebページのヘッダやフッタなど、不要な情報が、テキストの一番最初と末尾の部分に入っているので、これらを削除して整形完了です。
3.整形テキストをExcelに貼り付け!ほぼ完成だけど注意
整形したテキストを、再びすべて選択してコピーし、Excelに貼り付けるとこんな感じになります。これでほぼ完成。

なぜ、「ほぼ」なのか。
それは元のWebページの表示に、一部イレギュラーがあることで列がずれていたりすることがあるからです。
これはざっと目で確認せざるを得ません。
今回で言えば、毎号表示されているように見えた「雑誌購入」が一部の号で非表示(売り切れ?)になっており、その分、記事タイトルが左の列にずれている箇所がありました。
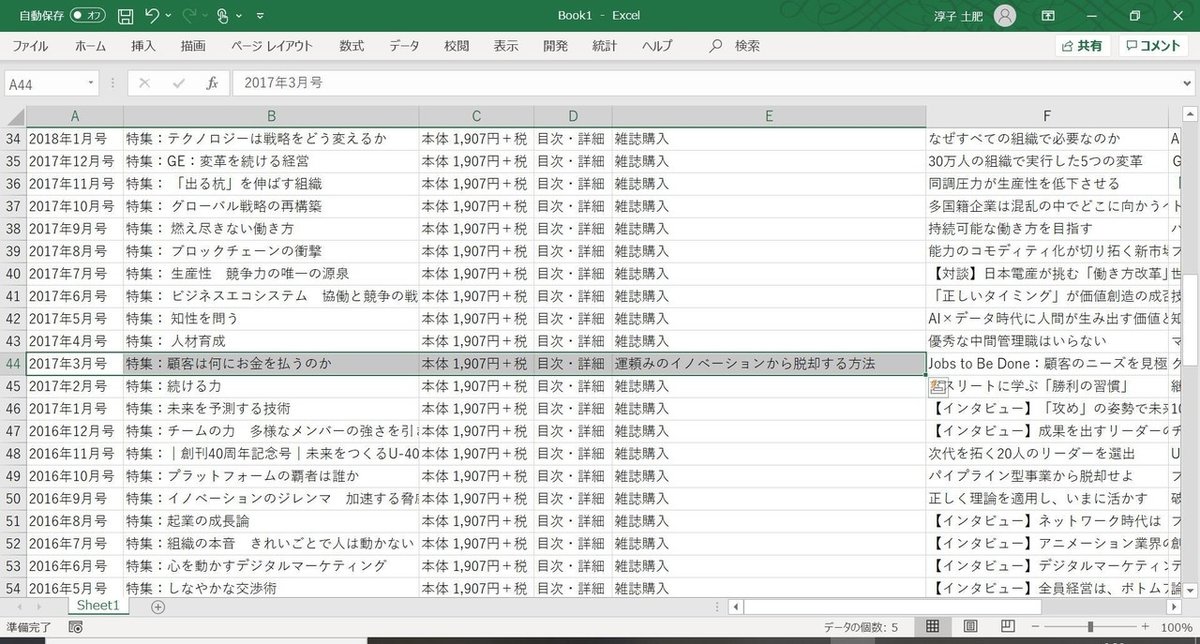
こうしたイレギュラーは、Excelのフィルター機能などを使って、降順・昇順に並べなおしてみると比較的容易に見つけることができます。
また、この表の場合、さらにきちんとした形に仕上げるには、毎号、大体2本ずつ紹介されている記事タイトルと著者名の表示列をそろえるべきかと思います。ここも手間がかかりますが、目で確認が必要です。
一つの記事に対して1名から5名の著者名が並んでいるため、著者名列1~5を作り、2本目の記事タイトル列をそろえて完成です。
他の方法と比較して
数が少なく、ある程度一覧性をもって公開されているテキストであれば、フリーソフトと正規表現の知識だけで簡単にExcelに整形できるのがメリットです。
一方で、手順の最後に、イレギュラー非表示と、著者名と記事タイトルの識別でひと手間かかったとおり、目検でのチェックと並べなおしが必要になります。
この点は、例えばGoogle スプレッドシートのimportXML()関数を使うと、HTMLのタグに設定されたidやclassにもとづいて著者名や記事タイトルに仕分けて表に取り込めるようになります。
もちろん、プログラミングできてしまえば、同様にデータを取り込み、Excelに限らず好きな形でデータ利用できるようになるはずです。
この記事が気に入ったらサポートをしてみませんか?