
ControlNetでポーズや構図を指定してAIイラストを生成する方法

こんにちは。だだっこぱんだです。
今回は、AIイラスト界隈で最近話題のControlNetについて使い方をざっくり紹介していきます。
モチベが続けば随時更新します。
StableDiffusionWebUIのインストール
今回はStableDiffusionWebUIの拡張機能のControlNetを使います。
WebUIのインストールに関してはすでにいろんな解説記事や動画があると思うのでそちらをご参照ください。
一応僕が作った簡単にWebUIを起動できるソフトも紹介しておきます(せんでん)
ControlNetとは
ちょうざっくり説明すると、棒人間や線画、深度情報からそれに従って画像を生成できる機能です。
つまり最強です。
デザインドール -> openpose -> StableDiffusion
— だだっこぱんだ🍞 (@ddPn08) February 14, 2023
やばやば、かなり良い pic.twitter.com/PRWGuQPOzH
絶対間違ってるControlNetの使い方。
— だだっこぱんだ🍞 (@ddPn08) February 14, 2023
割と変なポーズでもいける🙃
創薬ちゃんごめんなさい。おもしろすぎる。#AIArt #AIイラスト pic.twitter.com/tONW9N5Pdg
上のツイートのような感じで、ポーズを完璧に指定できちゃったりします。
他の例が見たい方はこちらのリンクからいろいろ見れます👇
インストール
超簡単です。
WebUIを開いてExtensionsタブに飛びます。
そうしたらInstall from URLをクリックして一番上のテキストボックスに
https://github.com/Mikubill/sd-webui-controlnet.gitを入力し、Installボタンをクリックします。

そうしたらWebUIを再起動してインストール完了です。
モデルをダウンロード
次にControlNetのモデルをダウンロードします。
下のリンクからすべてのモデルがダウンロードできます。
https://huggingface.co/lllyasviel/ControlNet/tree/main/models
ただ、5GB超えのモデルが全部で8個もあるので、使うものだけダウンロードするのをお勧めします。この後、各手法の説明で使用するモデルも一緒に紹介します。
※ 2023/02/15 追記
軽いモデルが出ました700MBレベルなので全然全部入れれます
https://huggingface.co/webui/ControlNet-modules-safetensors/tree/main
とりあえずopenposeで比較
— だだっこぱんだ🍞 (@ddPn08) February 15, 2023
結論なんも変わらん
魔理沙はなぜか黒パンツ https://t.co/PCs0mNBXTo pic.twitter.com/t09I5Fy3nH
モデルの配置
モデルをダウンロードしたら拡張機能のモデルフォルダにモデルを配置します。拡張機能のディレクトリは
<WebUIのフォルダー>\extensions\sd-webui-controlnetです。
このフォルダにあるmodelsフォルダにモデルを配置します。
openpose | デザインドールからポーズを指定
まずは僕がかなり気に入っている方法を紹介します。
この方法ではデザインドールというソフトを使い、3Dでポーズを指定する方法です。
使うControlNetモデルはcontrol_sd15_openpose.pthです。
デザインドールをインストール
無料版で十分使えます。以下のリンクからダウンロードしてインストールしてください。
起動するとこのような画面になります
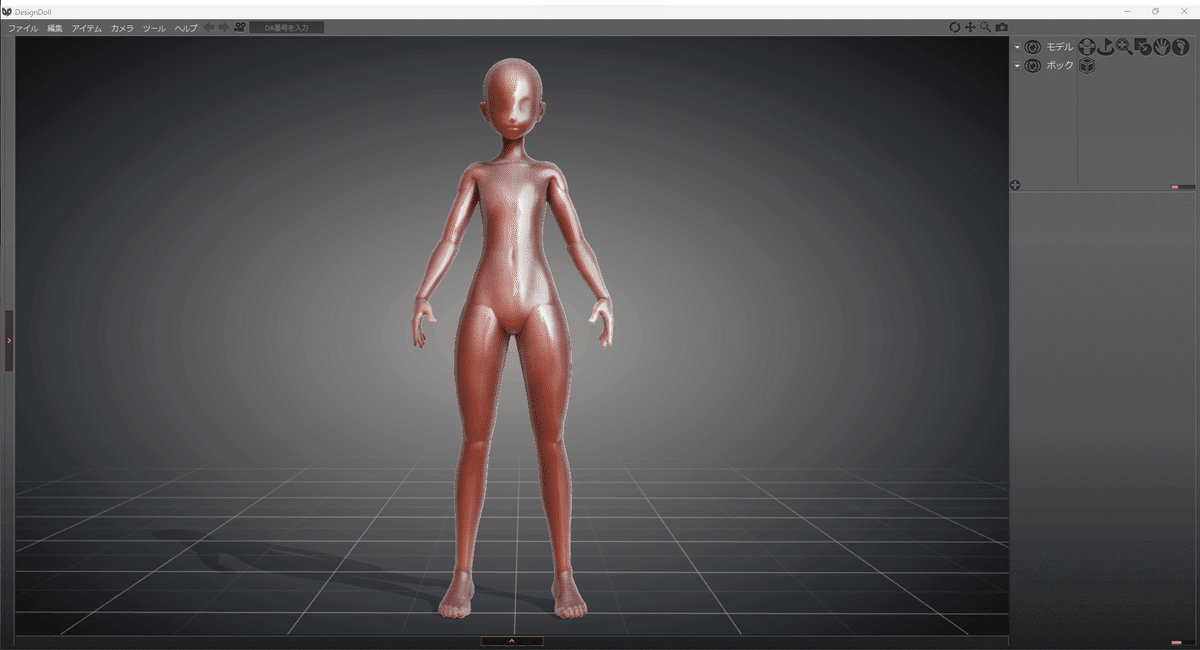
マウスカーソルで手や足をドラッグして好きなポーズを作りましょう。

いい感じのポーズができたら左上のファイル > 画像を書き出す をクリックし保存します。
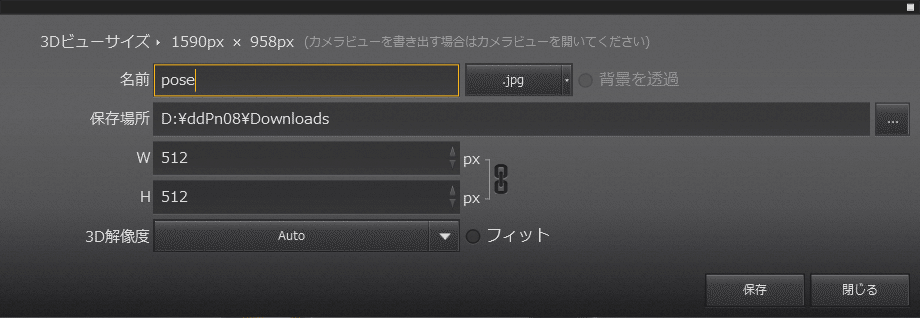
解像度は生成する画像と同じ縦横比である方が良いです。
ControlNetに画像をセット
ControlNetをインストールした状態でWebUIを起動すると下の画像のようなアコーディオンが表示されます。これをクリックしてControlNetの設定を開きます。
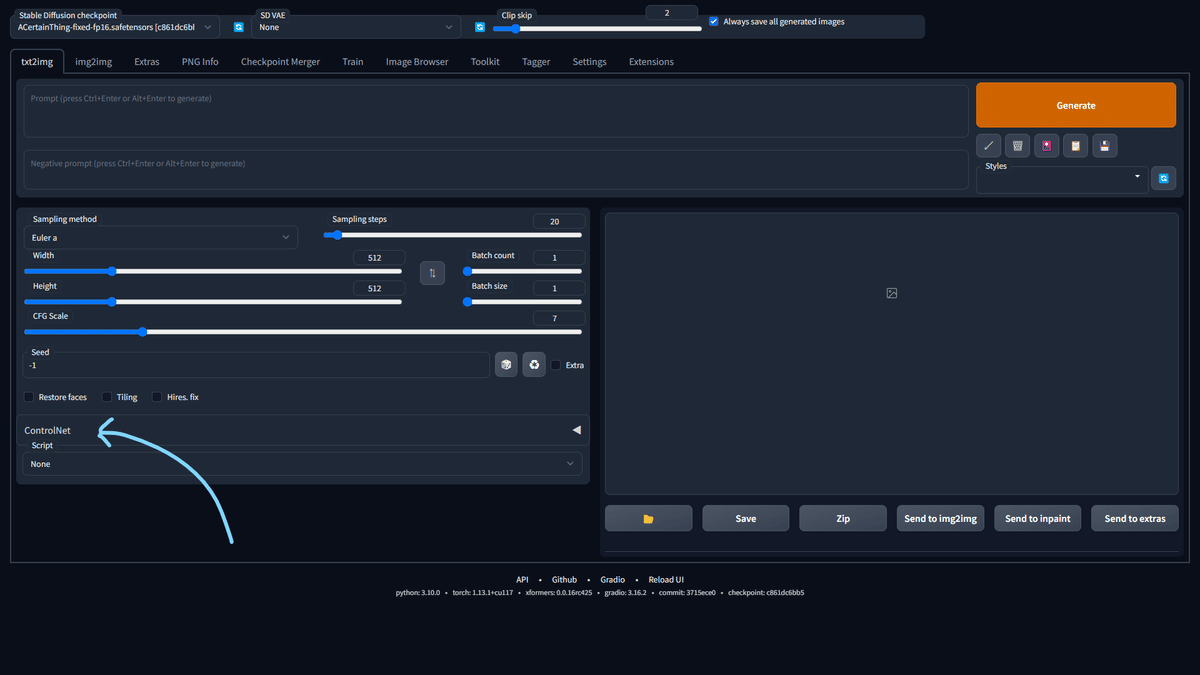
Enableにチェックをつける
preprocessor -> openpose
Model -> control_sd15_openpose
Canvas Width -> 先ほどの画像の横幅
Canvas Height -> 先ほどの画像の縦幅
Imageに画像をドラッグアンドドロップ(もしくはクリックして画像を選択)

これで設定は完了です。
早速生成してみましょう。
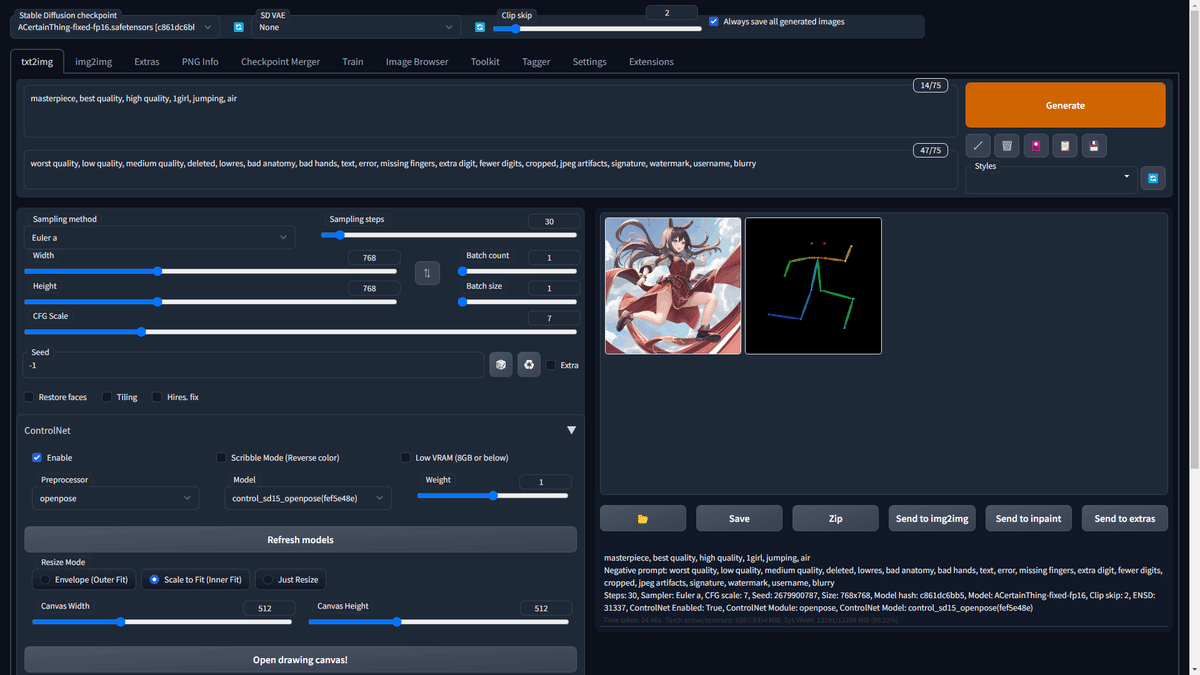
negative prompt: worst quality, low quality, medium quality, deleted, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, jpeg artifacts, signature, watermark, username, blurry

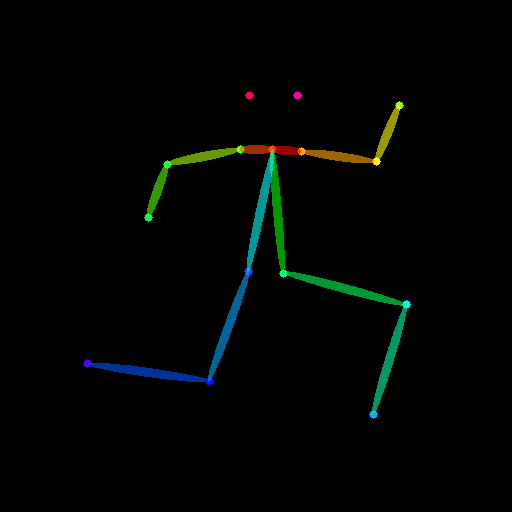
無事、指定通りのポーズで画像が生成できました。プロンプトにはクオリティタグと1girl, jumping, airしか入れていません。
生成画像と一緒に出てきたカラフル棒人間はデザインドールの画像からポーズを解析したものです。これをもとにControlNetが画像を生成します。
カラフル棒人間から生成
別の手法ですでにカラフル棒人間の画像が手元にある場合はそれを使用して生成できます。

設定はこんな感じ。ポイントはpreprocessorをNoneにすることです。

こんな感じで生成できます。
midas + depth | 深度情報から画像を出力
StableDiffusion v2で出てきた機能「depth2img」とほぼ同じです。
これがv1モデルでできます。
使うモデルはcontrol_sd15_depth.pthです。
生成した画像のキャラを入れ替える
先ほど生成した画像のキャラを入れ替えてみましょう。(と言っても特にキャラを意識したわけではないのでイメチェン的な雰囲気で。)
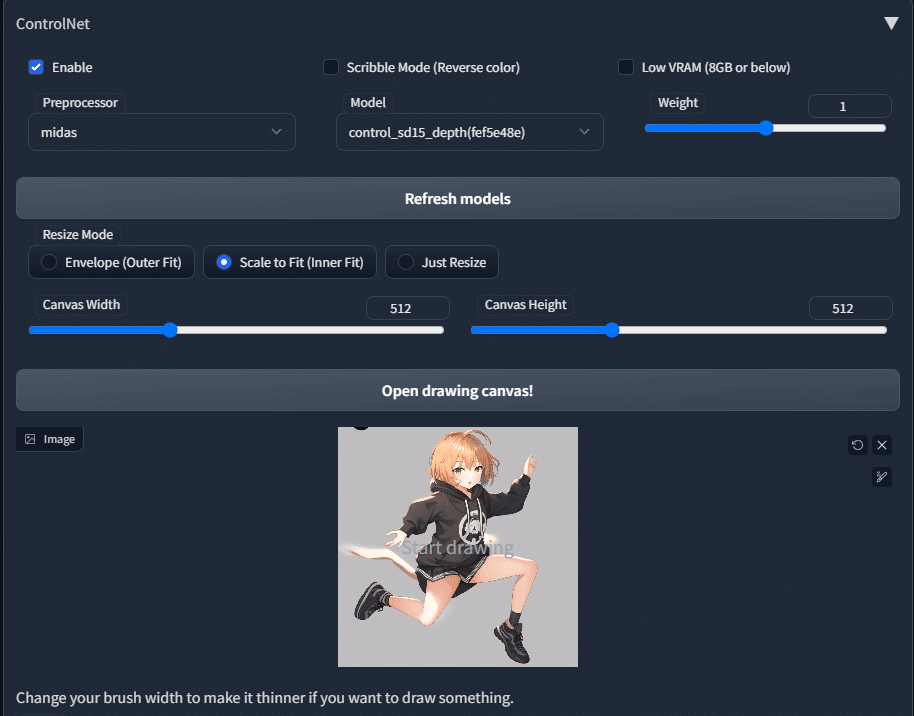
negative prompt: worst quality, low quality, medium quality, deleted, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, jpeg artifacts, signature, watermark, username, blurry
設定はこんな感じ。
preprocessor -> midas
model -> control_sd15_depth
※ 2023/02/15 追記
midas は depth という名前に変わりました。
この状態で生成するとこんなかんじ。

生成画像と深度の画像が表示されます。
ただこの状態だと何も変わらないですね。
少しプロンプトをいじってキャラを変えていきます。この際Weightという値をいじって深度情報にどれだけ従うかを調節する必要があります。

negative prompt: worst quality, low quality, medium quality, deleted, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, jpeg artifacts, signature, watermark, username, blurry
weight: 0.4
ドレスを着せてロングヘアーにしてみました。いい感じにキャラが変わりましたね。

negative prompt: worst quality, low quality, medium quality, deleted, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, jpeg artifacts, signature, watermark, username, blurry
weight: 0.4
猫耳学生服の女子にしてみました。
こんな感じでポーズを変えずに特徴を変えることができます。
まとめ
ちょうつよい。さいこう。
(ほかの機能はいつか書くかもしれないです)
この記事が気に入ったらサポートをしてみませんか?