
ちまたで噂の似ているぶいすぽ2人の声を分析してみた

VTuberが流行っていて、今年の6月にはにじさんじで有名なANYCOLORが上場し、勢いの凄さを感じます。
私もVTuberwよく見ます。
特にぶいすぽっを見ています。
最近ぶいすぽっの白波らむねさんと神成きゅぴさんが似ているとのことで騒がれています。(騒がれていると感じているのは主観ですw)
特に下記動画の二人の「らぶち」似ているということです。
実際に聞いてみてもわかるのですがかなり似ています。
ですが、聞いて似ているというのは主観的な要素が強いので本記事ではふたりの「らぶち」の声を音声分析してどれだけ似ているか分析してみたいと思います。
ふたりの「らぶち」は下記動画から聞くことができます。
らぶちについて
こちらの動画では3分32秒から聴き比べができます。
こちらの動画では2分52秒から2分55秒でふたりの「らぶち」が聞けます。
Youtubeチャンネルのほうはこちら。
FPSを中心に動画配信をしています。
きゅぴさんのYouTubeチャンネルはこちら
らむねさんのYouTubeチャンネルはこちら
音声解析 データ切り取り
音声解析をするためには音声を取り出さなければいけません。
今回は分析のために二人の「らぶち」と言っている部分を切り出しました。
最初にBGMが少し流れていますが、「らぶち」の部分は声だけですので解析しやすくなっております。
最初の「らぶち」と言っているのが白波らむねさん、後の「らぶち」が神成きゅぴさんです。
皆さんは聞き分けできましたか?
私はできませんでした(笑)
音声解析 データ準備
1つのファイルでは2人の音声が混在しているのでプログラムで分離します。
編集ソフトなどでも分離はできますが、ソフトによって秒単位でしか区切れないのもあるためプログラムで「らぶち」を分離します。
まずは音声ファイルの波形を見ます。
import pandas as pd
import librosa
import matplotlib.pyplot as plt
import japanize_matplotlib
%matplotlib inline
y, sr = librosa.load('cupi_ramu_mono.mp3')
plt.plot(y)
plt.ylabel('Amplitude')
plt.xlabel('Time')
plt.savefig('voice_wave.png')
plt.show()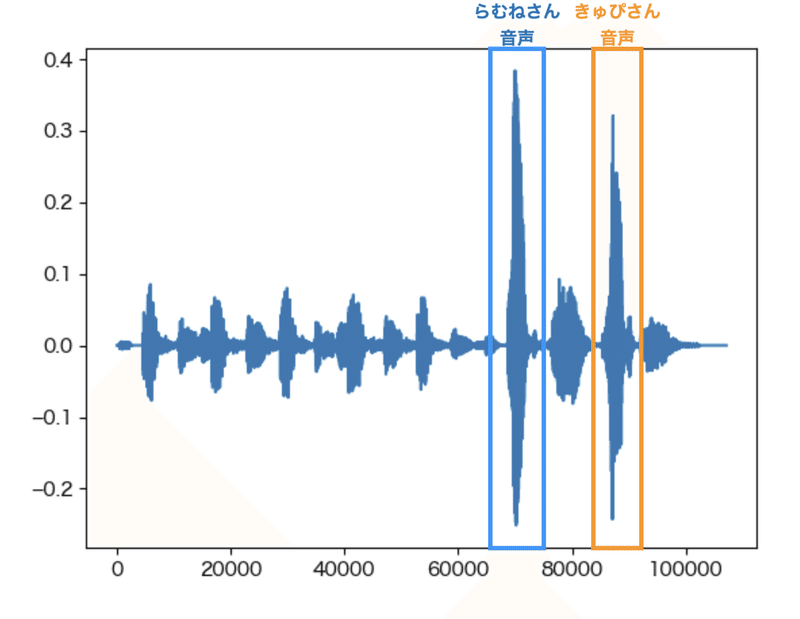
横軸が時間で縦軸が振幅です。
青枠の横軸の60000から80000がらむねさんが「らぶち」と言っている部分です。
オレンジ枠の80000から100000がきゅぴさんの「らぶち」になります。
この部分を切り出し、MP3形式で保存します。
音声ファイルの切り出しと再生に必要なライブラリをインストールします。
具体的なインストール方法はこちらのサイトを参考にしてください。
PyObjCのインストール
pydubのインストール
from pydub import AudioSegment
sound = AudioSegment.from_mp3('ramu_cupi.mp3')
ramu = sound[3100:3850]
ramu = ramu.set_channels(1)
cupi = sound[3900:4650]
cupi = cupi.set_channels(1)
ramu.export("ramu.mp3",format="mp3")
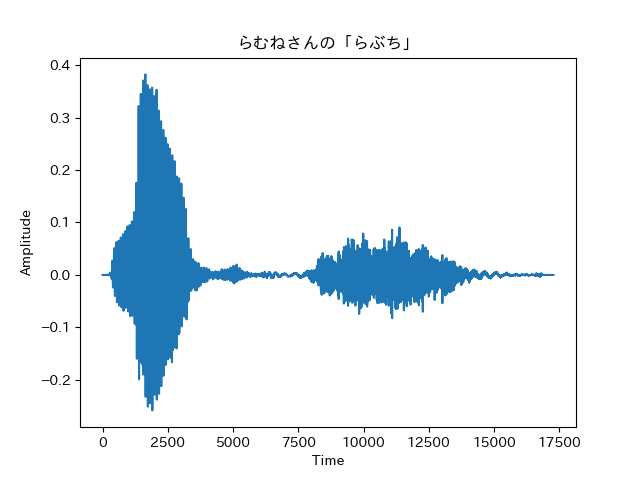
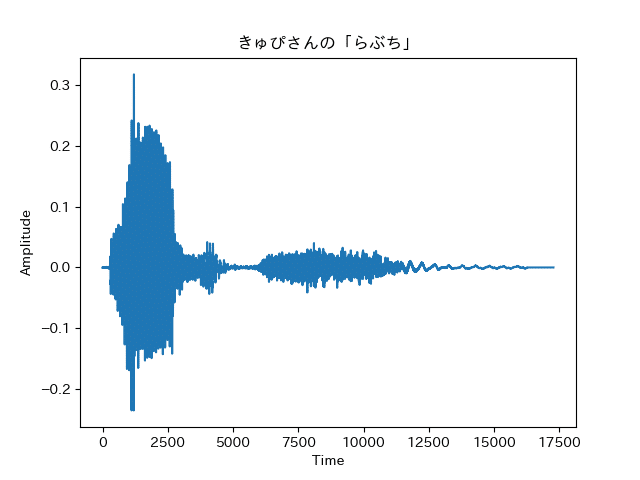
cupi.export("cupi.mp3",format="mp3")取り出した音声ファイルと音声波形はこちら。
らむねさんの音声
きゅぴさんの音声
音声解析 周波数特性
切り出した音声を解析していきます。
音の物理的な基本要素は周波数と振幅です。
振幅は音の大きさ長い関わってきます。
今回は声が似ているかというところで声質が重要になってきます。
そのため周波数を解析していきます。
2人の声に含まれている周波数成分を可視化してどれだけ似ているかを見てデータからも2人の声が似ているか分析します。
フーリエ変換で特性を見る。
二人の声に含まれている周波数を見るために音声をフーリエ変換してパワースペクトルで、ぱわーすへよん可視化します。
コードは下になります。
らむねさんのパワースペクトルを抽出するコード
stft = librosa.stft(y=y,n_fft=2048, win_length=512, hop_length=512)
# 人間が分かる音量にデシベル変換
stft_to_db= librosa.amplitude_to_db(stft,ref=np.max)
# 可視化
img = librosa.display.specshow(stft_to_db,x_axis = 'time',y_axis='log')
plt.title('らむねさんのパワースペクトル')
plt.colorbar(img)
plt.savefig('ramune_powerspec.png')
plt.show()きゅぴさんのパワースペクトルを抽出するコード
stft = librosa.stft(y=y,n_fft=2048, win_length=512, hop_length=512)
# 人間が分かる音量にデシベル変換
stft_to_db= librosa.amplitude_to_db(stft,ref=np.max)
# 可視化
img = librosa.display.specshow(stft_to_db,x_axis = 'time',y_axis='log')
plt.title('きゅぴさんのパワースペクトル')
plt.colorbar(img)
plt.savefig('cupi_powerspec.png')
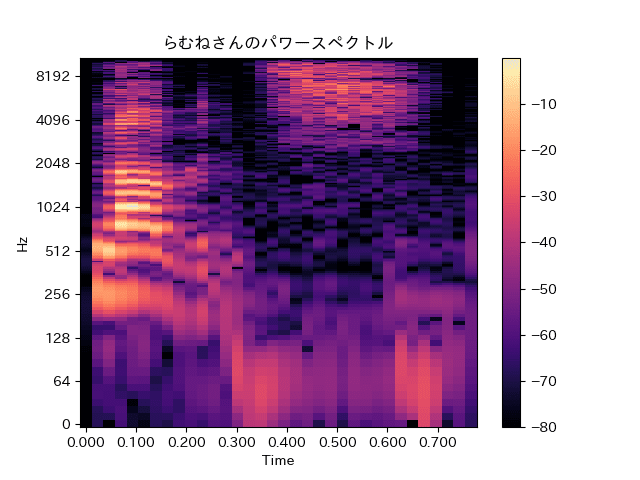
plt.show()らむねさんのパワースペクトル
きゅぴさんのパワースペクトル
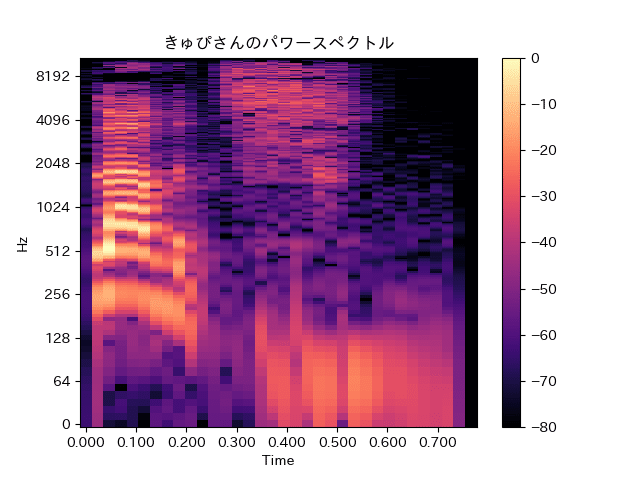
よくわかりませんねw
横軸Timeの0.000から0.300の位置が「らぶち」と言っているところですがパワースペクトルでは違いが分かりづらいです。
きゅぴさんの方が512Hz〜1024Hzの成分が強くでてるかなぁ〜くらいです。
メル周波数ケプストラムによる特徴量抽出
スペクトルではわからないため、人間の聴覚特性を考慮した特徴量抽出を行うメル周波数ケプストラムを用います。
詳細は下記参照です。
メルケプストラムのコードは下記になります。
らむねさんのメルケプストラム抽出コード。
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
y, sr = librosa.load('ramu.mp3')
melspec = librosa.feature.melspectrogram(y=y,sr = sr,n_fft=2048, win_length=512, hop_length=512)
# 人間が分かる音量にデシベル変換
melspec_db = librosa.amplitude_to_db(melspec)
# 可視化
img = librosa.display.specshow(melspec_db,x_axis = 'time',y_axis='mel',sr=sr)
plt.colorbar(img)
plt.title('らむねさんのメルケプストラム')
plt.savefig('ramune_mel.png')
plt.show()きゅぴさんのメルケプストラム抽出コード
y, sr = librosa.load('cupi.mp3')
melspec = librosa.feature.melspectrogram(y=y,sr = sr,n_fft=2048, win_length=512, hop_length=512)
# 人間が分かる音量にデシベル変換
melspec_db = librosa.amplitude_to_db(melspec)
# 可視化
img = librosa.display.specshow(melspec_db,x_axis = 'time',y_axis='mel',sr=sr)
plt.title('きゅぴさんのメルケプストラム')
plt.colorbar(img)
plt.savefig('cupi_mel.png')
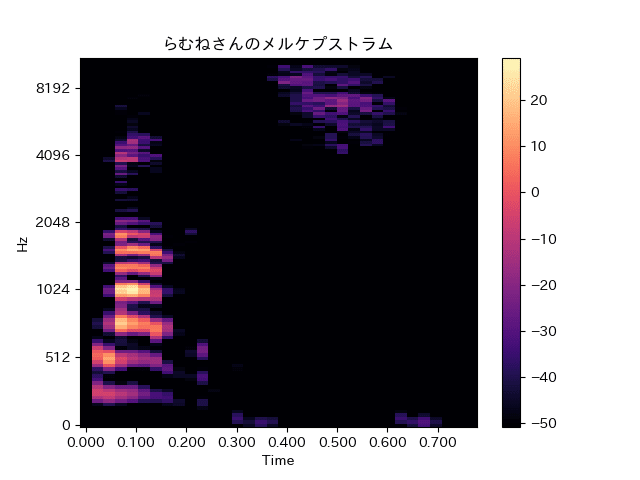
plt.show()らむねさんのメルケプストラム
きゅぴさんのメルケプストラム
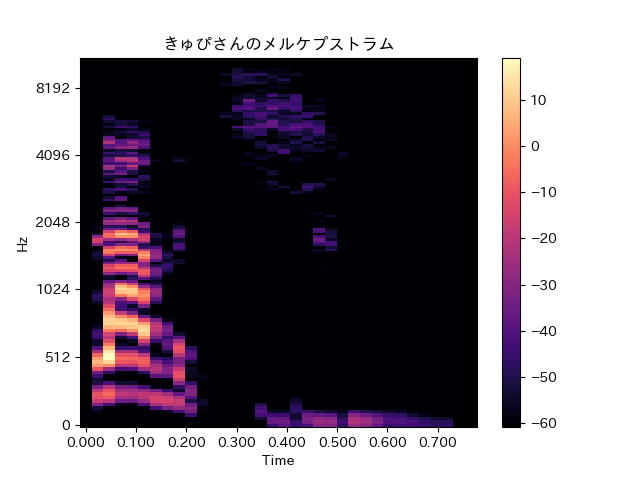
横軸Time0.000〜0.300の間の色が明るいところが音声の周波数成分が含まれています。
かなり同じ周波数成分を持っています。
聞いた感じ似ているだけはありますね。
周波数成分の違いはきゅぴさんの方が広く成分を持っています。
動画でも言っていますが、きゅぴさんの方がやや鼻声感があるというところがより様々な周波数成分がメルケプストラムにも表れているのでしょう。
らむねさんの方が周波数成分が集中しているので、声がシャープな感じではっきりしてる感がありそうです。
声のテンポ
音声のテンポを見てみましょう。
tempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr)
print(f'らむねさんの音声テンポ {tempo :.2f} beats per minute')
tempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr)
print(f'きゅぴさんの音声テンポ {tempo :.2f} beats per minute')らむねさんの音声テンポ 161.50 beats per minute
きゅぴさんの音声テンポ 215.33 beats per minute
きゅぴさんの方がテンポが速いですね。
これは音声を聞いても「らぶち」の言い方がやや速いのがわかると思います。
今回は「らぶち」と言っている部分のみのテンポですので、これだけで喋り方のテンポの評価はできません。
参考程度ですね。
まとめ
今回は似ていると言われているらむねさんときゅぴさんの「らぶち」を音声解析しました。
解析結果からかなり似ています。
特徴としてはきゅぴさんの声は多くの周波数成分含んでいて、らむねさんは周波数成分が集中しているところです。
pythonでライブラリを使えば音声解析も比較的容易にできることがわかってもらえれば幸いです。
本記事のコード
本記事のnotebookファイルは以下からダウンロードすることができます。
よろしければサポートをよろしくお願いします。サポートいただいた資金は活動費に使わせていただきます。