
CyberZでのトイル可視化の取り組み

はじめに
はじめまして。CyberZでSREをしている藤井と申します。普段はOPENREC.tvなどを中心に、いくつかのサービスにSREとして関わっています。
CyberZではSREチームが出来てからというもの、各種古いアプリケーション基盤をKubernetesに移行したり、TerraformによるIaCを推し進めたり、各種DevOpsの実践を牽引・啓蒙したりしています。その結果として、普段の業務におけるトイルの割合はかなり減ったと感じています。しかし、明確にトイルについて計測はこれまでしてきていませんでした。
今回は、今一度トイルに向き合い、トイルの計測を始めた話についてお話しできればと思います。
トイルの定義
トイルの定義は、GoogleのSRE本 第五章「Eliminating Toil」に従っています。
手動での作業を伴うもの
繰り返されるもの
自動化できるもの
戦略的でなく、戦術的であるもの
一時的な対処であり、永続的な価値をもたらさないもの
サービスの成長に伴い作業量が増えるもの
基本的には実際の作業者が、上記の定義に則りそれをトイルとみなすかどうかなどを判断します。
トイルの計測・可視化
本題の計測および可視化についてですが、今回は計測に際して新たな基盤を構築したりはしていません。
CyberZでは昨年からFourKeysの計測のため、OSSである dora-team/fourkeys に少し手を加えた基盤を構築および運用しています。データストアであるBigQueryには、紐づけたGitHub Repositoryの各種イベントがWebhook経由で書き込まれており、これをGrafanaで可視化することでFourKeysメトリクスとして役立てています。
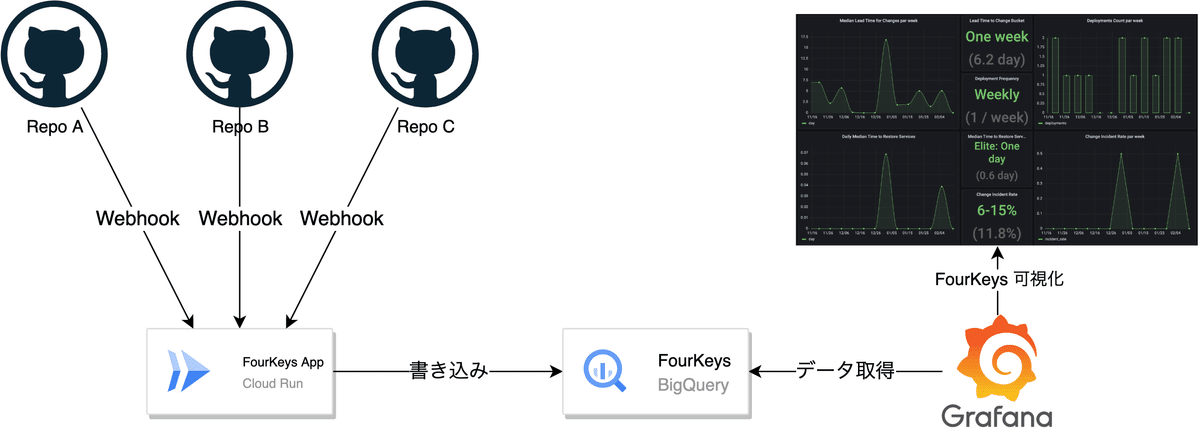
今回のトイル計測は、このFourKeys基盤のデータを活用して構築しています。具体的には、GitHub Issueのイベントを用い、特定のラベルの付いたIssueの件数などをGrafanaで可視化しています。
参考程度ですがGrafanaダッシュボードで実行しているSQLの一部を以下に貼っておきます。
FourKeysはGitHubのWebhookイベントを1行ずつBigQueryのevents_rawテーブルに書き込んでいます。event_typeがissuesのイベントの最新一件から、Toilラベルの付与されたもののみに限定することで、トイルIssueを抽出しています。
SELECT
*
FROM
(
SELECT
AS VALUE ARRAY_AGG(
events_raw
ORDER BY
time_created DESC
LIMIT
1
) [OFFSET(0)]
FROM
fourkeys.events_raw
WHERE
event_type = "issues"
GROUP BY
id
) tolis
WHERE
REGEXP_CONTAINS(
JSON_EXTRACT(metadata, '$.issue.labels'),
'"name":"([^"]*?)Toil([^"]*?)"'
)
;運用フローとしては以下の通りです。
トイルが発生した場合は、作業者はその都度GitHub Issueを作成します。
例として、EKSノードのディスクサイズが減少した時のアラート対応を挙げます。Issueにはトイルであることを示すToilラベルと、そのトイルがどの程度の負荷であるかのVolumeラベルを付与します。

Volumeは一時間未満で作業が完了する「Easy」、数時間を要する「Normal」そして数日以上必要な「Hard」の三種類があります。この区分は、Googleの公開している下記の記事を参考にしています。
参考: Identifying and tracking toil using SRE principles
Volumeは、可視化される過程でトイルの負荷を表現するトイルポイントに変換されます。それぞれ、Easyは1、Normalは3、そしてHardは9ポイントになります。Grafanaダッシュボードは、指定された期間の全体のポイント合計と、各人の負荷をグラフで可視化します。

SREチームでは、このダッシュボードを定期的に確認することで、トイルについての見直しを行っています。トイルの絶対的な量が多すぎないか、メンバー間での偏りが顕著でないか、トイルのVolumeが適切かなどの認識をすり合わせます。
明らかな作業の偏りがあれば他の人にオフロードできないか検討しますし、頻繁に実施されているEasyなトイルがあれば自動化に動きます。上記の図で言うとNodeFilesystemSpaceFillingUpがそれにあたるでしょう。実際にはここまで単純なデータではないため、GitHubのGUIで把握するのは難しいですが、Grafanaダッシュボードにすることで日々のトイルが一目瞭然になりました。
所感
トイルの測定を始め、メインの目的であるトイルの把握以外にも、いくつかの副次的な効果も得られました。特に、トイルが発生した時にGitHub Issueを作成するという作業が追加されることにより、トイル自体への負荷が若干高まりました。今までは慣れている作業でほんの数分で終えていたものも、Issue作成の一手間が増えることで、思ったより頻繁に発生していたり、面倒なタスクであると改めて気がつくきっかけになりました。実際に定期的に発生しているPrometheusのディスクアラートから、Thanos導入の検証を始めたり、更なるトイル撲滅の動きにつながっています。
また、自分以外のSREメンバーが日々実施しているトイルにも目が向くようになりました。組織が変化に強くなるためには、システムや技術だけでなく人や知識も流動的でなければなりません。特定の作業者に知見が偏りがちなトイルを減らすことで、より新しい人が受け入れ易い、変化に強いチームになるはずです。Issueを介して知識の属人化を排除し、チームとしてトイルに向き合う動きを今後より一層強めていきたいと思います。
おわりに
私たちのSREチームは、トイルについてはある程度減らせていると感じていましたが、いざ計測をしてみるとまだまだ改善の余地がありました。
もちろん全てのトイルを撲滅することは理想論でしかなく、費用対効果との天秤であるのはいうまでもありませんが、何はともあれまず計測、現状把握です。もしトイルの削減はしているものの計測ができていない方がいましたら、この記事がトイル計測の一助となれば幸いです。
この記事が気に入ったらサポートをしてみませんか?