
時系列データのvalidationに関する質問に回答します

時系列データに関するvalidationについて質問をもらいました。
時系列系のデータで(ウォークフォワード)バックテストをするときの疑問です。例えば学習: 1~5月のデータ、検証: 6月で実施したあと、7月のデータを予測するときはこの1~5月のデータで学習したモデルをそのまま利用すべきなのでしょうか。それとも1~6月のデータで再学習すべきでしょうか。後者は最新のデータを取り込めるという点で利点があると思う一方、検証データがないのでearly stoppingができず、iterationをどうしようかと悩みます(LightGBM等を仮定)。1~5月の学習時のiterationを記憶しておいてそれを使うというのが一つの考えですが、果たしてそれでいいのだろうかと悩んでいます。
とても良くある課題設定であり、こうすれば良いという一定のセオリーはあるものの、データによって正解が異なるため、工夫をしたい場合に考慮すべきことをまとめている情報が少なく、簡単ではない課題だと思います。
twitterで募集したところ、多くのコメントをもらいましたので、それを踏まえつつ私なりの考えを書きたいと思います。
セオリーとされる方法
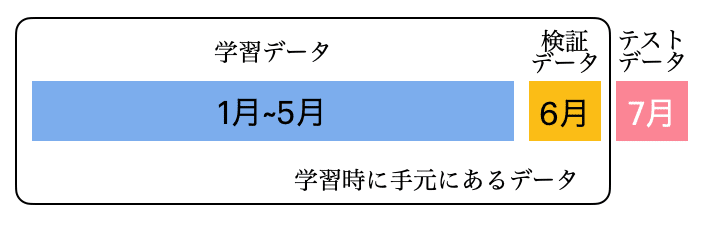
質問者が書いているように、1~5月のデータで学習し、6月のデータを検証データするのがセオリーと言える方法です。図で表すと次の図になります。

学習が1回で終わるという利点や、学習したデータに対して検証データとテストデータがともに未来のデータとなっており、同じぐらいの精度が実現するだろうと、理解を得られやすいという利点もあります。
ただ、よく考えると6月のデータは学習にも使えることから、これを学習に使った方が精度が向上するのでは?という疑問が出てきます。検証データは手元にあり使うことができるので。
また、検証では学習データの1ヶ月後のデータですが、テストデータは2ヶ月後のデータなので、テストデータの方が検証データでの精度よりも劣ってしまうのではという疑問もあります。
タスクにもよりますが、6月に新商品や新ユーザが加わる例を考えると、6月のデータを学習データに入れると予測精度に大きな影響がある例が作れることはすぐにわかります。また、レコメンドのタスクを考えると、直近のデータを加えることはマストとなると思います。
分析コンペであればセオリーの方法を使っている人に、少しでも差をつけるため、直近のデータを学習データに入れることを考えるのは当然でしょう。
以下では6月のデータを学習データに入れる場合に、考えなければいけないことをまとめます。
6月のデータを学習データに入れる場合の選択肢
6月のデータを学習データに入れる場合、こうすべきという優れた方法があるというよりは、データとタスクに応じてメリットとデメリットを考えて、どれかを選ぼうという結論になると思います。
a-1)学習データを1月から6月にする。(iterationは1月から5月での学習時のもの覚えておいて使用する)

最終モデルでは、学習データを1月から6月の6ヶ月分に増やし、検証データをなくしてしまう方法です。
検証データがない場合、early stoppingが使えずiteration数を指定する必要がありますが、それは事前に6月のデータを検証データとして学習した時の値を覚えておいて使用する、精度もその際のものとほぼ同じものだと考えて使うという手法です。
多くの場合、この方法で満足できると思いますが、新データの割合が多い場合、データが増えることによるiterationのミスマッチは少し気になるところです。
勾配ブーステイングを考えると、データが増えるとベストなiterationは増加するため、次の資料などを参考にiterationを修正するのが、次の選択肢となります。
a-2)学習データを1月から6月にする。(iterationは1月から5月での学習時のものをデータ数が増加した分に応じて修正する
これはtwitterでコメントをもらったので、貼ってみます。
GBDTの場合データ増えると最適iterも線形に増えがちなので、1~4月とか1~4.5月の最適iterも見つつなんとなく多めに設定 https://t.co/Wd1Z106IWq
— YujiAriyasu (@aryyyyy221) July 14, 2022
YujiAriyasuさんの例をもう少し具体的にすると次のイメージ。
・1月~4月のデータで学習時のiterationが450、
・1月~4月15日のデータで学習時のiterationが475、
・1月~5月のデータで学習時のiterationが500、
だとします。この結果から
・1月分のデータが増えると50iterationだけ増加
・半月分のデータが増えると25iterationだけ増加
ということがわかるので、1月分のデータが増える1月から6月の場合には、550iterationに設定するという意味。
1~6月使って、データ数増えた20%分iteration1.2倍しますね。悩んでも仕方ないし、色々変えてもpublicにorverfitするだけなので決め打ちして変えないのがいいと思ってます。
— うら たつ (@d1348k) July 14, 2022
うら たつさんの方法もKaggleではよく使われる手法だと思います。
Kaggleであればsingleモデルではなく、seedアベレージングや、他のモデルとのアンサンブルがを最終モデルとすることがほとんどです。
学習iterationが多いよりも少ないことがリスクであるため、ある程度適当にiterationを多くしてしまう手法はリスクが少ない印象。
この点で、よく参照されるのが次の資料。(先ほどの資料と合わせて、どちらもJackさんの資料すごいです)
b)2月から6月のデータで再学習する

学習データを2月~6月のデータにする方法。
・学習時:学習データ1月~5月、検証データ6月
・本番時:学習データ2月~6月、テストデータ7月
これであれば、検証時の学習データと検証データの関係と、本番時の学習データとテストデータの関係が同じとなり、検証データで得られた精度がテストデータでも実現するという高い期待が持てます。
どれだけ学習するかというiterationについても、1月から5月を学習データで6月を検証データにした時のiterationを覚えておいて、2月から6月のデータで学習するときにそのまま使えるというメリットがあります。
デメリットとしては、1月のデータの情報を使えなくなってしまうという点です。
そのため、古いデータは捨てた方が良さそうなデータの場合や、a-2のような細かいiterationの調整はしたくない場合に使える方法だと思います。
c)2月から6月のデータを学習データとして、1月のデータを検証データとする

そもそもの課題が変わってしまいますが、1月から5月のデータでの学習をやめて、はじめから2月から6月のデータを学習データとし、1月のデータを検証データとする方法です。
データによっては未来予測の形になっておらずリークすることや、ラグ特徴などの検証データの特徴が作りづらいことから検証データでの精度がよく分からないという課題のある方法となっています。
ただ、大まかな精度などがわかれば良い場合には、学習が1回で終わりながら最新データを学習に使えるというメリットもあります。
d)n分割交差検証をする方法
Kaggleだとこの方法もかなり使われると思います。shuffleはせずに、n分割の交差検証をする方法です。

上の図の緑のTraining dataの部分が1月から6月で、青色のTest dataの部分が7月のデータの場合です。
厳密な未来予測の形になっていないので、少しリークが心配ですが、学習データ全部のout of foldの予測値を作れるため、アンサンブルなどがやりやすいのでKaggleではよく使われるのだと思います。
(時系列データのコンペの場合、アンサンブルで勝負がつかないことも多いので、アンサンブルにこだわる必要もなかったりしますが)
Kaggleでなるべく多くのデータを使いつつ、精度を高めたいという場合、a-2の方法でseed averagingするか、dの方法でアンサンブルするか、その両方を使うか(それぞれで予測を行なってブレンドするなど)。どれもあると思います。
その他、気をつけること
そもそも1月から6月では7月を予測できない場合
売上予測とかで時系列実務でやってたことありますが、仮に6月データを学習させたいなら検証期間でのiteration記憶はやるべきだと思いますが、それよりも月系の時系列だとseasonalにも要注意かと。(そもそも6月が特異な月ではないかなど)タスク次第ではありますが。
— rauta (@rauta_t) July 14, 2022
季節性の特徴が支配的な説明変数となる場合、同じ時期・季節の過去データを入れることが重要になります。
具体例としては、1月から6月のデータでは、7月のスイカの売り上げを予測できないとか、3月の引っ越しの需要予測は前年などの同じ時期のデータが必要となるみたいな例です。
データの傾向が変わる場合
データが時期によって変わりやすい場合(売り上げのデータで人々の興味が変わりやすいとか、商品側がアップデートを繰り返している場合とか)、直近のデータのみを使った方が精度が良くて、数ヶ月前のデータを入れると精度が落ちる場合があります。
この場合は、7月のデータを予測するのに直近の6月のデータのみを使うように、使用するデータの範囲を工夫が第一の選択肢でしょうか。データとタスクによっては過去のデータの補正を考えることもあるかもしれませんが、難しそう。
終わりに
色々なパターンを書きましたが、データを良くみながら、自分のニーズにあった方法の選択をするという結論になるかと思います。
この記事では、長くなりましたが、時系列データのvalidationを考えてみました。
以下、いただいたツイートの反応です。
いただいたツイートなど
いや1〜6月の時もあるか。行を跨いだ特徴量が無いか、期間の長さに依存しないケース。roundは適当に伸ばす。 https://t.co/jLgWC6gfkS
— Nomi (@nyanp) July 14, 2022
a-2やbのケースの話ですね。NNだと検証データがないと学習が上手くいっているかどうか不安なので、セオリーの方法を使うのもよくわかります。
リテールだと、1~5月学習モデルと1~6月モデルだと、6月に出てきた新商品への予測性能がダンチになりそうなので入れたくなるわね。
— nyker_goto (@nyker_goto) July 13, 2022
itemだけじゃなくてユーザもか。
— nyker_goto (@nyker_goto) July 13, 2022
なるほどなーと思い、本文にも取り入れさせてもらいました。新データに新商品のデータがある場合や、最新のユーザーの情報を加味する必要があるタスクの場合には、新しいデータをなるべく学習データに入れる必要があるのだなと理解しました。
1意見として………mlbコンペなんかがそうでしたが6月まで入れて学習し直し(イテレーション数は検証時のも)がいいと思います。
— mari@teyosan (@mari_tw1229) July 13, 2022
mlbのコンペは、時系列で選手のエンゲージメントを予測するコンペだったと思いますが、新データを入れて学習する方法が多かったという情報だと思います。ありがとうございます。
質問主では無いですが、、
— Naoism (@naoism00) July 14, 2022
仰ってるiterはearly stoppingのiterという認識で正しいですか?
num_boost_roundですね。val無しになるのでearly stoppingは使わずです。ちなみに話逸れますが通常の非時系列データの5foldとかでも最終的にはearly stopping使わずにnum_boost_round直接制御の方が、valにoverfitしない分若干強いことが多いイメージです
— YujiAriyasu (@aryyyyy221) July 14, 2022
本文で書いたiterationは、lightgbmだとnum_boost_roundだと話。
num_boost_roundを使わないというのは、検証データでearly stoppingを直接使うのではなく、5foldのearly stoppingがかかったroundの平均値を出して、その値を出すみたいな話ですね。そちらで出したcv scoreの方が見積もりとして正しいと思います。
以上です。意見や質問などあれば、お待ちしています。
コメントお待ちしています。匿名の質問はマシュマロから→https://marshmallow-qa.com/currypurin