
「Europa Universalis: The Price of Power」日本語化プロジェクトとChatGPTの活用方法 Part 4英文テキストの抽出と翻訳方法

Part 4-1: 英文の抽出方法について
翻訳を始めるにあたり、まず説明書の英文を抽出するために、以下の方法を行っています。
説明書をスキャン
スキャンデータをPDFからJPEGへ変換
なぜJPEGに変換するのか?
ChatGPTでデータを抽出する際、PDFは直接読み取れないためです(最新バージョンでは対応しているかもしれませんが)。また、JPEGに変換することで、画像編集がしやすくなるという利点もあります。
説明書のスキャン:
コンビニのコピー機でも、自宅にあるプリンターでも使用できます。例えば、私が使っているのはブラザーの「DCP-J577N」です。8年前の機種ですが、画像スキャン機能があり、問題なく使用できます。
DCP-J577Nの詳細はこちらPDFからJPEGへの変換:
PDFデータは「I Love PDF」で簡単にJPEGに変換できます。
I Love PDFのリンクはこちら
Part 4-2: データの抽出方法について
抽出したJPEGデータをChatGPTに読み込ませる方法は以下の通りです。
データの分割:
まとめて抽出したデータを小分けにして、ChatGPT 4.0に画像を直接貼り付けます。複数の画像を同時に処理できます。



2.文字の抽出:ChatGPTが画像から文字を抽出し、そのまま翻訳も可能です。

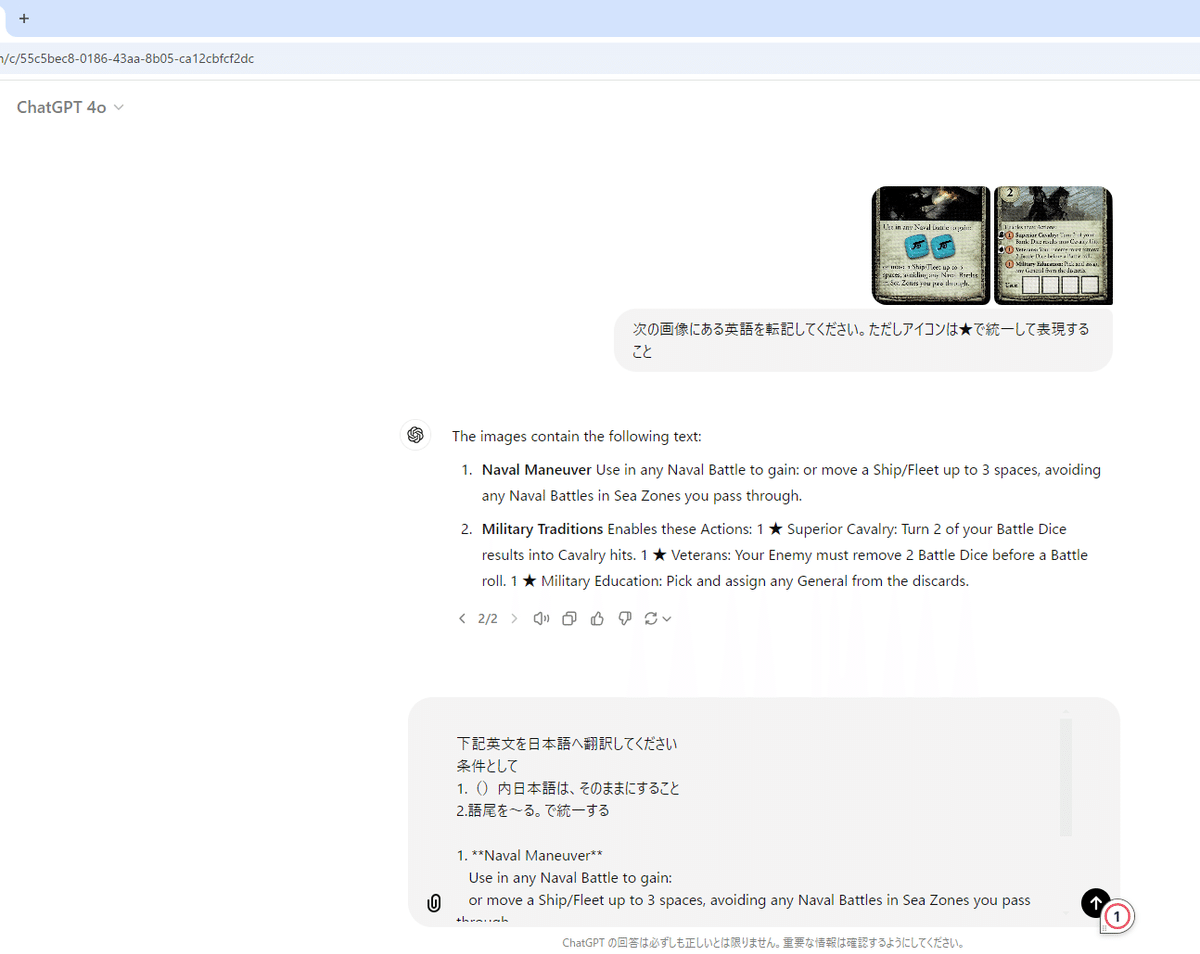

3.翻訳結果の整理:
翻訳したテキストをExcelに入力し、ゲームで使用するカードや説明書に反映させます。
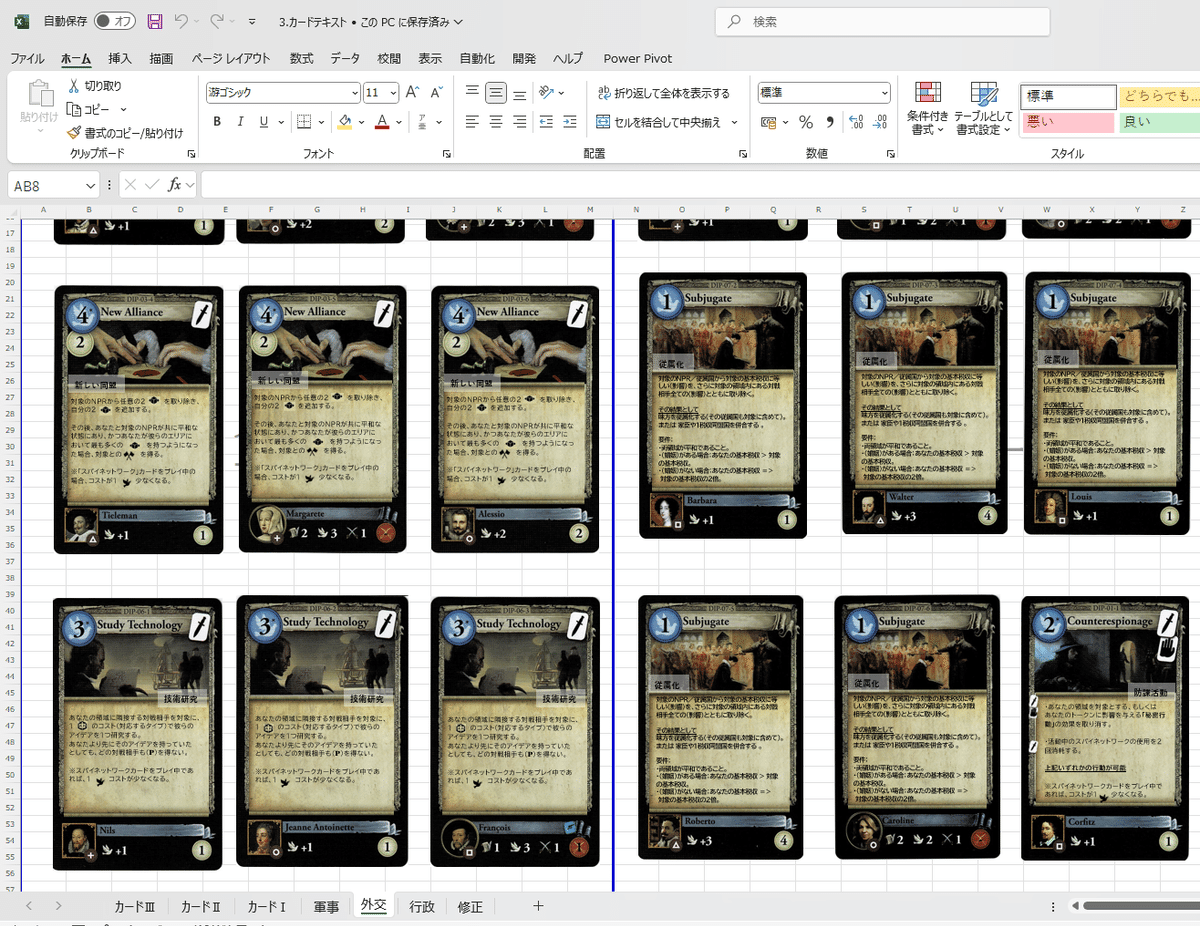
ただし、ChatGPTを使う際には「ゆらぎ」と呼ばれる現象が発生することがあり、生成されたテキストの精度が一定でない場合もあります。この点については、次回詳しく説明します。