pixivイラストタグ共演頻度からポケモン剣盾カップリングを探す

な~~にがキバユウじゃ。キャラ人気だけやろ。
ポケモンをブラックホワイトぶりにやったのだけれど、今回ジムリーダーたち何度も何度も登場しすぎじゃない?
各街に行ってそこのジムリーダー探しに行って、帰ってきてジム戦やってハイ次。って感じじゃなかったっけ。
金銀ルビサファとか保護者キャラはチャンピオンと博士くらいだったのに保護者枠多くない?え?二次創作のせい?薄明の翼は続きを見る度に前回の内容忘れてもう一度見るハメになる?
そんなのもあって二次創作では結構な量の組み合わせの作品があって観ていて飽きない。しかし主人公とラスボスが明確に決まっているゲームの創作である都合上、主人公とボス周りのキャラ人気が高く、「キャラ人気が高いから人気の組み合わせ」なのか「キャラ人気関係なくアツい組み合わせ」なのかがよくわからない。
早い話が"濃い"創作がどこで発生しているのかが見分けにくいので可視化したい。
そういうのもあって剣盾リーグ戦登場人物+御三家ポケのカップリング事情についてpixivイラストの共演頻度をヒントに調べてみる。
こういうイラストの投稿数に依存する分析はキャラクターのパワーが結果に影響することが予想されるので(dndとkbnとかね)、そこはうまく考慮したいところ。
大まかな可視化の流れは以下の通り。
①pixiv「ポケモン剣盾」イラストからタグ情報を取得する
pixivのイラストからタグ情報だけを抽出する必要がある。
今回はPixivpyを使って抽出することに。ドキュメントが中国語で苦労しました。

検索してみると4万件以上ある模様。
全部取得するのはサーバーに負荷かけちゃうし、データハンドリングにも困るので今回は最新3000件を取得する。
# coding: utf-8
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from pixivpy3 import PixivAPI
def search_pixiv(word):
api = PixivAPI()
api.login('xxxxUserIDxxxx', 'xxxxpasswordxxxx')
PER_PAGE = 3000
i = 1
while i:
results = api.search_works(word, page=i, per_page=PER_PAGE, mode='tag')
for illust in results.response:
with open("pokemon_tagslist.csv", "a", encoding='utf_8_sig') as file:
print(illust['tags'], file=file)
p = results.pagination
if p['next']:
i = p['next']
time.sleep(2)
else:
break
search_pixiv('ポケモン剣盾')こんな感じで。
リスト化して連ねるとこんな感じで現れる。
with open('pokemon_tags.txt', encoding='utf_8_sig') as f:
txt = f.read()
source_list = [x for x in txt.split("\n") if x != ""]

②出てきたタグをカウントして、共演頻度を算出する
まずは各投稿ごとに、どのタグが出てきたのかをカウントする。
テキスト解析に良く用いられるBag-of-Words (BoW)利用して、タグの出現をベクトル(数値, 今回は出現回数)で表現します。
BoWとは、その文書が、どのような単語の集合から構成されているかだけに注目して、その文書の特徴をベクトル表現に変換する手法。これで文章の類似度を測ったりする。
今回は取得した投稿のタグの羅列を一つの文書と考えて、それぞれの文書の文書ベクトルを算出する。今回は登場すれば1を振る。
例えば投稿Aのタグが「ダンデ/キバナ/フライゴン」,Bが「ユウリ/ダンデ/リザードン」だったら

これが3000投稿分下に続くイメージ。
下にも続くが、もちろん3000投稿に登場するタグの分だけ列も増えていく。
from sklearn.feature_extraction.text import CountVectorizer
# BoWを作成する準備
# token_patternは、文書中で1単語がどう書かれているかのパターンを指す
# ここではスペース以外の文字が1文字以上続いたものを1単語とする(スペースが来たらそこで単語終わり)
count = CountVectorizer(token_pattern=r'[^\t]+')
# 文書からbowを取り出す
bow = count.fit_transform(source_list)
print('語彙サイズ:', len(count.get_feature_names()))
>>語彙サイズ: 2265
# 語彙サイズは2265であることから、文書ベクトルの次元は2265次元となる
print('---- 語彙リストを出力する。数字はその単語のID ----')
print(sorted(count.vocabulary_.items(), key=lambda x:x[1]))
print('---- 各文書の文書ベクトル ----')
# そのそれぞれの単語のIDの値が1になり、文書に現れていないIDの値は0になっている
vec = bow.toarray()
for i in range(len(source_list)):
print(source_list[i], ':\t', vec[i])
投稿ごとに出現をカウントしたらそれが同時に起きたかどうかをカウントする。
今回は各行に登場/登場ナシで0か1しか値がないので行列の積を取ることで表現できる。
import scipy.sparse as sp
# 行列の積を出す
Xc = vec.T.dot(vec)
# count.vocabulary_.items()は語彙(タグ)のリスト。数字と単語が一対一で対応している。
# 例:[('顔面600族', 2259)... ...]
vocabulary = dict(count.vocabulary_.items())
# 語彙番号とタグ名の辞書の並び順番を変える
def get_swap_dict(d):
return {v: k for k, v in d.items()}
vocabulary = get_swap_dict(vocabulary)
df = pd.DataFrame(Xc)
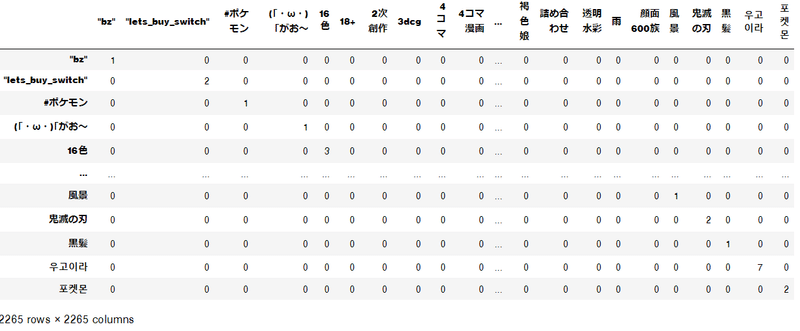
こんな感じでマトリクスになる。
手元で抽出して今回興味あるキャラクターだけのマトリクスをつくるとこう。
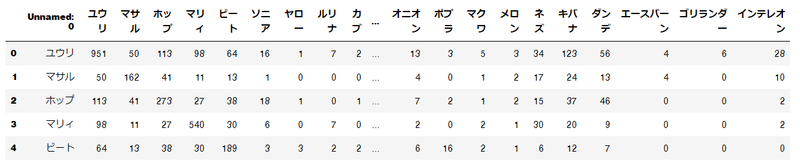
③ネットワーク図に落とす。
今回はnetworkxを使って可視化する。これの理解に1週間かかった。
マトリクスを縦持ちのデータに転置してからnetworkxに放り込む。

ネットワーク図にすると、それぞれのキャラクターの関係図のようなものを描画できる。
関係の強さ、今回でいえば共演回数を図の線の太さで表現する。
こちらに大変にお世話になりました。
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import networkx as nx
G = nx.from_pandas_edgelist(df,'cp2','cp1', edge_attr=['val'], create_using = nx.MultiGraph())
plt.figure(figsize=(25,25))
# エッジの幅(太さ)を指定
edge_width = [ d["val"]*0.1 for (u,v,d) in G.edges(data=True)]
# 配置
pos = nx.spring_layout(G, k=2.5)
# ノード(キャラクター)の設定
nx.draw_networkx_nodes(G, pos, alpha=0.4, node_shape="o",
node_color='blue',
node_size=2000)
# エッジ(関係)の設定
nx.draw_networkx_edges(G, pos, width = edge_width, alpha=1, edge_color="c")
edge_labels = {(i, j): w['val'] for i, j, w in G.edges(data=True)}
nx.draw_networkx_edge_labels(G,pos, edge_labels=edge_labels)
nx.draw_networkx_labels(G, pos, fontsize=10,font_weight="bold",font_family='Hiragino Kaku Gothic Pro')
plt.axis("off")
plt.show()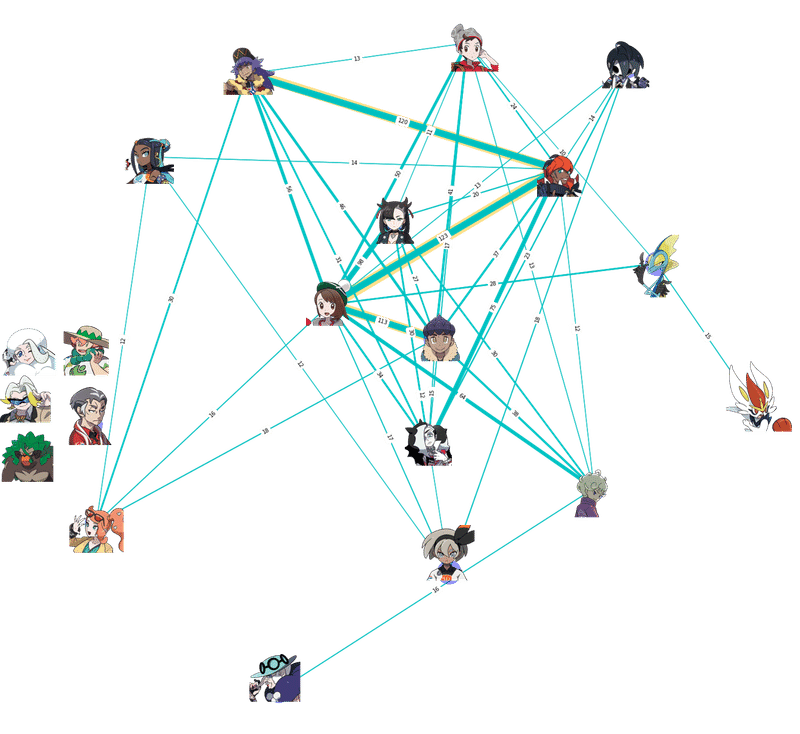
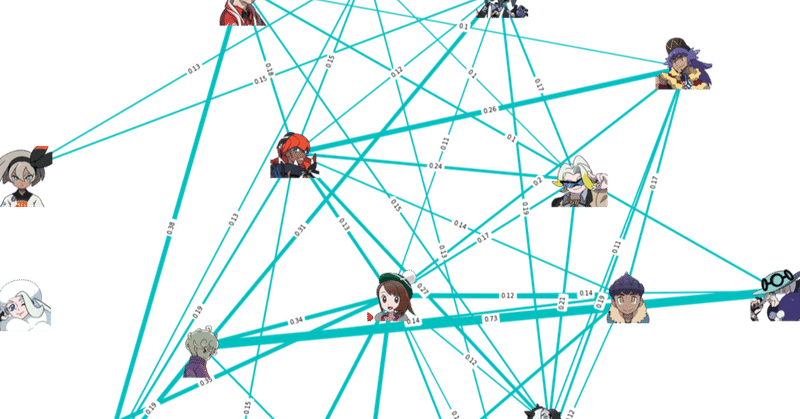
単純に共演回数をカウントしてネットワーク図を描くとこのような感じ。
簡略化のために共演回数10回以下は非表示にすると、そもそも投稿数が少なさそうなキャラクターのネットワークは表示されなかった。
ゴリランダーェ......お前専用技ドラムアタックがデバフ効果ついていて対戦で重宝されるはずだったのに......。
ダンデとキバナ、ユウリとホップ、ユウリとキバナ……と人気(メイン?)キャラの共演投稿数が多いことがわかる。
これではイラストに描かれやすいキャラクターの影響を大きく受けてしまい、「人気キャラのマイナーカップリング」と「マイナーキャラのメジャーカップリング」が同程度に評価されてしまう。
今回興味があるのは「どのカップリングが人気があるのか」ではなく、「どのカップリングが”濃い”のか」であるため、キャラ人気の効果は取り除きたい。
そこで各キャラクターごとにそのキャラ自身のタグ登場数を1、最も少ないカップリング相手との共演数が0になるように正規化する。頻出キャラであるところのキバナも、あまり出てこないゴリランダーも、そのキャラの登場数に対するカップリング相手との共演頻度の多寡を測ることが出来るようになるはずだ。
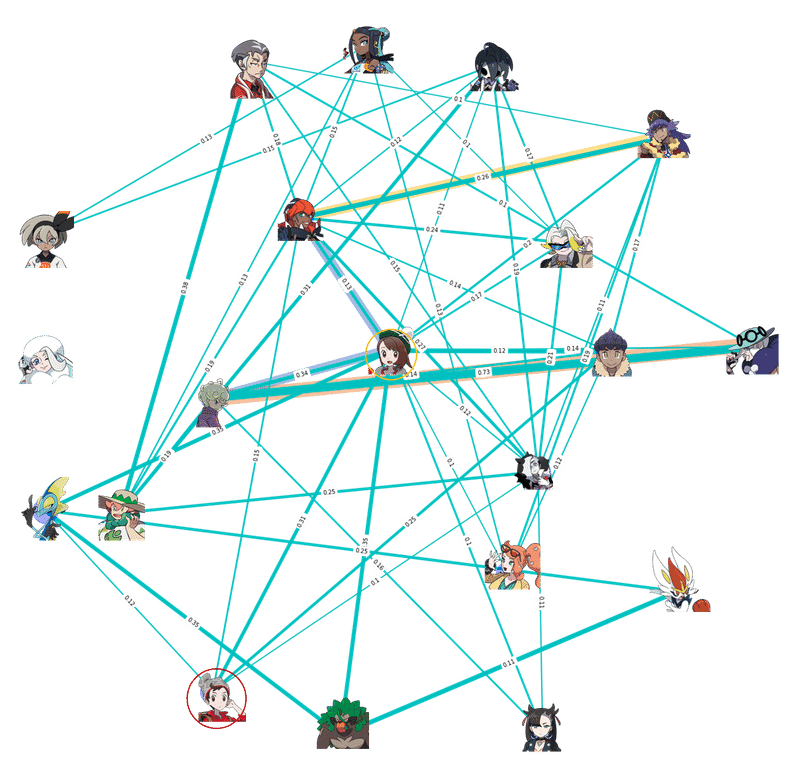
こうなる。今回は見やすくするために0.1未満のエッジ(線)をカットした。
例えばユウリの周りを見ると先ほどは共演相手トップはキバナだったが、
キャラクターの単純な出現回数を考慮すると、共演トップはビート、ということになる。
共演数では肉薄していたユウリとキバナ、ダンデとキバナだが、
先ほどはあまりまだ目立たなかったポプラ-ビートのクソデカ感情(所説)線が見て取れる。
主人公♂♀ズと御三家の関係も少し興味深い。ユウリはインテレオンとゴリランダー双方の共演頻度があるのに対して、マサルはインテレオンのみ、両者ともにエースバーンとの共演頻度は低いことがわかる。エースバーンは顔がレベルファイブっぽかったから夢創作界隈に人気あると予想したけれどそうでもないっぽい。
キャラクターの近辺に線が少ないキャラクターは、そのキャラクターの単純な出現回数に比して、共演の回数が少ないことが推察される。逆に言えばソロでの登場が多いということだが、メロンの周囲に線がないのはそういうこと......である。
以上簡単にポケモン剣盾創作のカップリング事情を可視化した。
創作に最も登場する女主人公ユウリとの共演頻度を、
キャラ人気を抜きにして測ると相手はビートであることがわかった。
今回カップリングでいう所謂呼称の順序を考慮できていないのでそこをきちんとカウントしてあげるともっとちゃんと"カップリング"についてわかりやすい結果になるかもしれない。
今回もともとはスペクトラルクラスタリング、という平たく言えばノード同士の関係をクラスタリングするようなクラスタリング手法に触れる機会があったので、これをネットワーク分析で練習しようと思った。
その第一弾としてネットワークの可視化に触れたかったのが動機。
②で作ったマトリクスを使ってクラスタリングできると、キャラクターたちの関係の近さを可視化できるかと思う。それはまた次回。
この記事が気に入ったらサポートをしてみませんか?