
京大のPython教科書で勉強してみた

はじめに
筆者は2023年3月現在育休中で、5月に復帰予定なのですが、復帰までにPythonの基本を習得したいなあと思って、手始めにかの有名な京都大学のPythonプログラミング演習の教科書を実際に手を動かしながらやってみようと思い立ちました。
本記事はその勉強の記録です。教科書の大事なところの抜粋(というかメモ)、勉強中に感じたこと、少し深く調べてみた内容などを載せています。
ただの個人的なメモなので、有益な内容はほとんどないかもです。
なお、筆者はプログラミング初学者ではないので、0~3章については大体わかるのでスキップします(読むことは読みました)。
ちなみに演習課題で実際に書いたプログラムやその動作は別記事にまとめましたので、興味ありましたらこちらもどうぞ。
3章 変数と演算、代入
この辺は他の言語と大体同じ。
ただ「++」とか「--」はないらしいので要注意。なんでないんだろうな。カウントアップとかカウントダウンをする機会があんまりない想定なのかな。
データ型も一応あるけど、動的型付き言語だから入れた値で型が決まる形式。
複数の変数への代入する時は、以下のように右辺・左辺ともカンマで区切る。入れ替えもできる。
a, b = 1, 2
a, b = b, a # 入れ替えどうでもいいけど、例題で急に平方根を求める式が出てくるところが京大って感じがする(偏見)。京大生はこの式は常識の範囲内なんかな…。平方根の近似値の求め方の説明書いてあったけど、なんとなくで読み流しちゃったわ…。
4章 リスト
リストの基本
いわゆる配列。[]でくくって定義。添え字も[]でくくる。
全部に同じ値を指定したい場合は*が使える。
リストの長さはlen()で確認可(a.len()ではなくて、len(a))。
a = [1, 2, 3, 4]
b = [3]*5空のリストを作成する時はlist()を使う。[]でもよさそう。
リストへの追加はappend()、リストの結合はextend()。
a = list()
a.append("a")
aの中身:['a']
b = ['b', 'bb']
a.extend(b)
aの中身:['a', 'b', 'bb']リストの代入と複製
リストを別の変数に代入すると、中身のコピーではなくてアドレスのコピー的な感じになるので、全く同じものを示す。よって、代入後に代入した変数を操作すると元のリストの中身も変わる。
リストの中身もコピーしたい場合はcopyメソッドを使う。
a = [1, 2, 3, 4, 5]
b = a #aと同じものを示すので、bを操作するとaも変わる
b = a.copy() #リストの中身もコピーするミュータブルとイミュータブルの話
数字や文字列はイミュータブル。
a = 1
b = a # bにaを代入した後、bを操作
b = 2
aの中身:1のまま(bへの変更が反映されない)
bの中身:2リストはミュータブル。
a = [1, 2, 3, 4]
b = a # bにaを代入した後、bを操作
b[0] = 10
aの中身:[10, 2, 3, 4](bへの変更がそのまま反映)
bの中身:[10, 2, 3, 4]浅いコピーと深いコピーの話
リストの要素がリストの場合(二次元配列)、copyメソッドを使ってコピーしても要素までは複製されず、一番上のリストは複製されるものの、その下にぶら下がっているリストは複製元と同じものを示すらしい。
つまりこんな感じ(図はhttps://pythontutor.com/で作成。このサイト超便利)。
a = [[1, 2], [3, 4]]
b = a.copy()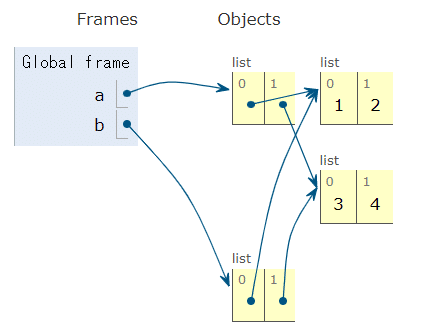
これを浅いコピーという。
これに対して、要素まで完全に複製してくれることを深いコピーという。
深いコピーをするにはdeepcopy()を使えばいいらしい(a.deepcopy()ではなくてcopy.deepcopy(a)であることに注意)。
import copy
a = [[1, 2], [3, 4]]
b = copy.deepcopy(a)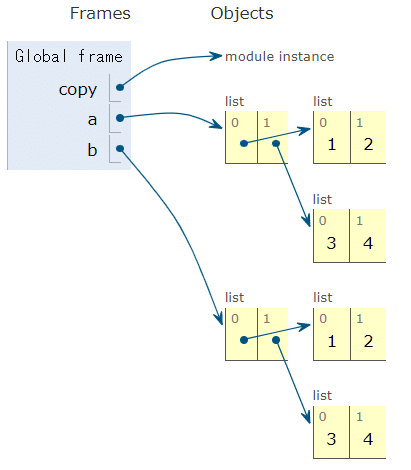
リストの便利技
宣言時に通し番号を入れとく時はlist()の引数にrange()を指定すると便利。
list()の引数に文字列を指定した場合は、1文字ずつに分解されたリストになる。
n = list(range(5))
nの中身:[0, 1, 2, 3, 4]
s = list('abcde')
sの中身:['a', 'b', 'c', 'd', 'e']文字列クラスのsplitを使うと、デフォルトでスペース区切りでリストにしてくれる。区切り文字は引数で指定可。一旦変数に入れなくてもいい。
t = "a bb ccc dddd"
tlist = t.split()
tlistの中身:['a', 'bb', 'ccc', 'dddd']
tlist = "a,bb,ccc,ddd".split(",")
tlistの中身:['a', 'bb', 'ccc', 'dddd']添え字の話
負の添え字も使える。例えばリストが4つの場合は頭が[-4]で一番後ろが[-1](わかりづらい)。
添え字に「先頭番号:終了番号」を指定すると切り出せるが、終了番号に指定したインデックスの手前までになることに注意(わかりづらい)。
a = [1, 2, 3, 4, 5]
b = a[1:4]
bの中身:[2, 3, 4]タプルと辞書の話
[]ではなく()でくくって定義するとタプルになる。添え字も[]でくくる。
タプルは要素への代入は不可。変更されたくない定数とかを入れとく時とかに使うのかも。
辞書(ディクショナリ)は{}でくくって、「"key":”値"」の形でカンマで区切って定義する。キーは[]で指定。
存在しないキーを指定すると追加になる。
dic = { "key1": "aaa", "key2": "bbb"}
dic["key3"] = "ccc" #追加
dicの中身:{'key1': 'aaa', 'key2': 'bbb', 'key3': 'ccc'}キーの存在確認には「キー in ディクショナリ」を使用。
"key1" in dic
TrueちなみにPython3.7(非公式には3.6)から、辞書に入れた順番が保存されるようになったので、辞書をfor文で回すと入れた時の順番通りに出てくるらしい。
5章 制御構造
for文の基本
for文は「for 変数 in リスト」の形式。シェルスクリプトと同じ。
for文の中身は字下げブロックで記載(強制インデント)。
breakとcontinueもある。
for文の最後に「:」が必要。忘れない。絶対に(いつも忘れる)。
list = [10, 20, 30, 40]
for hoge in list:
print(hoge)リストじゃなくて規定回数を回したい時はリストの部分にrange()を指定する。
for i in range(5): # 0から4まで回す
print(i)リストじゃなくて辞書も指定可能(その場合forの後の変数にはキーが入る)。「タプルと辞書の話」にも書いたけど、Python3.7(非公式には3.6)から、辞書に入れた順番が保存されるようになったので、辞書をfor文で回すと入れた時の順番通りに出てくるらしい。
range関数の話
range()は基本1ずつのインクリメントだが、第三引数を指定すると増え幅を指定できる。
for i in range(2, 11, 4):
print(i)
<結果>
2
6
10リストのループの話
リストをループする場合、要素が「for」の後の変数に入るが、これはリストの要素とは別物なので、変数に代入しても値は変わらない。値を変えたい時はリストに添え字を指定して代入する。
a = [1, 2, 3]
for d in a:
d = 4 #これだとリストの中身は変わらない
for i in range(len(a)):
a[i] = 4 # これだとリストの中身も変わるenumerate 関数の話
ループの中で添え字と要素をどちらも使いたい場合は、forの後の変数を「添え字, 要素」の順でカンマで区切りつつ、リストにはenumerate関数を使う。
for i, d in enumerate(a):
print(i, d)ちなみにこれ辞書で使うと1つ目の変数(上で言うとi)に0からの連番、2つ目の変数にkeyが入るらしい(1つ目にキー、2つ目に要素かと思ったら違ったので使えないなーという話)。
for文の内包表記の話
リストの宣言する時にリストの中にfor文を書いてもいいらしい。
この場合はfor文の中身の式をforの前に書く(式はスペース区切りで書くと文法エラーになる)。
list = [ i+10 for i in range(5)]
listの中身:[10, 11, 12, 13, 14]while文の基本
while文には終了条件を指定する。無限ループの場合は「True」を指定。
while文の最後に「:」が必要。忘れない。絶対に(2回目)。
if文の基本
if、elif、else。
「else if」とか「elsif」とかではなくて「elif」(言語によって違いすぎていつもどれがどれだかわからなくなる。for文もそうだけど、Pythonはシェルスクリプトに近いよね。たぶん)。
for文の最後に「:」が必要。忘れない。絶対に(3回目)。
ちなみにswitch文はないらしいので、「elif」で頑張る感じ。
比較の話
数値の場合は普通に「==」とか「!=」とか「<」とか「>=」とか。
文字列の場合も「==」とか「!=」とか。含まれるかどうかには「in」も使える("a" in "abc"みたいな)。
関係ないけどリストに値が含まれるかどうかも「in」が使えるらしい("a" in listみたいな)。
ディクショナリの場合、「in」はキーがあるかどうかの判定になるけど、値があるかどうかの判定は"a" in dic.values()とかにすればいいらしい。
論理演算の話
AND条件とかOR条件には「and」と「or」を使うらしい。「&&」と「||」じゃないので注意。
「not」ってのもあるらしくて、なんぞや?と思ったけど、要するに「!」みたいなものっぽい(if not flagみたいに使う)。
try文の基本
例外処理もちゃんとある。
各文の最後に「:」が必要。忘れない。絶対に(4回目)。
try:
処理
except エラー:
例外処理
except:
その他の例外処理エラーは括弧でくくってカンマ区切りで複数指定可。asで別名に入れ解くことも可能(except エラー as e みたいな)。
この他、elseとfinallyもある。elseは正常終了時に入ってくるやつ、finallyは必ず通るやつ。
数値と文字列の変換・結合
整数ならint()、小数ならfloat()、文字列ならstr()を使って変換可能。
ただし変換できないと例外を投げる。
文字列の結合には「+」を使うが、数字を文字列として結合する場合は必ずstr()で変換する必要がある。
数値をprint()で表示する時にフォーマットを指定可能らしいけど、詳しくは必要になったらググると思うので割愛。指定可能ということだけ覚えておく。
6章 京都の交差点を作る
今までのまとめみたいな内容だったのでスキップ。
print()の便利な使い方として、以下みたいなのがあるってことだけメモ。
print(street[i], end=", ") # 表示した値の後ろに「, 」をつける。
print(*street, sep=", ") # リストをすべて表示して、区切り文字を「, 」とする。7章 関数を使った処理のカプセル化
関数の基本
defで定義。引数は()内に記載。返り値はカンマで区切って複数返却可能(受け取る時は変数をカンマで区切って受け取る。1つの変数で受け取るとタプルになる)。
定義の最後に「:」が必要。忘れない。絶対に(5回目)。
あと処理の頭にシングルクォートでくくって関数の説明を書いたりもできる(docstringというらしい)。
def 関数名(引数):
'関数の説明’
処理
return 返り値返り値はカンマ区切りで複数指定可能で、呼び出し元で複数の変数をカンマ区切りで受け取る(変数1つで受け取るとタプルになる)。
def func(value):
return value + 10, value * 2
value = 3
v1, v2 = func(value) #引数2つで受け取る
print(v1, v2)
v = func(value) #引数1つで受け取る
print(v)
=== 出力結果 ===
13 6
(13, 6)
関数の引数の話
関数を呼び出す側の引数を実引数、呼び出される側の引数を仮引数と言う。
関数内で仮引数に別の値を入れても実引数の値には影響しない。
と、教科書には書いていたので、値渡しなのかなと思って調べたところ、値渡しとも参照渡しとも言いにくい感じで深みにハマったので、メモがてら書いておきます。
公式的には「オブジェクトへの参照の値渡し」らしく、今一つピンとこないので具体的な動きをざっくり書くと、
数値とか文字列とか(イミュータブルなオブジェクト)は関数内の変更は反映されない(変更した段階で元のデータとは別の場所にデータが保存される)
リストみたいなやつ(ミュータブルなオブジェクト)を丸ごと再定義する(a = [1, 2, 3] みたいにする)と変更は反映されない
リストみたいなやつ(ミュータブルなオブジェクト)に追加したり中身をピンポイントに変更したりする(a[1] = 4 みたいにする)と変更は反映される
ということらしい。
変数に変数を代入した後で値を書き換えようとした時と同じ動きになると理解。
このあたりの動きについては、以下の記事に詳細にまとめられています。
では、業務とかで使う時に、イミュータブルなオブジェクトの内容を変更する場合は中身を直接いじったりする(C言語の参照渡しと同じような使い方をする)のかなーと思ってもうちょっと調べたところ、参照するだけで書き換えはしない(書き換えたい時は別変数を用意してreturnする)のが一般的とのこと。使い方は参照渡しではなくて値渡しと同じ。
結局、PythonはC言語とかと違ってreturnでいくらでも返せちゃうから、わざわざ引数の中身を書き換えて戻す必要性がないし、ミュータブルなオブジェクトの中身が書き換えられちゃうのは単なる副作用で、値を書き換えることを意図したものではないんだろうなーと思いました。もちろん場合によっては書き換えた方が良いこともあると思うので、特性を理解した上で使えば良いのかなと。
関数内の変数の話
ローカル変数は関数内でのみ使える。
関数外で定義した変数はすべてグローバル変数になるが、グローバル変数は参照しかできない。
関数内でグローバル変数の中身を変更したい場合は、グローバル変数の頭に「global」とつけてglobal宣言をすると変更可能。
a = 10
b = 20
def func():
global a
a = 100
b = 200
func()
print(a, b)
=== 出力結果 ===
100 20 aのみ変更されている引数に関数を渡す時の話
引数に関数を渡す際は以下のような動作になる。
関数に()をつけて渡す→その関数を実行した結果が引数として渡される
関数に()をつけないで渡す→関数をオブジェクトとして引き渡すことができ、呼び出された関数内で渡された関数を呼び出すことができる。
# () をつけて呼び出す例
def y():
print("y")
def func(f):
print("func()")
func(y())
=== 出力結果 ===
y 先にy()が実行される
func()# () をつけないで呼び出す例
def y():
print("y")
def func(f):
print("func()")
f()
func(y)
=== 出力結果 ===
func()
yデフォルト引数値とキーワード引数値の話
関数の定義で引数の後に「=」で値を指定すると、引数省略した時にその値が入る。
引数がたくさんある時、引数に「引数名=値」の形式で値を指定すると、特定の引数だけ値を指定することができる。
全部デフォルト値を指定しておいて、特定の値だけ変更したいみたいな場合に便利そう。
8章 Turtleで遊ぶ
turtleというプログラム学習用のライブラリを使って遊ぶ章。
画面に図形を描画するみたいなプログラムを書いたことがなかったから(JavaScriptみたいなのは置いといて)、純粋に楽しかったです。
turtle自体を何かに使うことはないと思うので、使い方のメモについては割愛。演習で書いたプログラムは別記事に載せています。
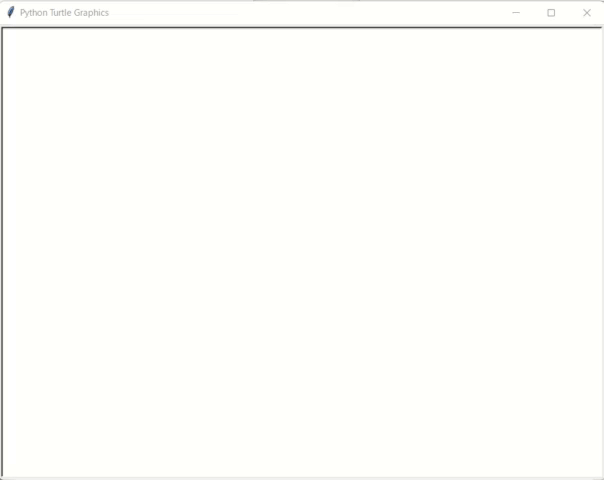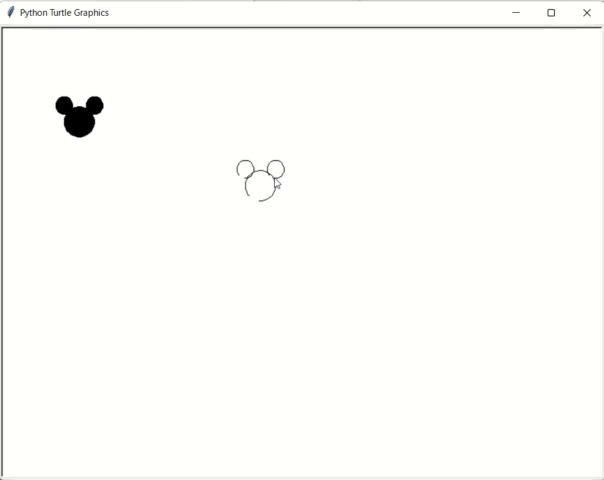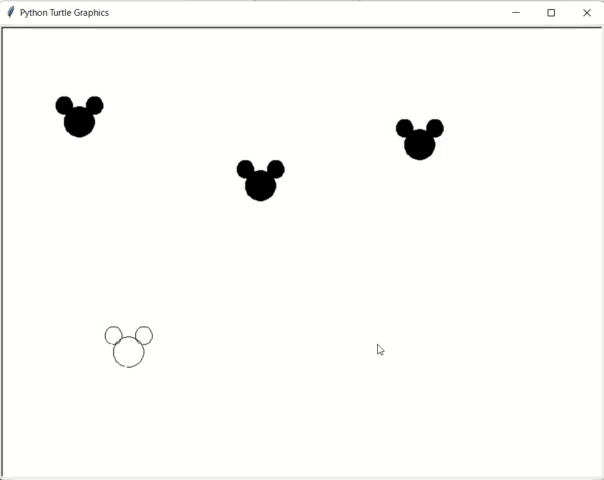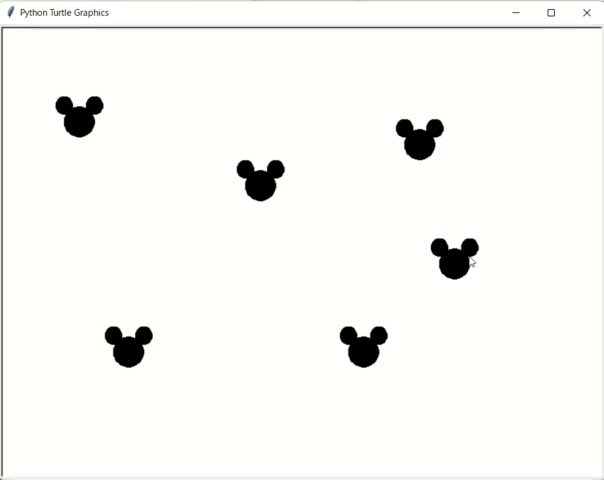
ちなみに最終課題ではこういうのを作りました。
クリックした場所に某キャラのマークを描画します。
9章 Tkinterで作るGUIアプリケーション(1)
tkinkerを使ってGUIアプリケーションを作る章。
うちの会社、新入社員に電卓作る課題を必ず出してたんですが、まさかここでも電卓が出てくるとは思わず。やっぱ電卓作るって基本なんだなあ…いい課題出してるなあと思った次第です。
例によってtkinkerについてのメモは割愛。使うことがあったらその時改めてググる。
lambda表現を使ったcallback関数の記述
tkinkerでボタンの定義をするための
b1 = tk.Button(f, text='1', command=key1)みたいな記述において、「command=」の後は関数オブジェクトじゃないといけない(()なしの形式)。引数を渡そうと思ってうっかり「key(1)」とか書いてしまうと、commandにはkey(1)の返り値が入ってしまうので期待する動作にならない。
「command=」の後に引数付きで関数を指定したい場合は、lambda表現(無名関数)を利用して、無名関数の中でkey(1)を実行するような感じにする。
b1 = tk.Button(f, text='1', command=lambda:key(1))無名関数に変数を渡したい場合は、lambdaの後に「変数=値」で引き渡し可能。
b[i] = tk.Button(f, text=i, command=lambda x=i: key(x)))10章 Tkinterで作るGUIアプリケーション(2)
Tkinterで時計を作っていきます。今回は技術的に目新しいものは出てこなかったので割愛。時計のプログラム初めて書いたけど楽しかった。
11章 クラス
クラスの基本
クラスの定義はこんな感じ。
class クラス名():
メソッドなどの定義クラスのオブジェクトが生成される際に必ず実行されるメソッドは「__init__()」で定義する。クラスのメソッド定義では引数を必ず1つ書かなくはならず、通常「self」という名前で与える。なお、メソッドの呼び出しの際は第一引数は指定不要(省略するとselfが渡される)。
クラス型オブジェクトの定義方法は以下。
変数 = クラス名()クラス変数とインスタンス変数とアクセス制限の話
・クラス変数
クラスの定義でメソッドの外側で定義。「クラス名.変数名」でアクセスできる。クラスで共通な変数として働く。
・インスタンス変数
メソッドの定義の中で「self.」を付けて宣言(メソッドの外側で定義しないでメソッド内でいきなり宣言してよい)。メソッドの定義の中では頭に「self.」を、外では頭に「インスタンス名.」をつけてアクセスできる。インスタンスごとに独立して管理されて、インスタンスが使われている間は値が保持される。
どちらもメソッドの中だけではなく外からも参照や書き換えが可能(アクセス制限は特にない)。
ただし、アンダースコア2つから始まる変数に関しては、メソッドの中でのみ操作可能で、外からは操作不可能。
継承の話
教科書には詳しく書いてなかったけど、継承はこんな感じで定義する。
class クラス名(親クラス名):子クラスの中で親クラスのメソッドを使う時は頭に「super().」を付ける。
子クラスの中で親クラスの初期化処理をしたい場合は、「super().__init__()」みたいに書く。
子クラスの中で親クラスと同じ名前のメソッドや変数を定義すると上書きされる(オーバーライド)。
子クラスの定義の時に、親クラスを複数定義すると多重継承できる。
意外と使うらしい。
class クラス名(親クラス名1, 親クラス名2):演習
9章で作った電卓について、クラスを使用するように修正する課題があったので、9章での演習内容も含めて別記事にソースを記載しておきました。
12章 ファイル入出力
パスの指定の話
パスに「\」が入ってたらエスケープして
filepath = "C:\\aaa\\bb\\ccc.txt"
みたいに書くか、頭に「r」をつけて
filepath = r"C:\aaa\bb\ccc.txt"
みたいに書く。
open、read、write、closeの流れ
file = open('textfile.txt', 'rw', encoding="utf-8")
s = file.read()
file.write(”あああ\nいいい\n")
file.close()openは組み込み関数、read、write、closeはファイルオブジェクトのメソッド。
一行だけ読み込む場合はreadlineメソッドを使う。呼び出しごとに次の行を読み込むような動きになる。
f = open('test.txt', 'r')
s = f.readline()
print(s) # 1行目を表示
s = f.readline()
print(s) # 2行目を表示
s = f.readline()
print(s) # 3行目を表示readで読み込んだ後for文で1行ずつ処理することも可能。
file = open("test.txt”,"r")
for line in file:
処理closeの自動化
with文で開いたファイルはwith文のブロック終了後に自動的に閉じられるので、閉じ忘れ防止のためにwith文を使うと良い。
※asの後はファイルオブジェクト用変数。
with open("test.txt”,"rw") as file:
処理13章 三目並べで学ぶプログラム開発
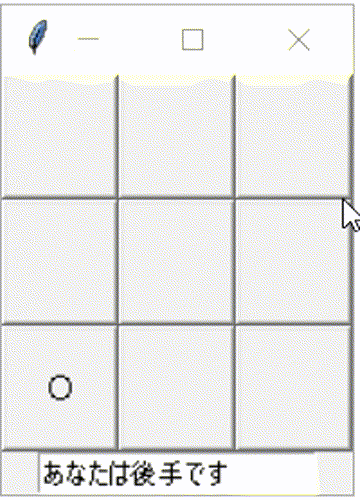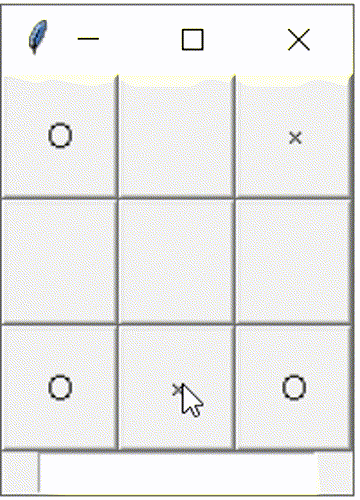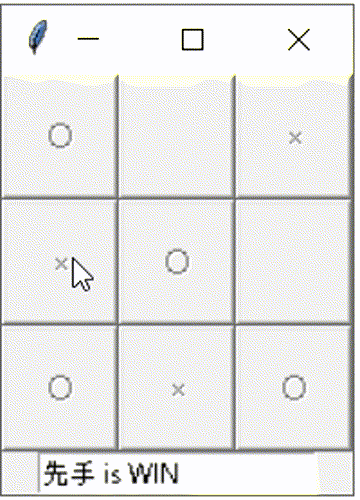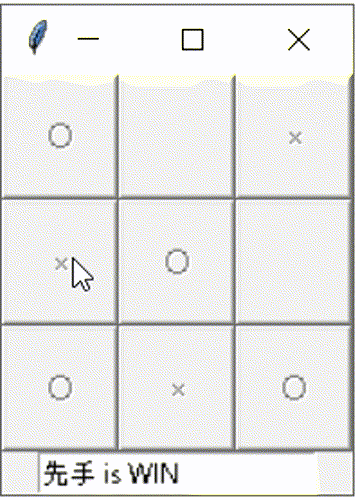
○×ゲームを作る章。書いて動かした結果については別記事の方に書いています。
別記事にも載せてますが、GUI化して対戦相手をNPC化した動作イメージはこんな感じです。少しだけ頭良く動いてます。
14. Python の学術利用
細かい内容については実際に使う時に調べるとして、個人的に今後使うかもなあと思った部分だけメモしておきます。
import 時の別名の話
良く使うライブラリでこの辺の別名はよく使うらしいから覚えておく。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdNumPyの話
科学技術領域での数値計算のための基礎的なパッケージ。
NumPyのリストには固有のデータ型であるndarrayを使う。
ndarrayは通常のリストからnp.array()で生成可能。
全部0とかであればnp.zeros()で生成可能。
#リストから作るパターン
data1 = [1, 2, 3]
arr1 = np.array(data1)
#全部0で生成するパターン
zeroarr = np.zeros(5)ndarray型のデータに対する演算はすべての要素に対して行われる。
元のデータは変更されないので、結果を使いたい場合は別変数に代入必要する必要があるっぽい。
import numpy as np
arr1 = np.array([2, 4, 6])
arr2 = arr1 * 2 # 全要素を2倍([4, 8, 12])
arr3 = arr1 + 1 # 全要素に1加算([3, 5, 7])条件を満たす要素の抽出には、条件を指定するらしい(なんか感覚的にわかりやすいようなわかりづらいような)。
import numpy as np
arr1 = np.array([1, 2, 3, 4, 5, 6, 7])
cond = arr1 % 2 == 1 # condは条件を満たすかどうか(True/False)のリスト↓
print(cond) # [ True False True False True False True]
arr2 = arr1[cond] # Trueだけをスライスして絞り込んでarr2に代入
print(arr2) # [1 3 5 7]
cond = arr1 >= 4
print(cond) # [False False False True True True True]
arr2 = arr1[cond]
print(arr2) # [4 5 6 7]Matplotlibの話
データをグラフにプロットするためのパッケージ。
細かい話は置いといて、こんなソースを描くと大体こんな感じになるというメモ。
<折れ線グラフ>
import matplotlib
matplotlib.use('tkagg') # pyplotのインポートの前に書くのがポイント
import matplotlib.pyplot as plt
matplotlib.rc('font', **{'family':'Yu Gothic'})
#3本の線グラフ
data1 = [np.random.randint(0, 10) for i in range(10)]
data2 = [np.random.randint(5, 15) for i in range(10)]
data3 = [np.random.randint(10, 20) for i in range(10)]
# プロット。第2引数の1つ目は色(k=黒、r=赤、b=青)
plt.plot(data1, 'k-', label = '系列1') #「-」は実線
plt.plot(data2, 'r--', label = '系列2') #「--」は破線
plt.plot(data3, 'b--o', label = '系列3') # 「o」は○のマーカ
#見出しを付ける
plt.title('タイトル')
plt.xlabel('横軸')
plt.ylabel('縦軸')
plt.legend() # 凡例
plt.show()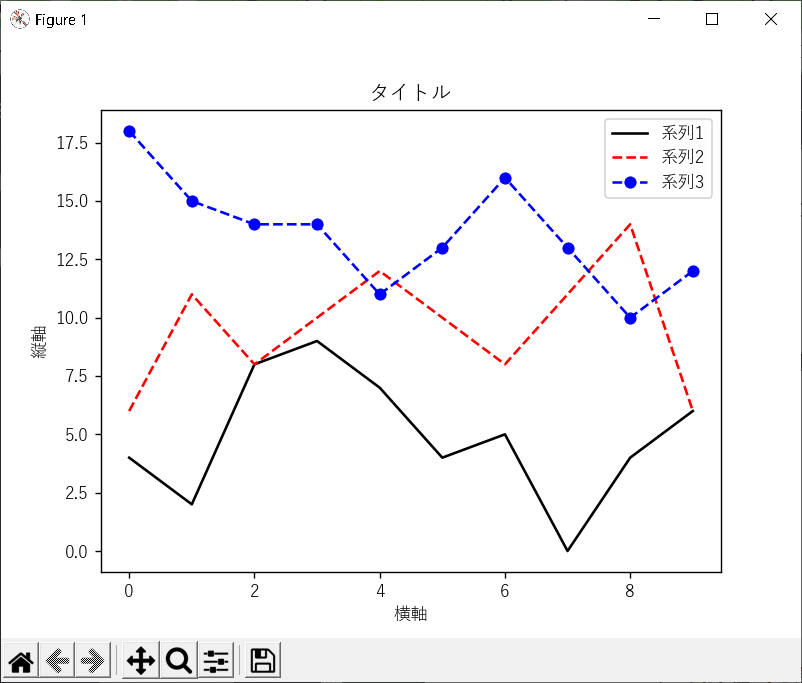
<ヒストグラム>
import matplotlib
matplotlib.use('tkagg') #pyplotのインポートの前に書くのがポイント
import matplotlib.pyplot as plt
import numpy as np
matplotlib.rc('font', **{'family':'Yu Gothic'})
# ヒストグラムの作成
data = np.random.randn(1000)
plt.hist(data, bins=20)
plt.title('ヒストグラム')
plt.xlabel('データの値')
plt.ylabel('頻度')
plt.show()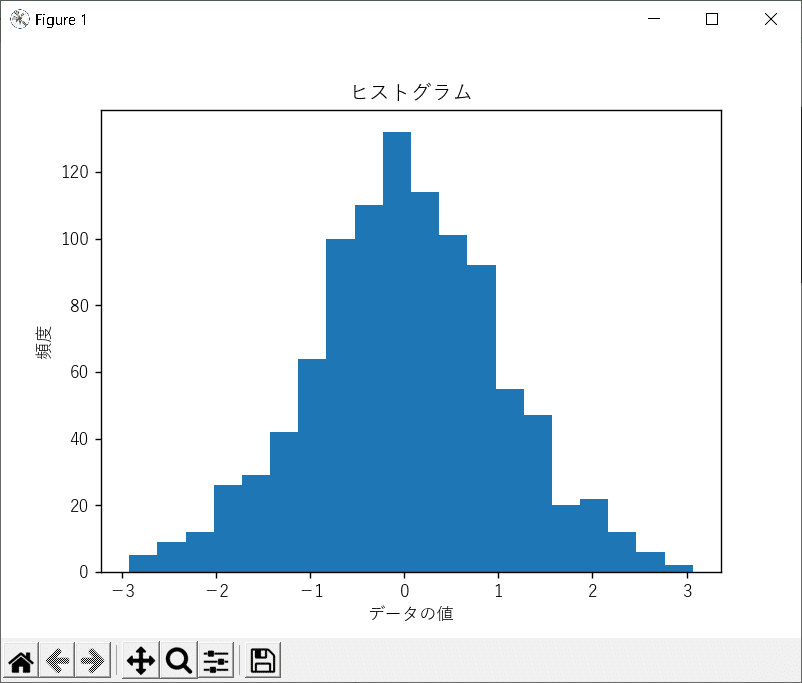
pandasの話
データ分析のためのパッケージ。
こちらも細かい話は置いといて、こんなソースを描くと大体こんな感じになるというメモ。
CSVファイルを読み込んで各種グラフを作成する(ほぼ写経だけど散布図だけなぜかうまく動かなかったのでいったん省略)。
import numpy as np
import pandas as pd
import os
import matplotlib
matplotlib.use('tkagg')
import matplotlib.pyplot as plt
folderpath = input("Enter folder path: ")
os.chdir(folderpath)
df = pd.read_csv("sample.csv")
# 折れ線グラフ
df.plot()
print("次に進むにはグラフウィンドウを閉じてください")
plt.show()
# 積み上げ棒グラフ
df.plot.bar(stacked=True)
print("次に進むにはグラフウィンドウを閉じてください")
plt.show()
# 水平方向(axis = 1) に総和を取り、Totalという列を作る
df['Total'] = df.sum(axis = 1)
# ヒストグラム
df['Total'].plot.hist()
print("次に進むにはグラフウィンドウを閉じてください")
plt.show()
最後の課題は省略(自分がPython使ってやりたいこととちょっと違うからやらなくてもいいかなってのと、作ってもたぶん正解がわからないので)。