[Julia]コツまとめ

算術演算
NaNとイコールか確認する
juliaで値が何もない事を確認する際にNaNを記載して後でNaNであるか確認する様なコードは避けるべきである。実験として記載した下記のコード、実行するとfalseが返ってくる。
test = NaN
test == NaN #結果はfalse
typeof(test) #float64
typeof(NaN) #float64理論的に考えるとtrueになりそうなものだが何か気に入らないらしい。
しかし、下記のコードに書き換えるとなぜかtrueになる。
string(test) == string(NaN) #結果はtrue型がfloat64からstringに変更になっただけでなぜかtrueになる。
ture, falseの場合の戻り値を指定する
if分などを使ってtrue, falseを戻り値としたコードを書く場合に条件の後、下記の様に&&で戻り値を記載しておくとその値が記録される。
function tester(x)
ifelse(x*2 > 10, x%2 == 0 && 3, x%2 != 0)
end
println(tester(6)) #戻り値3not inのやり方
データフレームに対してフィルターを実行する際に使用する事が多いin関数だが逆に含まれていない際の!inが使用出来ないケースがある。その際は以下のようにする。例としてデータフレームの特定列に値が含まれていないケースを考える。
a = DataFrame(a = [1,2,3])
a[((!in).(a.a, [[1,2]])), :]文字列
文字列内のスペースで分ける
文字列を半角スペースで二つに分ける場合は" "の様にしても上手くいかない。そのためisspaceをsplitの引数に使用する。
split("aaa bbb", isspace) → ["aaa", "bbb"]となる文字列リストの中から除外文字がどれも含まれないindexを探す
文字列のリストの中から除外リストに含まれる文字列がどれも含まれないものを探す方法。
testList = ["aaa", "bbb"] #除外リスト
stringList = ["aaaaaaa", "bbbbbb", "cccc"] #文字列リスト
findall(x -> !any(occursin.(testList, x)), stringList) #出力 [3]DateTime / Time
文字列からDateTimeに直す
Date("2020/11/20", "yyyy/mm/dd")文字列からTimeに直す
Time("19:00")関数
関数の引数としてデータフレーム列名を使用する方法
関数を作成する際にデータフレーム列名を引数として指定するケースがあったのだが、これが意外と解決策が見つからない。
結果的にはSymbolを使用すれば簡単だったのでここに記録する。
data_frame = DataFrame(
A = [1, 1, 1, 1, 2, 2, 2, 2],
B = rand(8)
)
function test(df, arg)
for i in groupby(df, Symbol(arg))
println("hi")
end
end
test(data_frame, "A")上記は特に意味のないコードだが使用例として。
列名をStringとして引数に使用しgroupbyで使用する際はSymbol内に記載することで、このケースでは、argはdata_frameの列名を指していることになる。
Symbolはその中に記載されたキーワードがなにと紐づいているかによって結果が変わるそうだ。
一番わかりやすい記事はこれ
symbolの仕様方法はこれから発見
ループ処理
データフレームループ中に行番号を取得する方法
juliaでデータフレームをループする際はeachrowを使用するのが一般的であると思われますが、その際に条件に合った行番号を取得する方法を探すのに苦労したので記録として。
結論rownumberを使用すると簡単だった。
for i in eachrow(df)
println(rownumber(i))
end上記のコードを記載することでそれぞれの行番号を出力可能。
for i in eachrow(df[df.A.==0,:])
println(rownumber(i))
end上記のようなコードを記載しデータフレームから摘出したデータフレームをループする場合では行番号を正しく出力するには至らなかった。出力される行番号はもともとのデータフレーム上での行番号ではなく、摘出したデータフレームの行番号が出力される事になった。
リスト
fillの使い方
juliaで任意の数の任意の値が記載されたリストを作成したい際はfillを使うと容易に出来る。
引数一つ目に値、二つ目に数を記入するとリストを返す。
fill(NaN, 1000000)二つの一次元リストを一つの一次元リストに結合
タイトル通りのリスト結合を望む場合一番簡単だと思われる方法がvcatを使用する方法だ。
vcat(リスト1, リスト2)この方法ならば直感的に使用出来るし、速度も問題なかった。
@benchmark unique(vcat(df[1:1000, :date], df[1001:2000, :date]))
今回はデータフレームから直接2つのリストを作成し、それを合わせるという、僕の一番多い利用ケースで試してみたが、速度は申し分ないのではないだろうか?
条件に合うindexを探す方法の速度比較
リストから条件に合う値のインデックスを取得する方法の比較
a = 1:1:1000
c = rand(1:1000, 1000)
@benchmark (1:length(a))[in.(a, [c])]
a = 1:1:1000
c = rand(1:1000, 1000)
@benchmark findall(x->in(x, c), a)
boolのリストを反対にする
boolリストを反対に、trueとfalseを入れ替える場合は以下のように記載
.!([true, false]) -> [false, true]DataFrame

dataframeの値を変更する際の速度比較
Juliaのdataframeに記載されている値を変更する際の方法による速度変化は目を見張るものがある。
下記の例では毎回dataframeにアクセスし変更する場合と、リストにして一気に変更する方法の例であるが、こんなシンプルなケースでもリストで一気の方が毎回アクセスより平均値が9倍近く短かった。
data_frame = DataFrame(
B = rand(1000000),
C = fill(NaN, 1000000)
)
function test_df()
for i in 1:nrow(data_frame)
data_frame[i, "C"] = rand()
end
end
data_frame2 = DataFrame(
B = rand(1000000),
C = fill(NaN, 1000000)
)
function test_array()
emp = []
for i in 1:nrow(data_frame2)
push!(emp, rand())
end
data_frame2.C = emp
end
@benchmark test_df()
@benchmark test_array()

データフレーム列を数値からDate型へ変更する方法
CSVを元に作成したデータフレーム、たまさか日付がyyyymmddで記入されていることがあります。
そこで列データをtransformで変更する方法を記載しておきます。
方法1
test_df = transform(test_df, :Column2 => (x -> Date.(string.(x), dateformat"yyyymmdd")) => :z)
方法2
test_df = transform(test_df, :Column2 => ByRow(x -> Date(string(x), dateformat"yyyymmdd")) => :z)どちらもColumn2という列に記載されているyyyymmddの数値データへアクセスしそれをDateデータに変更する処理が記載されています。
唯一の違いは個別のデータにアクセスする方法が.関数かByRow関数かの違いです。
参考(僕の質問に有識者の方が回答をくれた質問です。上記にいろいろ書きましたがすべて他人のふんどしです。)
DataFrameに対するfindall複数条件検索とそのスピード
juliaでdataframeを扱う中で一番多い作業が複数の条件に合致する行を見つける作業だが、findallでやるやり方がいまいちわかりずらかったので記載する。
findall((df.one.> 1000) .& (df.two.> 1000) .& (df.three.> 1000))broadcastを使うといけるらしい。
以下は速度。毎度の事で気の毒だがforループさんに比較になってもらう。
上がfindall、下がforループ
function faTest(df)
new = df
findcol = findall((new.open .> 1000) .& (new.low .> 1000) .& (new.close .> 1000))
return findcol
end
function loopTest(df)
new = df
finaldf = []
for i in eachrow(new)
if i.open > 1000 && i.low > 1000 && i.close > 1000
push!(finaldf, rownumber(i))
end
end
return finaldf
end
@benchmark faTest(adjusted_df)
@benchmark loopTest(adjusted_df)
findallで複数のデータフレーム値を参照する方法
findallでデータフレームの値を複数引数として参照する関数を使う方法です。
function canDivide(num)
return num%2 == 0
end
findall(x -> canDivide(x[1], x[2]), collect(zip(df.a, df.b)))DataFrameのGroupby実行時気を付ける事
DataFrameを基にGroupbyを行う際に下記の事を行うと元のデータフレームが更新されないので気を付ける事。
どうやら別のデータフレームとして認識されてしまうらしい。
対象のDataFrameから抜き出し処理をする。
dataFrame[dataFrame.a .== 2, :]みたいな処理
対象のDataFrameをsortする。これ出来そうだけど出来ない
上記の処理は対象となるDataFrameを先に作り処理を行う。
ヘッダーのないcsvをDataFrameとして読み込む
CSVを元にデータフレームを作成する際には下記のようなコードを記載する。
df = DataFrame(CSV.File("path"))この場合読み込んだCSVの最初の行がヘッダーとしてデータセットから抜き取られ、列の名前として使用される。
しかしタイトルがもともと記載されていない場合は困る。
よってheaderパラメーターを使用してヘッダーがないことを伝えてやる。
するとデータはそのままにColumn1, Column2のような自動生成されたタイトルが列名として振り分けられる。参考
df = DataFrame(CSV.File("path", header = 0))データフレームを年別に分ける
juliaのdatetimeまたはdateデータを含むデータフレームを年でgroupbyする方法で少し躓いたので記録を残す。
以外にあっさりとした結論だが、dateデータの列から年だけを取り出した新しい列を作成し、それに基づいてgroupbyにかけてしまうのが一番直感的な方法だろう。
切り出しにはtransformを使うのが良いらしい。参考
transform(df, :date => x->year.(x))上記はdateという列名を含むデータフレームdfが存在することを想定したコードとなっている。dateからyearだけを取り出し新しい列を作成する。新しい列はdate_functionという名前で作成される。名前を指定する方法はまだ勉強不足なため不明。追記しておくとgroupbyで分けるだけならば新しい列を作成する必要もない。上記のtransformコードをgroupbyのdfに記載して分ける列名に:date_functionを指定すればいいだけで新しい列を増やすことなくgroup分けが可能となる。groupby(transform(df, :date => x->year.(x)), :date_function)DataFrameフィルター速度比較
データフレームフィルターの際にどの手法が一番早いかを比較する。
1版:スタンダード
a = DataFrame(a = 1:1:1000)
c = rand(1:100, 1000)
@benchmark a[in.(a.a, [c]), :]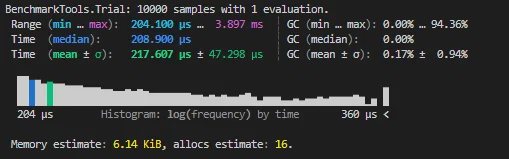
2版:findall
a = DataFrame(a = 1:1:1000)
c = rand(1:100, 1000)
@benchmark a[findall(x-> in(x, c), a.a), :]
DataFrameをフィルターする(リストの値が含まれているか?)
取り出したいデータのリスト内にある値が含まれる行のみをフィルターする際にはinとリストインリストを使用する事で出来る。
a = DataFrame(a=["test1", "test2", "test3"])
sampleList = ["test2"]
final = a[in.(a.a, [sampleList]), :] #データフレームaから "test2"の行だけ取り出せるデータフレームが大きい場合はinオペレーターをフィルターに使うと速度が低下する事が分かった。先にfindallで条件に合致した行番号を取得しその後データフレームを作成する方が多少早い。
a = DataFrame(a=["test1", "test2", "test3"])
sampleList = ["test2"]
found = findall(in(sampleList), a.a)
final = a[found, :] #データフレームaから "test2"の行だけ取り出せるまたfindallは遅いので下の記事で提示されていたsorted_intersect2関数に変更します。
https://discourse.julialang.org/t/indices-of-intersection-of-two-arrays/23043/7
これは引数1リスト内で引数2リストにもある要素のindicesを返してくれます。
function sorted_intersect2(x::AbstractVector, y::AbstractVector)
...
end
inList = sorted_intersect2(df.val, sort(val))
group = df[inList, :]Groupbyで分けたデータフレームに処理を行う
transformを使用してgroupbyで分けたデータフレームに処理を行える。
a = DataFrame(a=rand(1:3, 10), b=rand(1:100, 10))
result = transform(groupby(a, :a), :b => (x -> sum(x)) => :bMean)Dataframeフィルターでのin vs not in
Dataframeを特定列の値がデータ列内に含まれたいと考える際にinを使うのが一般的です。しかし排除するものが残すものに比べて圧倒的に多い際にはnot inを使う方が圧倒的に効率がいいです。
a = DataFrame(a = rand(1:3, 10000), b = rand(1:3, 10000))
@benchmark a[in([1,2]).(a.a), :]
@benchmark a[((!in).(a.a, [[3]])), :]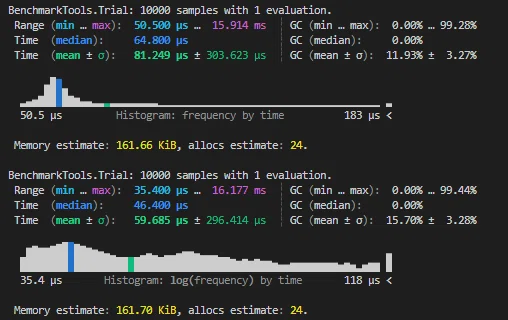
一方過半数以上の要素を入れ替える場合であっても多少早い。
a = DataFrame(a = rand(1:3, 10000), b = rand(1:3, 10000))
@benchmark a[in([1]).(a.a), :]
@benchmark a[((!in).(a.a, [[2,3]])), :]
メタコード
Meta.parseの使用は避ける
Meta.parseの使用はコードを遅くするので出来るだけ使用は避ける。
引数で渡されたリスト内の値を比較するというコードを書いていた際に文字型で入力された比較演算子をifで分岐させずに使用する(↓イメージ)コードを書いていたがMeta.parseの使用は実行速度を著しく低下させた
list = [100, "<", 200] を使用する際に
(1)としていた
↓(1)
price1 = list[1]
com = list[2]
price2 = list[3]
eval(Meta.parse("$price1 $com $price2 "))
↓(2)
if list[2] == "<"
return list[1] < list[3]
end実行スピードを(1)と(2)で比較すると下記の様になる
上が(1)で下が(2)
比較するのが馬鹿らしくなるほど全てにおいて(2)の方が優れている。
コーディングの可読性にここまでパフォーマンスを落とすのは理に適ってない。

$(esc(var))の使用例
オフィシャルドキュメントを読んでもいまいち理解できない$(esc(var))の使いかた、その一例を記載する。
今回はマクロを自作し、それを関数内で使う際に二つが同じ引数を使用する際の例。
macro sma_val(idx)
:(sma(data_frame[$(esc(idx)), :B], n=n-1)[n-1])
end
function func(idx)
dfi = @view data_frame[idx, :]
ifelse(dfi[2, :C] == "A",
dfi[3, :B] > 0.5 && (@sma_val(idx)) > 0.3 && last(idx),
dfi[3, :B] > 0.3 && (@sma_val(idx)) > 0.1 && last(idx))
end上記ではidxがマクロ、関数で共通して使用する引数になっているため$(esc(idx))を記載することでそれを可能にしている。参考
プロファイリング
@benchmarkの使い方(関数の実行速度計測)
自身で作成した関数がどれくらいの速度なのかを計測するプロファイルツールはたくさんあるが、一番使いやすいと感じるのがBenchmarkToolsの@benchmarkである。
単純に何回も計測しなおした結果を使えてくれるツールで、@timeのように一度だけの結果では不安が残るように感じる僕のような人間にはちょうど良い。
関数の前に@benchmarkと記載するだけなので使うのも簡単なのが良い。
@benchmark kansu()また@profileのように何が書いてあるかよく分からない、なんてことがないためにとりあえず使える。
VScodeでProfileViewが使えない対処
Vscodeではreplで実行させるとデバッグ用に自動でロードされるVSCodeServerとProfileViewの@profviewの名前がかぶっているようで、実行するとエラーが出ます。
対処法はProfileView.@profviewと明記する事だが結果の画面が見難い為オススメはしない。
代わりにProfileCanvasを使うと見やすいグラフと数値が表示されるのでおすすめ。参考
ProfileCanvasの使い方
「VScodeでProfileViewが使えない対処」で記載したProfileViewと同じようにProfileCanvas.@profviewと記載すると使用可能。結果が出るまで時間がかかるがエラーではない。
エラー
Juliaを実行するとwindowsが重くなる
juliaを実行しているとwindows自体の動作に1~2秒のラグが生じる事がある。
僕自身の環境での原因はProfileViewやProfileCanvasなどのgtk.jlを使用するパッケージが良くなかったらい。使用する際以外にはusingによる呼び出し?をしない事で解決した。また同症状をstartup.jlにてGTK_AUTO_IDLE=falseにする事で解決する人もいるようだが、僕はそのファイルがどこにあるのかわからなかったので真偽のほどは分からない。
この記事が気に入ったらサポートをしてみませんか?