
JOL2018-4 古テュルク語



LevelC、文字、音韻
■問題の評価と解答のポイント
難しいです。本当にJOLの問題なのでしょうか。少なくとも、この問題を本番で完答するのはほぼ不可能です。(データの数が少ない上、文字の対応の問題と見せかけて複雑な音韻規則も解明しなければならないという罠もあります。)
この解説の最後にもありますが、はじめに、この問題で分析すべき規則の一覧を書いておきます。
・右から左に書く
・狭母音/広母音の間で表記ゆれがある母音は、語頭でのみ広母音に転写されることができる(狭母音も可)
・複数音素を表す文字が使えるときは優先してそれが選ばれる
・音節の構成はCV / VC / CVCのいずれかであり、母音の連続は許されない。また、この構成上、語頭の子音連続と子音の3連続は発生し得ない。
・母音調和が存在し、前舌/後舌で区別される。
・一部の子音は、母音調和に合わせて異なる字を使う
・語頭の母音は、e, aを除き表記する
・語中の母音は、直前に円唇母音+kを表す文字がない場合は省略する。ある場合は表記する。
・語尾の母音は必ず表記する。
お察しの通り、初見ですべて分析するのは不可能です。IOLでも厳しいかと。
一応攻略法を書いておきますと、細かく対象を絞り、それに対して考えられる様々な仮説を検証していくと徐々に規則が見えてきます。
この問題では複数音素を表す文字の特定がポイントになってくるため、他の音素と自動的に接点が少なくなる語頭・語末の文字に注目するとよいでしょう。
この解説は正確なロジックを求めかなり詳細に書かれていますので、飛ばし飛ばし(特に文字の対応の導き方など)お読みください。
■分析に入る前に気付いておくべきこと
まず初めにオルホン文字(突厥(とっけつ)文字と呼ばれることもあります)とラテン文字への転写(以下、「転写」とします)をざっと見ると、全体的にオルホン文字のほうが同じ語に対する文字数が少ないことに気が付きます。このことから、
・オルホン文字には複数音素を表す文字がある
・オルホン文字では省略される文字がある
という2つの可能性を推測することができます(この問題の難しいところは、この規則が両方正しいというところにあるわけですが)。
また、13番目の語を見ると、オルホン文字では「↓」のような文字が語頭に連続しているのが目に止まります。

また、転写でも"(u)k"が2回連続で現れていますが、語尾にあります。そこで、オルホン文字は右から左に書くのではないかと推測することができます。
この先は、方針の定め方が重要となります。オルホン文字とラテン文字の対応関係を特定したいのですが、ここでは子音を先に整理します。理由としては、もし文字が省略される場合、子音を省略する言語はまずないからです。(一方で、アラビア語などでは語頭の母音は表記されません)
■対応の特定①
まずは、何度も現れている子音から分析していきます。転写を見ると、kが計10回使われています。(下図では、kが使われている組に赤丸で印をつけています)

kが現れている語同士を比較すると、ラテン文字のkにあたると考えられる文字が何種類か出てきます。

kが含まれる転写とオルホン文字の組を比較する(共通する文字を探す)と、2種類の文字がkに対応していそうだということが分かります。(共通する文字を探します)
語4、12ではkは語の初めの方に現れるはずですが、他のkが使われている語と共通する文字がそこにないため、ひとまずは保留としておきます(語4の"𐰚"に関しては後述)。
2種類のkに当たるであろうオルホン文字について分析しますが、ここでは語10と13に注目します。
転写を見ると、この2つの語に共通して含まれるのはkとuです。


上の画像のように"↓"がkを表すと仮定し、uを表す文字を探します。


すると、この文字が見つかります。しかし、明らかに数が足りません。そして、現れる場所が明らかに違います(語10・13ともにkに隣り合うuは最後の音節に現れるはずです)。
まずはuにあたるはずの文字の正体を知るために、この文字が他の語にも使われていないか探します。すると、語2, 8に同じ文字"𐰆"が見つかります。語10, 13と、現れる位置から考えると、この文字はoまたはuを表す母音であると推測できます(大胆にこのような推測を立てられるかどうかがこの問題のポイントです。oとuは語2, 8, 10, 13にしか使われていないことに着目すると、これら4つの語すべてのo/uについて説明をつけるには前述のように解釈するのが妥当です)。
語2, 13ではoに、語8, 10ではuに対応しています。


u(とo)に対応する文字"𐰆"の正体が分かったため、uが足りない問題についてもう一度検討します。ここで考えられる可能性は、
・uは表記されていない
・uは他の文字の一部になっている
の2つですが、もう既にuを表す母音が見つかっているため、前者の可能性は考えにくいです。
後者に関して検証すると、uが前の文字の一部であるパターンとuが"↓"の一部であるパターンの2つが考えられます。uが前の文字の一部であると仮定すると、語13で矛盾が発生してしまいます。(↓=ku ということになりますが、2つ目の↓はkとだけ転写されていることになってしまいます。)
uが"↓"の一部であると仮定すると、↓=uk ということになり、語10, 13には適しますが、語8ではkの前の母音はuではなくoとなっています。ここで、"𐰆"の転写がu/oの間で揺れていたことを思い出すと、オルホン文字→ラテン文字の転写では全体的にuとoの表記に揺れがあると推測できます。そのため、↓=uk/ok とするのが妥当です。また、この文字は使えるとき(=uk/okがあるとき)は必ず使うようです。
また、このuとoの使い分けについて調べてみると、
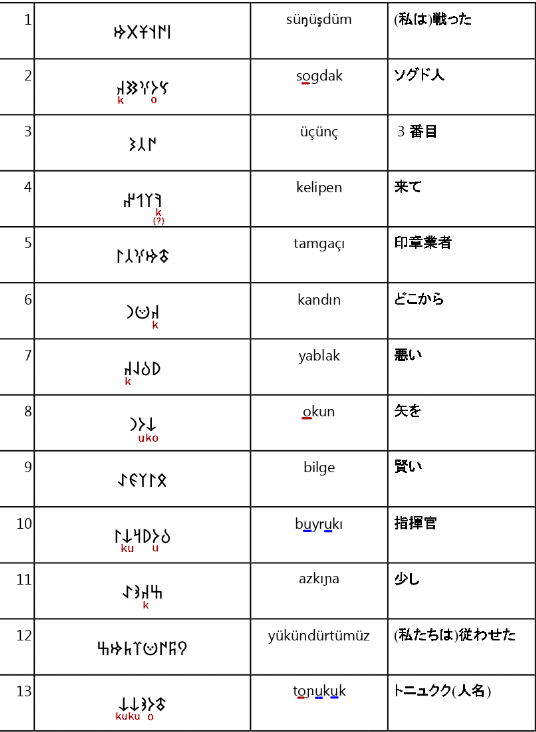
(赤線がo, 青線がuです。)このようになり、oは最初の音節でしか使われ無さそうだということが推測できます。(地味なことですが、後に必要になります。)
また、同じく"𐰴"もkに対応する文字ということが先ほど分かりましたが、こちらは共通して前に母音が現れることもないため、単純に"𐰴"=kとみて良いでしょう。
語12のkに対応するオルホン文字はこの時点ではまだ分かりませんが、語4ではkが語頭に来ており、ここまで二文字を特定する仮定で特に特殊な省略規則などは見つかっていないので、"𐰚"=kとみて良いでしょう。同じくkに対応する"𐰴"との関係が気になるところです。
↓現在の進捗
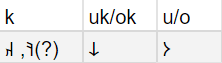

語13に再度注目すると、転写"toɲukuk"のうちo, uk(×2)は既に特定できているため、残りはt, ɲです。オルホン文字を見ると、同じく2文字が残っています。

そこで、"𐰪" , "𐱃"とt, ɲがそれぞれ対応するかどうか検証すると、


この二語に同じ組み合わせが見つかります。未分析の転写の文字が共通しているということもないため、この二組の文字は対応していると考えてよいでしょう。
語13にもtが現れていますが、対応するオルホン文字はこの時点では不明です。
この時点で、語8は"okun"はok, uの分析が終わっているため、残る未解読の文字はnに対応する文字ですが、オルホン文字を見ると同じく未解読の文字は1つしかありません。この文字は語8でも使われており、語末のnと対応すると考えられることから"𐰣"=nと推測できます。他にも転写にnは使われていますが、どのオルホン文字と対応するかはこの時点ではわかりません。
↓現在の進捗


次に、語10に注目します。語10の中に未解読の文字はb, y, r, ıの4つありますが、オルホン文字も未解読の文字の数は4つです。そこで、それぞれ一文字ずつ対応していると考えると

このような予想を立てられます。他に同じオルホン文字が使われている語がないか探すと、"𐰉"と"𐰖"は語7にも現れており、転写にもyとbが見つかります。この2つが対応することは確定とみてよいでしょう。
"𐰺"は語10以外には現れていませんが、語10には他に対応できる文字がないため、ラテン文字のrに対応すると考えてよいでしょう。
"𐰃"は語10ではラテン文字のıに対応しています。この文字は他にも語5, 9で使われており、語5では同じようにıに対応していますが、語9の転写にはıは含まれていません。しかし、転写の表記ゆれが子音と母音の境界を超えることはまずありえないと考えられることや、先ほど分析した母音"𐰆"にも転写の際に表記ゆれがあったことから、語5に2つ含まれる母音のうち語中に現れているiに対応すると予想します。
↓現在の進捗


進捗を整理したついでに、容易に特定できる孤立した文字(一文字としか対応しえない文字)を探します。(語2に関しては"𐰆"の特定が完了した段階でもう分析可能になっていましたが)


転写から考えると、2語とも下線を引いた文字はただ1つのラテン文字と対応せざるを得ません。よって、"𐰽"=s, "𐰋"=bと分かります。
まだいくつか複数回現れる文字があるため、それを分析していきます。 "𐰍"と"𐰠"に注目します。




語2と5の転写に共通して現れているのはaとgですが、出現場所を見るにaには対応しないでしょう。また、"↓"の場合のように母音+子音の複数音素を表す文字である可能性も前後を見るに考えられません。よって、"𐰍"=gであると推測できます。
同様に、語4と9の転写に共通して現れるのはi, e, lですが、語9を根拠にiである可能性、複数音素を表す文字である可能性は否定できます。出現場所から考えるに、"𐰠"=l と考えるのが妥当でしょう。
↓現在の進捗


次に、"𐰇"に注目します。



3語全ての転写に共通しているのはüです。複数音素を表す文字でも無さそうであるため、"𐰇"=üと推測できます。(本当はここで"𐰲", "𐰾"の特定ができますが、見逃しています。あとの方で特定しています。)
また、語9, 11に注目すると、語末の文字が共通しています。


語11ではaを表していることが確定しており、語9ではラテン文字2文字とオルホン文字2文字が対応していて一文字で複数音素を表す可能性が低いと考えられるため、この文字はそれぞれ語末の母音に対応していると考えられます。よって、"𐰀"=a/eと推測できます。
さらに、これによって語9では"𐰏"が孤立したため、"𐰏"=gであると分かります。

↓現在の進捗(分析済みの母音が増えたため別の行に移動しました。調整ミスで見切れていますが上段左から二番目はuk/okです。)


次に、語6, 12に現れる"𐰦"を分析します。これら2語では、ndが共通しています。


語12では、分析済みの"𐰇"(ü)の前に2文字あるため、この"𐰇"は転写では2回目に現れるüにあたると考えられます。このことから、"𐰦"は母音+ndを表す文字ではないと考えられます。が、nd+母音なのか、nd単体であるのかはこの段階では分かりません。そこでついに、音韻規則の分析をする必要が出てきます。
(もちろんもっと早く音韻規則の分析をしても良いですが、1つのラテン文字に対して2つのオルホン文字が使い分けられる場合があることに気づいてからが良いと思います。僕はここで文字の対応の特定に行き詰まったため、音韻規則分析に移行しました。)
■音韻規則の分析
ここでは2種類の分析をします。つい先程問題になった母音の省略規則、そして文字の使い分けに影響しているであろう音韻規則です。母音の省略規則を先に分析したいところですが、まずは音韻規則を分析し、より多くの対応を明らかにしないと省略規則は見えてきません。(この段階ではまだ三種類の母音しか特定できていません)
■母音調和
見出しに書いてしまいましたが、古テュルク語には母音調和があります。文字の使い分けがある場合、母音調和や頭子音交替などの何らかの音韻規則が働いていることが多いです。また、語12の転写にはこれ見よがしに同じ母音が5つ続けて使われています。

普段日本語を使っていると感覚的に分かりづらいかもしれませんが、同じ母音が続くという現象はほぼ母音調和がある言語でしかみられません。(素早く発音しにくいからだと思われます。日本語は伝達性能を犠牲に大量の同音異義語の存在を許したためなんとか基本語の短さを保っています。)
問題の最後に付け加えられた意味深な母音分類表も参考に転写に現れる母音を調べます。
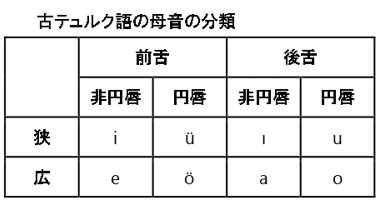

すると、どうやら前舌/後舌で母音がグループ化されているようだということが予測できます。これだけでは確証が持てないため、実際の母音の書き分け(表記ゆれ)を見ていきます。
・"𐰆"=oのとき

・"𐰆"=uのとき


・"𐰀"=eのとき

・"𐰀"=aのとき

・𐰃=ıのとき

・𐰃=iのとき

・"𐰸"=ukのとき


・"𐰸"=okのとき

確かに、前舌母音i, eは"𐰀"=eの表記になっている語9でしか現れておらず、aとıが使われている語11では"𐰀"はaに変化しています。また、"𐰃"も同様に母音調和を受けてı/iの間で変化しています。
また、他にもo/uの書き分けが存在しますが、非円唇/円唇のグループ化があるわけではなく、それらが共存している語もあるため、これは単なる表記ゆれであると考えられます。また、一見するとi, eがüと共存していないため、前舌母音ではさらに非円唇/円唇のグループ化があるように思えますが、語23の転写では非円唇のiと円唇のöが共存しているため、この可能性は否定できます。

次に、子音の使い分けについて分析します。現在分かっている範囲では、k, b, gには子音の使い分けがあります。
・k
"𐰴"



"𐰚"

・b
"𐰉"


"𐰋"

・g
"𐰍"


"𐰏"

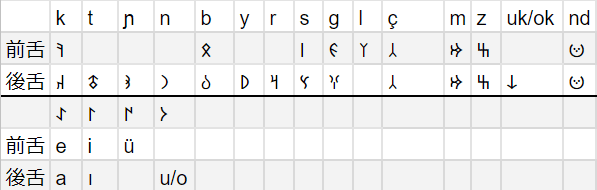
どうやら、子音も母音調和に合わせて調和するようです。母音(子音)調和を考慮して対応表を作ると、

となります(対照が区切り線の上下で異なるのでご注意ください)。
また、与えられた母音表と出来上がった対応表を見比べると、母音調和による転写の使い分け(表記ゆれではありません)のある母音では、前舌/後舌の場合ともに非円唇/円唇と狭母音/広母音の組み合わせが一致しています。(↓下図参照。赤:"𐰀"、緑:"𐰃")
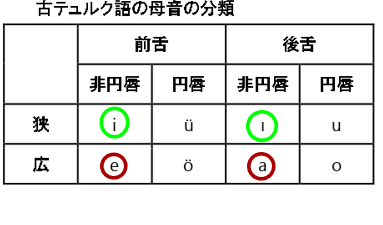
このことをヒントに、今まで1つに特定できなかった文字を新たに特定することができます。
まずはすべての語を前舌/後舌で分類してしまいましょう。

(とりあえず、先ほど特定し忘れた"𐰲"を特定します。語3, 5の転写に共通し、子音は必ず書かれるという規則に当てはまるのはçだけなので、"𐰲"=çと推測できます。前舌/後舌関係なく使われるようです。また、語1の"𐰾"が孤立しているためsと対応することが確定します。)
ここでは、"𐰕", "𐰦", "𐰢" に注目します。
・"𐰢"
語1, 5, 12の転写に共通するのはmです。規則より、母音調和がある場合は前舌/後舌の場合ともに非円唇/円唇と狭母音/広母音の組み合わせが一致しますが、語1でmの前に来るüは円唇の狭母音、語5でmの前に来るaは非円唇の広母音ですので、どちらも母音調和の規則に適しません。よって、"𐰢"が母音+mを表す可能性は否定でき、"𐰢"=m(前舌/後舌の区別なし)であると分かります。
・ "𐰦"
語6の未分析のオルホン文字はあとこの文字一つですが、転写には子音がまだ2つ残っています(nd)。子音が省略されることはまずないため、語12も参照してみると、こちらでもndが現れています。これらのことから、 "𐰦"=ndと考えるのが妥当でしょう。また、母音+ndである可能性は"𐰢"のときと同じように否定できます。前舌/後舌による書き分けはありません。
・"𐰕"
語11を見るとazに対応しそうに見えますが、語12では前にüが来ているため、母音+zとすると母音調和規則に反してしまいます。そのため、"𐰕"=zとし、語11では語頭のaが省略されていると考えます。この文字も、前舌/後舌に関係なく同じ形で使われます。
↓現在の進捗

■母音の省略規則①
ここに来ると、またも子音を1つに特定するのが難しくなってきます。そこで、増えたデータを生かして母音の省略規則を特定します。
最初に問題の概観をみた際に、文字の省略が行われている可能性があると述べましたが。子音が表記上省略される言語というのはまずありません。(日本語は母音の重要度がかなり高い言語ですが、多くの言語は子音の重要度のほうが圧倒的に母音の重要度より高いです。音素の数と漢字という特殊な表記法の存在が影響しているのだと思いますが、何かこれに関する記事や論文、書籍がありましたらぜひ教えて下さい。)
英語では語中の母音が弱化したり発音されなかったりすることがあることや、アラビア語では語頭の母音が省略されることなどを知っていれば、母音が省略されている可能性に思い当たるのはそう難しくないと思います。
まずは、現在分かる範囲で省略されている母音と表記されている母音を整理します。(赤線は省略されている(無表記)母音、青線は表記されている母音です。省略/表記が不明なものには下線を引いていません。)

このデータの分析には少々知識が必要です。実は、表記規則がある場合は語頭/語中/語尾の区別があることが多いです。実際には、アラビア文字、モンゴル文字(縦文字)などがこれにあたります。
表記/無表記と文字の種類を表にして分析します。
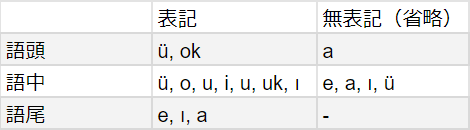
すると、語5, 9, 10, 11の4回全てで表記されている語尾の母音は省略されなさそうだということが分かります。また、uk/okの母音部は当然省略されずに現れます。
しかし、この分類では語中の母音の表記/無表記の区別に規則が見出だせない上、語中のüが表記/無表記両方に属してしまいます(語1, 12)。そこで、今度は「語頭の音節」「語中」「語末の音節」の3つに分類してみます。

語頭の音節では、そこで使われている計6種類の母音を重複なく分類でき、語中のüの問題も解決しました。
しかし今度は、語末の音節のıが両方に属してしまいました(語5, 6, 10)。先ほどの分析から語尾の母音は省略しなさそうだということが分かっているため、分類を「語頭の音節」「語中」「語尾」に改めます。

すると、語頭の音節と語尾に関してはきれいに分類されているものの、またもや語中のüの問題が発生してしまいます。
どのような区切り方をしても何かしらの問題が発生してしまうため、母音の省略にはさらに別の音韻規則が関わっている可能性があると考えられます(言語学オリンピックの問題ですし、データ数も少ないため例外的な綴りを出してくることはまずないでしょう)。データ数が少なく、できるだけきれいな規則を予想して使用したいため、最後の「語頭の音節」「語中」「語尾」の分類を使用し、üの問題はとりあえず保留しておきます。(ここの判断については完全に勘と経験に頼るところとなってしまいますが、言オリで複雑な音韻規則が、それも文字の問題で出ることはおそらくないです。)
語2, 7に、先述の音韻規則から新たに特定できる文字があります。
・語2

語中のaは省略されるため、"𐰑"=daである可能性は否定でき、"𐰑"=d(後舌)であるいと分かります。

・語7

語2の場合と同様に、語中のaが省略されることから"𐰞"=laである可能性が否定でき、"𐰞"=l(後舌)であると分かります。

↓現在の進捗


■母音の省略規則②
残りの文字を特定するには、üの問題を再び考える必要がありますが、その前に下準備として語12について考えます。

語頭の"𐰜𐰘" が "yük"に対応するはずです(※オルホン文字"𐰜𐰘"は左横書きになっています)。ラテン文字3文字に対してオルホン文字2文字が対応しているので、ここでは3つの可能性が考えられます。
①üが省略されている
②"yü", "k"に分けられる
③"y", "ük"に分けられる
しかし、①②を選んだ場合"𐰜"=kとなりますが、kはもう既に前舌/後舌ともに対応する文字が見つかっているため、新たにもう一つの文字が対応するということは考えにくいです。よって、ここでは③を採用し、"𐰘"=y, "𐰜"=ükと推測します。


ukは複数音素を表す文字"↓"に対応しているため、uが表記されなければ困ります。このuk/okを除くと、語中の母音が無表記となっているのは語2, 5, 6, 7, 11, 12の計6件あるのに対し、表記されているのは語8, 12のみです。そこで、ここではu, üに注目して考えていきます。
まず初めにいえることは、前舌母音は語中でも書かれるというような規則があるわけではないということです。語12の最後のüは語中でありながら省略されています。
これらのことから、語8, 12では何か別の音韻規則が働いていると考えます。


よく見ると、問題となっているu, üの前にはともに円唇母音+kの形の2音節が使われています。

この2つはくっついている母音の性質上、それぞれ前舌、後舌のどちらかしか表すことができません。つまり、このようにまとめても良いのではないでしょうか。

これらのことから、円唇母音+kを表す文字の直後の母音は表記されるということが推測できます。(↓最終的な母音の省略規則)

↓現在の進捗

■対応の特定②
また、確定はしないもののある程度ラテン文字転写を推測できる文字もあります。(以下「または」はどちらとも対応するという意味ではなく、どちらかが正しい対応であるという意味で使われています。ご注意ください。)
語3では、"𐰨"とünçが未分析の文字です。子音が省略されることは考えにくいため、
"𐰨"=ünçまたはnçと推測できます。
語1では、"𐰓𐱁𐰭"が"ŋüşdü"に対応しています(オルホン文字は左横書き)。üを表す母音は既に見つかっているため、この中にはü単体を表す文字はないだろうと推測できます。よって、
"𐰭"=ŋまたはŋü
"𐱁"=üşまたはş
"𐰓"=dまたはdü
と推測できます。
iを表す文字が既に分かっていることから、語4でも同様に
"𐰯"=ipまたはp(または考えにくいですがipe、pe)
"𐰤"=enまたはn
と推測できます。
語12では、"𐱅𐰼" が "ürtü"に対応しています(オルホン文字は左横書き)。こちらも同様に、
"𐰼"=ürまたはr
"𐱅"=tüまたはt
と推測できます。
■音節の構造
転写をよく見ると、子音は2つまでしか連続せず、母音は連続しなさそうであることが予想できます。
また、オルホン文字の転写をよく見ると音節の構成素はCV, VC, CVCのいずれかであると考えられます。(C=子音、V=母音)例えば、語11は"zkıɲa"と解釈することもできますが、これでは最初の音節がCCV(またはCCVC)になってしまうため、aが省略されていると解釈し、これを回避しています。
■問題を解く
まだ未分析の文字が残っているじゃないか、と思ったかもしれません。しかし、この時点では子音単体なのか母音+子音の複数音節を表すのか、など正確な特定ができません。そのため、ひとまずは問題を解き進めます。
・語14
"𐰖"は後舌母音のグループのyに対応します。yは半母音とみなされることもありますが、この問題の母音表には含まれていないため、yは完全に子音として扱われていると考えられます。しかし、子音単体だとオルホン文字の音節構造に適さないため、語頭のaが省略されていると解釈し、転写はayとします。(音節が成立する条件として、母音を含んでいることというのが一般的には一番重要です。例えば、フランス語では英語の"there"にあたる"y"がありますが、フランス語ではyは母音として扱われます。)
↓参考:フランス語の母音表。ウィキペディアより

・語15
1文字目に後舌母音グループのbにあたる"𐰉"があるため、この語は後舌母音グループに属すると分かります。
2文字目の"𐰆"はo/uで表記ゆれがありますが、ここでは語頭の音節で使われているため、どちらに解釈しても問題ありません。
3文字目の"𐰑"はdに、4文字目の"𐰣"はnに、それぞれ対応します。
3文字目と4文字目の間には母音がありませんが、このまま転写するとbodn / budnになってしまい、音節構造に適しません(CVCC)。そのため、3文字目と4文字目の間には省略された母音があると考えられます。この単語は後舌母音で、かつこの場所は語頭ではないため、o以外の後舌母音が入ります。
そのため、bodun, bodın, bodan, budun, budın, budanが正答となります。

・語16
1文字目の"𐰦"はndに、2文字目の"𐰀"はeまたはaに対応します。"𐰦"は前舌/後舌に関わらず使える中立的な子音であり、"𐰀"も母音調和によって転写が変化する母音です。そのため、この語は前舌/後舌のどちらとも解釈できます。また、音節構造上、このまま転写するとCCVになってしまうため、語頭に母音が省略されていると考える必要があります。
これらのことから、前舌とした場合は"ende"、後舌とした場合は"anda"が導き出せます。

・語17
語頭の"𐰇"はöまたはü(語頭なのでどちらでもok)なので、この語は前舌母音グループの語だと分かります。
二文字目の"𐱅"に関しては先ほどの対応の特定②で
"𐱅"=tüまたはt
ということが分かっています。オルホン文字では母音の連続は許されないため、"𐱅"=tと分かります。
3文字目の"𐰜"は、語頭の音節ではないためükに対応します。
4文字目の"𐰤"は、対応の特定②にて
"𐰤"=enまたはnだと分かっています。円唇母音+kの文字の直後の母音は省略してはいけないため、"𐰤"=enと解釈します。(実際は"𐰤"=nなので、これは出題ミスか、他のこの問題からはわからない音韻規則があるかのどちらかです。もし詳しい方がいましたら教えて下さい。)
これらのことから、ökükenまたはükükenを導けます。

・語18
1文字目の"𐰴"は後舌母音グループのkにあたるため、この語は後舌母音グループに属します。
2文字目の"𐱁"に関しては対応の特定②で
"𐱁"=üşまたはş
であることが分かっていますが、この語は後舌母音グループの語なので"𐱁"=üşは不適であり、"𐱁"=şだと分かります。しかし、このままだと語頭の音節がCCVになってしまうため、1文字目と2文字目の間に母音を挟む必要があります。ここは語頭なので、省略されていると考えられるのはaのみです。
3文字目の𐰃はı/iを表しますが、母音調和から後舌母音のıと転写するのが正しいです。
これらのことから、kaşıを導けます。
また、語頭でaが省略されていると解釈すると、語頭の音節がVCになるため1文字目と2文字目の間に母音を挟む必要がなくなります(挟む場合、語頭ではなくなるのでo以外の後舌母音をつかいます)。そのため、akşı, akuşı, akışı, akaşıも正答となります。

ここからは、転写からオルホン文字を推測する問題です。
・語19
この語は後舌母音グループに属します。
y="𐰖"
a:語頭の音節なので省略
ŋは、対応の特定②より"𐰭"=ŋまたはŋüと分かっていますが、この語は後舌母音グループなので"𐰭"=ŋとするのが適当です。よってŋ="𐰭"
ı=語中の母音なので省略
l="𐰞"
s="𐰽"
a:語中の母音なので省略
r="𐰺"

・語20
この語は前舌母音グループに属します。
b="𐰋"
e:語頭の音節なので省略
g="𐰏"
l="𐰠"
e:語中の母音なので省略
r:対応の特定②より"𐰼"=ürまたはrと分かっていますが、ürとすると母音が連続してしまうため、r="𐰼"
i:語中の母音なので省略
g="𐰏"
d:対応の特定②より"𐰓"=dまたはdüと分かっていますが、düとすると母音が連続してしまうため、d="𐰓"
e="𐰀"(語尾なので表記)

・語21
この語は前舌母音グループに属します。
t:語17を解く際に"𐱅"=tとわかったためt="𐱅"
e:語頭の音節なので省略
m="𐰢"
i:語中の母音なので省略
r:語20で分かった通りr="𐰼"

・語22
この語は後舌母音グループに属します。
t="𐱃"
ok="𐰸"(※この文字の特定をしたときに少し述べましたが、複数音素を表す文字が使えるときは必ずそれを使います。)
u=𐰆(円唇母音+kを表す文字の直後の母音なので表記)
z="𐰕"

・語23
この語は前舌母音グループに属します。
k="𐰚"
ö:"𐰆"や"𐰸"は語頭では母音が広母音としても転写されることから、普段はüと表記される文字が対応すると考えます。よってö="𐰇"
z="𐰕"
i="𐰃"(語尾の母音なので表記)

↓解答

以上で問題は終了です。
↓問題に解答する過程で新たにわかったものも含む対応表(不確定のものは含みません)


↓対応(不確定のものはカッコを含む書き方になっています)

■規則一覧
・右から左に書く
・狭母音/広母音の間で表記ゆれがある母音は、語頭でのみ広母音に転写されることができる(狭母音も可)
・複数音素を表す文字が使えるときは優先してそれが選ばれる
・音節の構成はCV / VC / CVCのいずれかであり、母音の連続は許されない。また、この構成上、語頭の子音連続と子音の3連続は発生し得ない。
・母音調和が存在し、前舌/後舌で区別される。
・一部の子音は、母音調和に合わせて異なる字を使う
・語頭の母音は、e, aを除き表記する
・語中の母音は、直前に円唇母音+kを表す文字がない場合は省略する。ある場合は表記する。
・語尾の母音は必ず表記する。
☆この解説を作るにあたって、ふるほむ 様(twitter: @fulfom)作成の解答を参考にさせていただきました。ありがとうございました。
↓ふるほむ 様作成の解答
この記事が気に入ったらサポートをしてみませんか?