
[Stable Diffusion]LoRAからトリガーワードを抽出すると世界が広がる

Stable Diffusion系の画像生成AIで凝ったことをすると必要になるのがLoRA等の拡張機能ですが、それも突き進めると配布されているモデルでは物足りなくなることが多々あります。キャラクター然り、画風然り、構図然り……。
そうなるとLoRA学習に手が出ます。
LoRA学習に必要な情報は使用するkohya_ss等の配布ページで解説されており、その情報だけでも入門としては十分だと思います。なんなら巷の解説ページは古新聞になっていることも多々あります。そして、そもそも自分が納得できるものを作るにはキャプションの付け方、学習設定、ステップ数等々はそれなりに試行錯誤が必要です。
……で、試行錯誤するなかで「優れたLoRAはどんな設定で作られているんだろう?」という疑問が湧いてきて、LoRAの中身を覗いたら色々分かったので今回はその一部を紹介します。
個人的に画風LoRAを作ることが多いため「トリガーワードはどのように付けているのか?」に注目しました。
LoRAは最初の方に生成時のメタデータが色々残されており、トリガーワードとなるキャプションに使用されたタグのリストも含まれていますのでこれを読み解きます(※含まないものもあります)。
キャプション抽出スクリプト
これはLoRAをテキストエディタに突っ込んでも見れますが、力技過ぎるのと直感的に分かりにくいのでタグの出現頻度を表示するPythonスクリプトを作成しました(学習ソフトによってファイルフォーマットが微妙に異なり、その辺をうにゃうにゃしていますがもっと綺麗に書けると思います)。
動作確認は手持ちのLoRAです。
適当なファイル名で保存して実行するとファイル名の入力を求められるのでフルパスで指定します。
上位20個を表示します。変更する場合はsorted_items[:20]の値を変更すると良いです。
import json
def read_binary_data(file_path):
try:
with open(file_path, 'rb') as file:
data = file.read()
null_index = data.find(b'\x7D\x7D\x00',8) + 2
space_index = data.find(b'\x7D\x7D\x20',8) + 2
other_index = data.find(b'\x7D\x7D\x80',8) + 2
index = max(null_index, space_index, other_index)
return data[:index]
except FileNotFoundError:
print(f"File '{file_path}' not found.")
return b''
inputfile = input("Input file path:")
json_data = json.loads(read_binary_data(inputfile.replace('"','').replace('\\','\\'))[8:])
try:
tag_dict = dict(list(json.loads(json_data["__metadata__"]["ss_tag_frequency"]).values())[0])
except KeyError:
print("ss_tag_frequency is not found")
exit()
sorted_items = sorted(tag_dict.items(),key=lambda x:x[1], reverse=True)
for key,value in sorted_items[:20]:
print(key,value)
input("Enter to finish.")例を挙げると、切り絵風の画像を作れるmochimochi artstyleではこんな感じ。
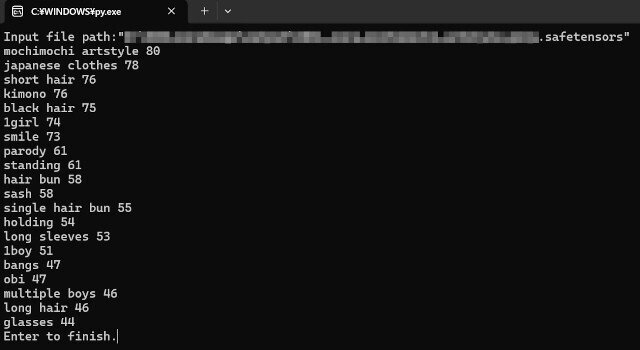
強調したいタグはキャプションファイル1つにつき1つはあるでしょうからそこから使用した画像の枚数も分かったりします。また、副産物としてそのLoRAを使う際の隠されたトリガーワードも分かります。意外なタグがトリガーワードになったりします。
ちなみに上記のLoRAでは見出し画像を含めたこのような画像が作れます。

以上。
この記事が気に入ったらサポートをしてみませんか?