桜の開花日の予測

はじめに
現職では法人営業を務めておりますが、勘と経験による、悪く言えば場当たり的な活動が多くなってしまっていることを感じておりました。再現性のある活動を目指すべく、数字に基づいた分析能力を身に着けたく、また、どうせなら将来のキャリア形成に優位性を持たせられる技術を学びたいと思い、Aidemyさんの『データ分析』の講座で学ばせていただきました。
学習の締め括りとして、分析プログラムを載せたブログを作成してみました。なお、このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。
本記事の概要
今回のプログラムでは、桜の開花予想を行いました。
日本には有名な花見スポットがたくさんあります。これらは、インバウンド旅行者にも人気であることは言うまでもございません。
しかし桜の見頃は約1週間程度しかなく、直前まで開花日の目途が立たないことは、旅行の行き先を決めるにあたりネックとなってしまいます。そこで、過去の気温などのデータから、来年以降の桜の開花予想を立てることができれば旅行者の誘致に役に立つのではないかと考え、モデルを作成してみました。
・学習データ
説明変数:日本の各都市の気象データ
目的変数:日本の各都市の桜の開花日(今回はソメイヨシノの開花日に限定しました)
気象庁が各データを公開している(説明変数は1976年以降、目的変数は1953年以降)。
今回は、1980年から2020年のデータを取得しました。
説明変数データ例:
https://www.data.jma.go.jp/obd/stats/etrn/view/10daily_s1.php?prec_no=44&block_no=47662&year=2021&month=&day=&view=
目的変数データ例:https://www.data.jma.go.jp/sakura/data/sakura003_06.html
2.モデル構築
2.1 実行環境
Python 3.7.11
Windows 10 Pro Ver.2004
Google Colaboratory
2.2 準備
2.2.1 Google Driveのマウント
Google Drive上でデータを保存するために、Google Driveを読込みます。
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/My Drive/Colab Notebooks2.2.2 ライブラリのインストール
学習モデルの特徴量の寄与度の可視化のため、SHAP(https://github.com/slundberg/shap )をインストールします。
!pip install shap
2.2.3 ライブラリのインポート
使用するライブラリをインポートします。
#学習データ作成用ライブラリ
import csv
import time
import requests
import datetime
import numpy as np
import pandas as pd
import itertools
from google.colab import files
from bs4 import BeautifulSoup
#学習用ライブラリ
import lightgbm as lgb
import xgboost as xgb
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.linear_model import ElasticNet
from sklearn.kernel_ridge import KernelRidge
from sklearn.svm import SVR
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import RandomForestRegressor
#モデル評価用ライブラリ
import shap
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import mutual_info_regression
from sklearn.feature_selection import SelectKBest
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
2.3 スクレイピング
2.3.1 説明変数(各都市の気象データ)のスクレイピング
次の記事を参考として、各都市の40年分の気象データを旬単位で取得します。
https://qiita.com/Cyber_Hacnosuke/items/122cec35d299c4d01f10
各都市に対応するURLの数字のリストを作成し、forループでサイトを読込んだ。全スクレイピングデータから気象データが格納されている mtxクラスのtrタグを抽出します。また,「平均現地気圧」等の桜の開花に関係が低いと思われるデータが含まれているため、桜の開花に関係があると思われる降水量、気温、日照量、降雪量のデータのみを抽出します。(桜の開花予想についての以下の記事によると、気温は桜の開花に主に関係するパラメータである。)
https://atsushino1.com/1456.html
place_codeA = [14, 21, 23, 31, 32, 33, 35, 34, 36, 54, 56, 55, 48, 41, 57, 42, 43, 40, 52, 51, 49, 45, 53, 50, 44, 46, 68, 69, 61, 60, 67, 66, 63, 65, 64, 73, 72, 74, 71, 81, 82, 85, 83, 84, 86, 88, 87]
place_codeB = [47412, 47423, 47430, 47575, 47582, 47584, 47588, 47590, 47595, 47604, 47605, 47607, 47610, 47615, 47616, 47624, 47626, 47629, 47632, 47636, 47638, 47648, 47651, 47656, 47662, 47670, 47741, 47746, 47759, 47761, 47765, 47768, 47770, 47777, 47780, 47887, 47891, 47893, 47895, 47762, 47807, 47813, 47815, 47817, 47819, 47827, 47830]
place_name = ["札幌", "室蘭", "函館", "青森", "秋田", "盛岡", "山形", "仙台", "福島", "新潟", "金沢", "富山", "長野", "宇都宮", "福井", "前橋", "熊谷", "水戸", "岐阜", "名古屋", "甲府", "銚子", "津", "静岡", "東京", "横浜", "松江", "鳥取", "京都", "彦根", "広島", "岡山", "神戸", "和歌山", "奈良", "松山", "高松", "高知", "徳島", "下関", "福岡", "佐賀", "大分", "長崎", "熊本", "鹿児島", "宮崎"]
base_url = "http://www.data.jma.go.jp/obd/stats/etrn/view/10daily_s1.php?prec_no=%s&block_no=%s&year=%s&month=&day=&view=p1"
def str2float(str):
try:
return float(str)
except:
return 0.0
if __name__ == "__main__":
for place in place_name:
#データ列名
All_list = [['年月旬', '合計降水量(mm)', '日平均気温(℃)','平均日最高気温(℃)', '平均日最低気温(℃)', '日照時間(h)','平均全天日射量(MJ/㎡)','合計降雪量(cm)']]
#サイト中の全数値データを抽出したい場合
#All_list = [['年月旬', '平均現地気圧(hPa)', '平均海面気圧(hPa)', '合計降水量(mm)', '最大降水量(日)(mm)','最大降水量(1時間)(mm)','最大降水量(10分間)(mm)','日平均気温(℃)','平均日最高気温(℃)', '平均日最低気温(℃)', '最高気温(℃)','最低気温(℃)','平均湿度(%)','最小湿度(%)','平均風速(m/s)','最大風速(m/s)','最大瞬間風速(m/s)','日照時間(h)','平均全天日射量(MJ/㎡)','合計降雪量(cm)','日合計の合計降雪量(cm)','最深降雪量(cm)','平均雲量','雪日数','霧日数','雷日数']]
print(place)
index = place_name.index(place)
scrape_row_index = [3, 7, 8, 9, 19, 20, 23]
for year in range(1980,2022):
#2つの都市コードと年を代入
r = requests.get(base_url%(place_codeA[index], place_codeB[index], year))
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text)
# trタグ,class:mtxを抽出
rows = soup.findAll(class_='data2_s')
rows = soup.findAll('tr',class_='mtx')
# 表の最初の1~4行目はカラム情報
rows = rows[3:]
for i, row in enumerate(rows):
data = row.findAll('td')
rowData = []
if i % 3 == 0:
rowData.append(str(year) + "/" + str(int(np.floor(i / 3)) % 12 + 1) + "/上旬" )
for j in range(1,28):
if j in scrape_row_index:
rowData.append(str2float(data[j+1].string))
else:
continue
#サイト中の全数値データを抽出したい場合
# if j == 16 or j == 18:
# continue
# else:
# rowData.append(str2float(data[j+1].string))
else:
rowData.append(str(year) + "/" + str(int(np.floor(i / 3)) % 12 + 1) + "/" + str(data[0].string))
for j in range(1,28):
if j in scrape_row_index:
rowData.append(str2float(data[j].string))
else:
continue
All_list.append(rowData)
#データの保存
with open(str(place) +'.csv', 'w',encoding="cp932") as file:
writer = csv.writer(file, lineterminator='\n')
writer.writerows(All_list)
2.3.2 目的変数(各都市の桜の開花日)のスクレイピング
以下のコードによって各都市の桜の開花日を読込みます。サイト上の文字列データを列ごとに読込み、スペースによって文字列を分離します。また、各日付を3月1日からの経過日数に変換し、これを目的変数とします。
record_year = ["1981-1990", "1991-2000", "2001-2010", "2011-2020"]
base_url = "https://www.data.jma.go.jp/sakura/data/sakura003_0%s.html"
def str2int(str):
try:
return int(str)
except:
return 0
def inclusive_index(lst, purpose):
for i, e in enumerate(lst):
if purpose in e: return i
if __name__ == "__main__":
for i in range(0,4):
r = requests.get(base_url%(i+3))
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text)
source = soup.find('div',id='main')
te = source.get_text()
te = te.splitlines()
All_date = np.zeros([len(place_name),10])
for j, place in enumerate(place_name):
row_index = inclusive_index(te,place)
seq = te[row_index]
seq = seq.split()
for k in range(0,10):
l = k+1
month = str2int(seq[2*l])
date = str2int(seq[2*l+1])
#2021は仮の数値
flowering_date = datetime.date(2021,month, date)
reference_date = datetime.date(2021,3, 1)
pred_var = (flowering_date-reference_date).days
All_date[j,k] = pred_var
with open(str(record_year[i])+'_flowering.csv', 'w',encoding="cp932") as file:
writer = csv.writer(file, lineterminator='\n')
writer.writerows(All_date)
files.download(str(record_year[i])+'_flowering.csv')
2.3.3 目的変数(各都市の桜の満開日)のスクレイピング
今回はモデル構築に使用しなかったが,桜の満開日を予測する場合は,以下のコードによって満開日のデータを取得することができます。目的変数の設定は,2.2.と同様としています。
base_url = "https://www.data.jma.go.jp/sakura/data/sakura004_0%s.html"
def str2int(str):
try:
return int(str)
except:
return 0
def inclusive_index(lst, purpose):
for i, e in enumerate(lst):
if purpose in e: return i
if __name__ == "__main__":
for i in range(0,4):
r = requests.get(base_url%(i+3))
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text)
source = soup.find('div',id='main')
te = source.get_text()
te = te.splitlines()
All_date = np.zeros([len(place_name),10])
for j, place in enumerate(place_name):
row_index = inclusive_index(te,place)
seq = te[row_index]
seq = seq.split()
for k in range(0,10):
l = k+1
month = str2int(seq[2*l])
date = str2int(seq[2*l+1])
#2021は仮の数値
blooming_date = datetime.date(2021, month, date)
reference_date = datetime.date(2021,3, 1)
pred_var = (blooming_date-reference_date).days
All_date[j,k] = pred_var
with open(str(record_year[i])+'_blooming.csv', 'w',encoding="cp932") as file:
writer = csv.writer(file, lineterminator='\n')
writer.writerows(All_date)
files.download(str(record_year[i])+'_blooming.csv')
2.4 学習
2.4.1 説明変数の読込み
2.3.3で保存した各都市の気象データを読込みます。
path="/content/drive/My Drive/Colab Notebooks"
for i, place in enumerate(place_name):
df_temp = pd.read_csv(path+'/'+str(place)+'.csv', encoding="cp932")
if i == 0:
df_var = df_temp
else:
df_var = pd.concat([df_var, df_temp], axis=0)
print(df_var)
実行結果

2.4.2 目的変数の読込み
2.3.4で保存した各都市の桜の開花日を読込みます。
path="/content/drive/My Drive/Colab Notebooks"
for i, years in enumerate(record_year):
df_temp = pd.read_csv(path+'/'+str(years)+'_flowering.csv', encoding="cp932", dtype=int,header=None)
if i == 0:
df_pred = df_temp
else:
df_pred = pd.concat([df_pred, df_temp], axis=1)
#行と列の数を取り出す
shape=df_pred.shape
year_list = [np.arange(1981,2021)]
df_pred.index = place_name
df_pred.columns = year_list
print(df_pred)
実行結果
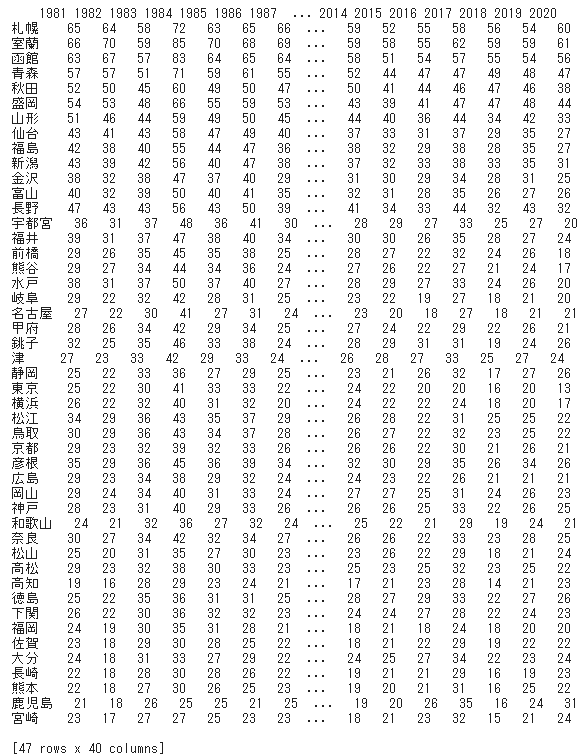
2.4.3 教師データ、テストデータの作成
2.3.1で記載した記事(https://atsushino1.com/1456.html )によると、桜の開花には前年の秋からの気温が影響する。よって、全気象データから前年の10月から3月分のデータのみを抽出し、桜の開花日のデータと合わせて0.8、0.2の割合で教師データとテストデータに分割した。時系列データでランダムに教師データとテストデータを抽出すると、時系列で後のデータによって前のデータを予測するデータリーケージが発生し、実際よりも予測精度が過度に高くなるので(https://napinavi.com/?p=607 )、1981~2012年の32年分のデータを教師データ、2013~2020年の8年分のデータをテストデータとした。また、特徴量ごとのスケールの差を平均化するため、説明変数については正規化を実施した。
all_years = 40
train_years = 32
test_years = all_years - train_years
all_periods = 36 #上旬 /中旬/下旬、12ヶ月
extract_periods = 18 #10月 ~3月分のデータを抽出
place_number = len(place_name)
var_number = len(df_var)-1
X_all = [[0 for j in range(var_number)] for i in range(all_years*place_number)]
Y_all = np.zeros([all_years*place_number])
X_train = [[0 for j in range(var_number)] for i in range(train_years*place_number)]
y_train = np.zeros([train_years*place_number])
X_test = [[0 for j in range(var_number)] for i in range(test_years*place_number)]
y_test = np.zeros([test_years*place_number])
#インデックスを振り直す 。振り直されたインデックスがコラム'level_0'に追加される
df_var = df_var.reset_index()
#データを抽出する始点のインデックス番号を抽出
season_st_index = df_var.index[df_var['年月旬'] == '1980/10/上旬'].tolist()
for i, place in enumerate(place_name):
for j in range(0,all_years):
extract_st_index = season_st_index[i]
#コラム 'level_0'が追加されているので「3」から抽出
X = np.array(df_var.iloc[extract_st_index+all_periods*j:extract_st_index+all_periods*j+extract_periods,2:].astype('str'))
X = np.array(X, dtype=np.float64)
X_all[all_years*i+j] = X
Y = df_pred.iloc[i,j]
Y_all[all_years*i+j] = Y
X_all = np.array(X_all)
Y_all = np.array(Y_all)
for i in range(0,place_number):
X_train[train_years*i:train_years*(i+1)] = X_all[all_years*i:all_years*i+train_years]
X_test[test_years*i:test_years*(i+1)] = X_all[all_years*i+train_years:all_years*(i+1)]
y_train[train_years*i:train_years*(i+1)] = Y_all[all_years*i:all_years*i+train_years]
y_test[test_years*i:test_years*(i+1)] = Y_all[all_years*i+train_years:all_years*(i+1)]
X_train = np.array(X_train)
X_test = np.array(X_test)
X_all = X_all.reshape(all_years*place_number, -1).astype(np.float64)
X_train = X_train.reshape(train_years*place_number, -1).astype(np.float64)
X_test = X_test.reshape(test_years*place_number, -1).astype(np.float64)
#説明変数を正規化
X_scaler = StandardScaler()
X_all = X_scaler.fit_transform(X_all)
X_train = X_scaler.fit_transform(X_train)
X_test = X_scaler.fit_transform(X_test)
print(X_train)
print(X_train.shape)
print(y_train)
print(y_train.shape)
実行結果

上画像は、説明変数および目的変数の教師データを表示したものである。説明変数では、「合計降水量(mm)」等の7個の特徴量が全47都市の32年間について旬単位で6ヶ月分まとめられている。目的変数では、桜の開花日(3月1日からの経過日数)が全47都市の32年分まとめられている。
2.4.4 特徴量の削減
以下の記事を参考にして、特徴量を削減した。目的変数と各特徴量の相互情報量を計算し、全126個の特徴量について、目的変数との関係が大きい(相互情報量が大きい)順にグラフに表示した。そして、特徴量を半分(相互情報量の上位63個)に削減した。また、目的変数との関係が大きい特徴量の種類を確認するため、各特徴量の番号について、特徴量は全7種類あるため、番号を7で割った余りを計算して表示した.
https://qiita.com/shimopino/items/5fee7504c7acf044a521
MI = mutual_info_regression(X_train, y_train)
MI_sort = pd.Series(MI)
MI_sort.sort_values(ascending=False).plot(kind='bar', figsize=(20,10))
kbest_sel_ = SelectKBest(mutual_info_regression, k=63)
kbest_sel_.fit(X_train, y_train)
mask = kbest_sel_.get_support()
X_train = kbest_sel_.transform(X_train)
X_test = kbest_sel_.transform(X_test)
MI_idx = np.array(MI)
MI_idx = np.argsort(MI_idx)[::-1]
MI_mod = MI_idx % 7
print(MI_mod)
実行結果

上図から、特徴量の番号が7で割った余りが「1」および「2」のパラメータが目的変数との関係が大きいことが確認できる。2.4.1のコード中の特徴量をまとめたリストAll_listから、これらの値はそれぞれ「日平均気温(℃)」、「平均日最高気温(℃)」であり、この結果は地域間の気候の寒暖差によって桜の開花日が実際に異なっていることと対応していると考えられる。また、特徴量の番号が7で割った余りが「0」のパラメータが目的変数との関係が小さい。この値は「合計降水量(mm)」であり、この結果は冬は寒冷な地域では主に雪が降り、温暖な地域では雨が降ることが少ないことと対応していると考えられる。
2.4.5 学習モデルの作成
以下のコードによって、複数のアルゴリズムの回帰モデルを作成した。線形重回帰、Lasso回帰、Ridge回帰、カーネルリッジ回帰、ElasticNet、サポートベクトル回帰、勾配ブースティング回帰、XGBoost回帰、ランダムフォレスト、LightGBMについて5分割のk分割交差検証を実施し、決定係数によってモデルを評価した。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
def model_fit(model):
m_name = type(model).__name__
model.fit(X_train, y_train)
#目的変数は整数であるため 、予測値をintに変換
y_pred_model = model.predict(X_test).astype(int)
print('R2_'+m_name+':{:.3f}'.format(r2_score(y_test, y_pred_model)))
#k分割交差検証
splits = KFold(n_splits=5, shuffle=True)
KFold_scores = np.zeros(5)
for i, (train_index, test_index) in enumerate(splits.split(X_train, y_train)):
X_train_k, X_val_k = X_train[train_index], X_train[test_index]
y_train_k, y_val_k = y_train[train_index], y_train[test_index]
model.fit(X_train_k, y_train_k)
y_pred_model = model.predict(X_test).astype(int)
KFold_scores[i] = r2_score(y_test, y_pred_model)
print('R2_'+m_name+'_KFold:{:.3f}'.format(np.mean(KFold_scores)))
def model_fit_dnn():
model = Sequential()
model.add(Dense(256, input_dim = X_train.shape[1]))
model.add(Activation('relu'))
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam')
m_name = "dnn"
model.fit(X_train, y_train,
epochs= 30, # エポック数
batch_size= 16, # バッチサイズ
verbose=0,)
#目的変数は整数であるため 、予測値をintに変換
y_pred_model = model.predict(X_test).astype(int)
print('R2_'+m_name+':{:.3f}'.format(r2_score(y_test, y_pred_model)))
#k分割交差検証
splits = KFold(n_splits=5, shuffle=True)
KFold_scores = np.zeros(5)
for i, (train_index, test_index) in enumerate(splits.split(X_train, y_train)):
X_train_k, X_val_k = X_train[train_index], X_train[test_index]
y_train_k, y_val_k = y_train[train_index], y_train[test_index]
model.fit(X_train_k, y_train_k)
y_pred_model = model.predict(X_test).astype(int)
KFold_scores[i] = r2_score(y_test, y_pred_model)
print('R2_'+m_name+'_KFold:{:.3f}'.format(np.mean(KFold_scores)))
if __name__ == "__main__":
#線形重回帰
model_linear = LinearRegression()
model_fit(model_linear)
#Lasso回帰
model_lasso = Lasso()
model_fit(model_lasso)
#Ridge回帰
model_ridge = Ridge()
model_fit(model_ridge)
#KernelRidge回帰
model_kridge = KernelRidge(alpha=0.0004, kernel='rbf')
model_fit(model_kridge)
#ElasticNet
model_elastic = ElasticNet(l1_ratio=0.4)
model_fit(model_elastic)
#サポートベクトル回帰
model_svm = SVR(C=1.0, kernel='rbf', epsilon=0.1)
model_fit(model_svm)
#GradientBoosting
model_gbr = GradientBoostingRegressor(n_estimators=20, random_state=42)
model_fit(model_gbr)
#XGBoost
model_xgb = xgb.XGBRegressor()
model_fit(model_xgb)
#ランダムフォレスト
model_rfr = RandomForestRegressor(n_estimators=10, random_state=42)
model_fit(model_rfr)
# LightGBM
lgbm_params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': {'rmse'},
'learning_rate': 0.05,
'num_leaves': 30,
'min_data_in_leaf': 1,
'verbose': 0
}
#深層学習で回帰分析
model_fit_dnn()
#k分割交差検証
splits = KFold(n_splits=5, shuffle=True)
KFold_scores = np.zeros(5)
for i, (train_index, val_index) in enumerate(splits.split(X_train, y_train)):
X_train_k, X_val_k = X_train[train_index], X_train[val_index]
y_train_k, y_val_k = y_train[train_index], y_train[val_index]
lgb_train = lgb.Dataset(X_train_k, y_train_k)
lgb_eval = lgb.Dataset(X_val_k, y_val_k, reference=lgb_train)
model_lgbm = lgb.train(lgbm_params, train_set=lgb_train, valid_sets=lgb_eval)
y_pred_lgbm = model_lgbm.predict(X_test).astype(int)
KFold_scores[i] = r2_score(y_test, y_pred_lgbm)
print(r2_score(y_test, y_pred_lgbm))
print('R2_LightGBM_KFold:{:.3f}'.format(np.mean(KFold_scores)))
実行結果

上画像のように、Lasso回帰、ランダムフォレストのみk分割交差検証によって決定係数が増加した。
2.5 学習モデルの評価
各モデルの決定係数を棒グラフで比較した。各モデルの決定係数は、k分割交差検証を実施した時と実施しなかった時の値を比較し、より大きい値を選択した。
model_result = {'Linear': 0.749, 'Lasso': 0.778, 'Ridge': 0.753, 'KernelRidge': 0.792, 'ElasticNet': 0.745, 'SupportVector': 0.811,
'GradientBoosting': 0.815, 'XGBoost': 0.816, 'RandomForest': 0.799, 'LightGBM': 0.825 ,"dnn":0.806}
model_result = model_result.items()
x, y = zip(*model_result)
plt.figure(figsize=(20,8))
plt.bar(x, y, width = 0.5)
for x, y in zip(x, y):
plt.text(x, y, y, ha='center', va='bottom',fontsize=14)
plt.tick_params(axis='x', which='major', labelsize=14)
plt.tick_params(axis='y', which='major', labelsize=14)
plt.xlabel('Model',fontsize=20)
plt.ylabel('R2', fontsize=20)
plt.ylim(0,1.0)
plt.show()
実行結果

上画像のように、決定係数は0.74~0.83程度で、強い相関のあるモデルを構築できた。XGBoost回帰(決定係数0.83)が最も予測精度がよく、LightGBM(決定係数0.822)、勾配ブースティング回帰(決定係数0.818)、ランダムフォレスト(決定係数0.799)と合わせて決定木系の学習手法の予測精度が比較的高い。また、線形回帰(決定係数0.738)、Ridge回帰(決定係数0.745)の予測精度が比較的低いが、これは学習に使用した特徴量が63個と比較的多かったことによるものと考えられ、さらに特徴量を削減することでこれらの学習手法の予測精度は向上すると考えられる。
また、XGBoost回帰および勾配ブースティング回帰について、予測値と実測値を散布図で比較するとともに、予測値と実測値の残差を散布図で表示した。
def scatter_data_preview(model):
y_pred = model.predict(X_test)
m_name = type(model).__name__
max_val = 80
min_val = 10
plt.figure(figsize=(6,6))
plt.title(m_name,fontsize=14)
plt.scatter(y_pred, y_test)
plt.plot([min_val, max_val], [min_val, max_val])
plt.xlim(min_val,max_val)
plt.ylim(min_val,max_val)
plt.tick_params(axis='x', which='major', labelsize=12)
plt.tick_params(axis='y', which='major', labelsize=12)
plt.xlabel('y_pred',fontsize=14)
plt.ylabel('y_test',fontsize=14)
plt.grid()
if __name__ == "__main__":
scatter_data_preview(model_xgb)
scatter_data_preview(model_gbr)
実行結果


def residual_data_preview(model):
y_pred = model.predict(X_test)
m_name = type(model).__name__
plt.figure(figsize=(6,6))
plt.scatter(y_pred, y_pred - y_test)
plt.hlines(y=0, xmin=20, xmax=70)
plt.title(m_name,fontsize=14)
plt.xlabel('y_pred',fontsize=14)
plt.ylabel('residuals',fontsize=14)
plt.xlim(0,80)
plt.ylim(-10,20)
plt.grid()
if __name__ == "__main__":
residual_data_preview(model_xgb)
residual_data_preview(model_gbr)
実行結果
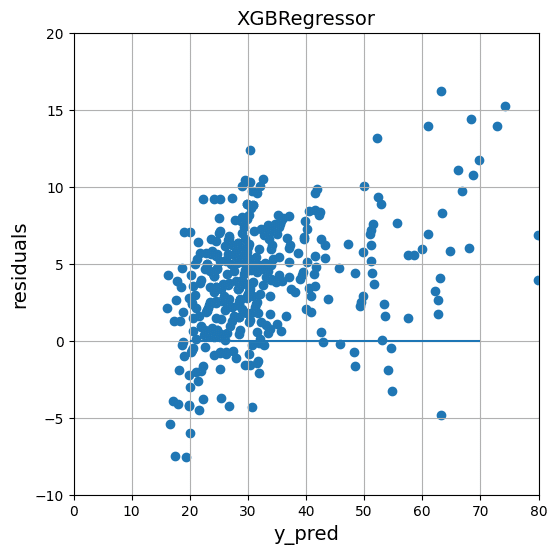

上図から、目的変数に対して強い相関のある予測ができており、予測誤差の範囲はおおむね-5~10日であることが確認できる。
また、以下の記事を参考として、学習モデルの解析手法SHAPによってXGBoost回帰の各特徴量の重要度を表示した。
https://blog.amedama.jp/entry/shap-lightgbm
def shap_data_preview(model):
explainer = shap.TreeExplainer(model, data=X_train)
X_train_shap_values = explainer.shap_values(X_train)
shap.summary_plot(shap_values=X_train_shap_values,
features=X_train)
shap.summary_plot(shap_values=X_train_shap_values,
features=X_train,
plot_type='bar')
if __name__ == "__main__":
shap_data_preview(model_xgb)
実行結果


上図より、「特徴量51・40・59・56」の重要度が特に大きい。この特徴量について確認するため、2.4.4.で記述した特徴量削減のコードに追加して、削減後の特徴量の行番号を表示した。
def params_index_print(X,Y):
idx_num = len(X)
params_index = []
for i in range(0,idx_num):
param_num = X[i]
temp_index = [i for i, x in enumerate(Y) if x == param_num]
params_index.append(temp_index)
print(params_index)
if __name__ == "__main__":
#特徴量削減前のデータ
MI = mutual_info_regression(X_train, y_train)
MI_sort = pd.Series(MI)
kbest_sel_ = SelectKBest(mutual_info_regression, k=63)
kbest_sel_.fit(X_train, y_train)
mask = kbest_sel_.get_support()
MI_idx = np.array(MI)
MI_idx_sorted = np.argsort(MI_idx)[::-1]
MI_idx_res = MI_idx_sorted[:63]
MI_idx_res_sorted = sorted(MI_idx_res)
params_list = [MI_idx_res_sorted[51], MI_idx_res_sorted[40], MI_idx_res_sorted[59], MI_idx_res_sorted[56]]
print(params_list)
params_index_print(params_list, MI_idx_res)
実行結果

上画像のように、特徴量削減後の「特徴量51・40・59・56」は特徴量削減前の「特徴量106・86・120・114」に対応した。この特徴量は、それぞれ「3月上旬の日平均気温(℃)」、「2月上旬の平均最高気温(℃)」、「3月下旬の日平均気温(℃)」、「3月中旬の平均最高気温(℃)」に相当する。これらの特徴量の目的変数との相互情報量は、全84個中で1・11・5・4番目であった。目的変数との関係が大きい特徴量がXGBoost回帰においても重要な特徴量となっていることを確認できる。
3 予測精度向上のための今後の方策
気象庁公開のデータを用いて、桜の開花日の予測モデルを作成した。今回の結果では,予測モデルの決定係数は最大0.83で、強い相関を確認できた。
以下、さらに予測精度の高いモデルを作成するために考えられる方策を4点記述する。
3.1 変数の設定の変更
今回は、10月~3月の気象データを説明変数とした。また、目的変数は3月1日からの経過日数とした。
ここで、説明変数の抽出期間や目的変数の起算日を含めて変化させ、それぞれについて予測精度を比較することで、最適な変数の設定に変更することが考えられる。
3.2 特徴量エンジニアリングの追加
今回は、説明変数について正規化のみ実施した。
ここで、各特徴量を、より適した値に加工することが考えられる。
例えば、次の記事中の(https://toyokeizai.net/articles/-/337682 )p.1の図によると、桜の開花日は、緯度や冬の気温等から算出した「起算日」から、気温から推定した花芽の成長量に相当する「温度変換日数」を足し続け、積算値が一定値(23.8日)に到達した日から予測できるという。この「起算日」や「温度変換日数」に対応するパラメータを今回取得した気象データから算出し、それらを新規に特徴量に加えることが考えられる。
また、各特徴量の分散の程度や多重共線性の有無を確認し予測精度に寄与しない特徴量を削除する、降雪量等の特徴量を対数変換し正規分布に近づける等、統計的な傾向からデータを加工することも考えられる。
3.3 学習モデルの範囲の変更
2.4.4,2.5にて記述したように,降雪量のパラメータが桜の開花日に大きく影響した。
この事は、降雪量の多い地域と降雪量の少ない地域でデータの傾向が異なっていることを示している可能性がある。つまり、「降雪量の多い地域」と「降雪量の少ない地域」で別個に学習モデルを作成することで、よりその地域の気象の傾向に即した精度の高い予測モデルを作成できる可能性がある。
3.4 ハイパーパラメータの最適化
今回は、各アルゴリズムのハイパーパラメータの最適化を実施しなかった。
Optuna等の手法によるハイパーパラメータの最適化を実施することで、予測精度をさらに向上できる。
これらの方策や他の方策によって、さらにモデルの予測精度を向上できると考える。
また、モデルの実用上の観点からは、3月上旬の時点で桜の開花日を予測できることが望ましい。よって、2月下旬までの範囲のデータから予測モデルを構築することも今後の実施事項として考えられる。その際、2.5にて記述したように、3月の気象データは桜の開花への寄与度が高いため、3月分を含んだ予測モデルよりも予測精度が低下することが予想される。その対策としては、2月下旬までの気象データから3月の気象データを予測するモデルを作成し、そのモデルの予測値を特徴量に加えること等が考えられる。
この記事が気に入ったらサポートをしてみませんか?