
スクレイピング 画像保存練習【Python🐍】

こんにちは!
パソコンインストラクター歴12年の
チサです。(*´∀`)
今日は
Python🐍で
画像保存のスクレイピングが
できたので
ヽ(´▽`)/
そのことを書きますね!
ずっーーと
Webページ上の画像を
パソコンに自動保存するのを
やってみたかったんですが
あーだこーだ
あれこれやっても
なかなかうまくできなくて💦
( 。•́ - •̀。)
あれこれ調べているときに
コチラの練習サイトを発見👇
こちらのサイトは
スクレイピング練習用に
準備してくださってるサイトで
ページの構造もシンプルなので
練習にはもってこい♪
なので!
サイトにある
この24枚の画像を👇
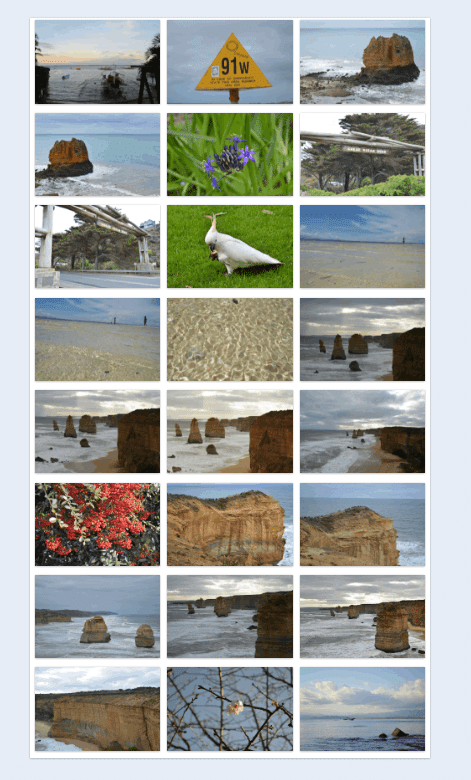
スクレイピングで
自動で取りこんで
こんな感じ保存する👇
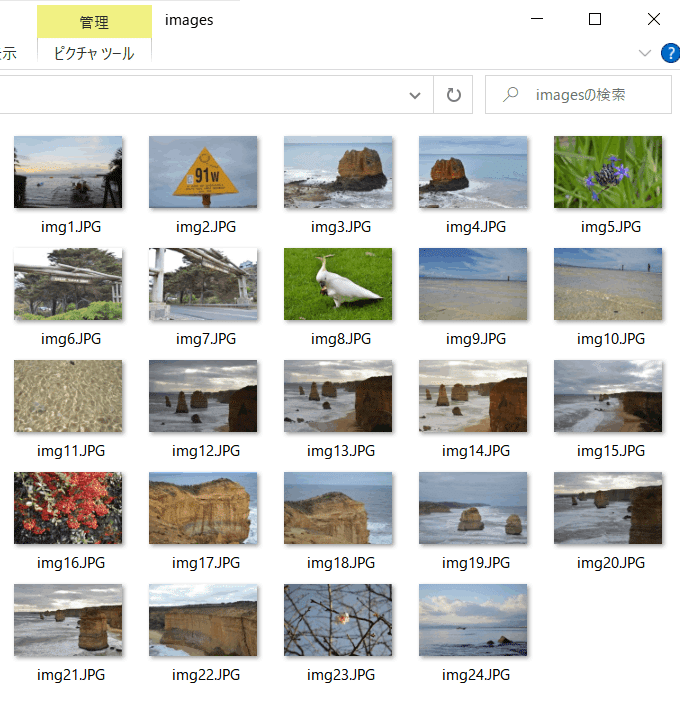
チャレンジしてみることに♪
今回は
デスクトップに用意してる
imageフォルダ📂に
画像を放り込んでもらうことに♪
とはいえ…
それでも
なかなか自力ではむずくて💦
🤔
こちらの動画を参考にしました!
こちらの動画はMacで
説明してるので
保存先フォルダの指定が
ないのですが…
なんとか
Windows用に❓
保存先フォルダも指定できました🎉
書いたのはこんなコード👇
from pathlib import Path
from pathlib import Path
from bs4 import BeautifulSoup
import requests
# 保存先のパス
folder_path = Path.home() / "Desktop" / "images"
# ページのURL
base_url = "https://scraping-for-beginner.herokuapp.com"
# 画像が載っているページのURL
res = requests.get(base_url + "/image")
data = BeautifulSoup(res.content, "html.parser")
if res.status_code != 200:
print(res.status_code)
exit(1)
# imgタグだけ抽出
get_data = data.select("img")
for data in get_data:
img_url = data.attrs["src"]
url = base_url + img_url
get_img = requests.get(url)
if get_img.status_code != 200:
print(res.status_code)
exit(1)
# 画像保存用のファイル名(●●.jpg)をimg_urlから作成
img_list = img_url.split("/")
file_path = folder_path / img_list[-1]
# 画像を保存
file = open(file_path, "wb")
file.write(get_img.content)
file.close()
print("終了")
これでうまく取り込めました!
ヾ(≧∇≦*)/やったー
今度は別のサイトでも
チャレンジしたい!
もうこれは!
練習あるのみ!!
ではでは
またあした!
(´꒳`)/
新刊出版しました👇
Wordショートカット力試しドリル
あなたはショートカットだけで
どこまでやれる?
|д゚)チラ
この📕で修行すれば
マウスのドラッグ操作から解放されますよ✨
ヾ(o´∀`o)ノワァーィ♪
➊パソコンに関する📕 4冊
➋Kindle出版に関する📕 2冊
➌節約に関する📕 1冊
➍読書に関する📕 1冊
➎海外の方向けの📕 3冊
気になる本があれば
試し読みだけでも♪
(´▽`)
この記事が気に入ったらサポートをしてみませんか?