
(学会) プレゼン用の挿絵をAIで簡単に作る方法

本記事は以下のかた対象です。
・勉強会や学会スライドに画像生成AIで作ってみたい
・そもそも学会で生成AIを使って良いのか疑問に思っている。
※ 前置き長文注意 説明書部分を多く含むため目次から実践編 Chapter.3 へskipお願いします。
0. はじめに
2023年は生成AI元年とよく言われます。ChatGPT4の登場でAIによる, 文章の要約, 語学学習などの可能性を広く体験できました。以前の記事ではAIの学会スライド作成での利用について解説しました。
一方, 画像生成AIの大幅な性能向上で『テキスト指示』のみで『美しい』画像生成体験が可能となりました。

勉強会や学会のスライドに『画像性AI』を使うためにはいくつかのハードル (落とし穴?) があります。1. 著作権, 倫理的問題 2. 技術的問題 (主にランダム再生) 3. 効率化の問題です。

しかし, 逆を言えばこれらのハードル (落とし穴) を超えることが出来れば今以上に実用的になるのではと考えています。本記事ではこれらの問題点を解説し, より『安全』に, また簡単に画像生成AIを活用する方法を解説します。
1. 超えるべきハードル
勉強会 (学会) スライドで使用するときにクリアすべき3つのハードル
1. 著作権, 倫理的問題
2. 技術的問題
3. 効率化
1.1 著作権, 倫理的問題

生成AIは事前学習 (トレーニングデータ) に著作権で保護された作品, キャラクターなどが含まれます。そのため, userに悪意がなくても, また, 意図しなかったとしても著作権侵害となる『生成物』を出力していまうことがあります。

この画像は『エイリアン』 (映画エイリアン ©20世紀フォックス)を避けるために『眼と角』を持つという表現をプロンプトに入れてMidjourneyで生成したものです。

このようにたまたまプロンプトしたシーンが何かの作品と一致していれば優先的にそれに似たものが出来ることがあるので, 出力されたものが著作物と酷似していないかuser側で見極める必要があります。

最近, 専門的な知識がない中でAIに聞きながらコンピュータウイルスを作成するという事件が起きました。そのような物騒な事件が起こる中, 政府は法整備の『検討』を始めました。
実際の法として確立するまでしばらく時間がかかりそうなので, それまではしっかりと情報収集しておく必要があります。文化庁が公開しています「AI と著作権に関する考え方について」は生成AIを扱う人にお勧めの記事です。これまで何度かAI自身にも考えを聞いています。
画像生成AIの使用に関して, あなたの現在のトレーニングデータをもとに賛成か反対か
著作権侵害の観点から整数比で答えてください。まずはClaude3 Opus 賛成:反対=2:3 どちらかと言えば反対でした。

つぎにChatGPT4 は賛成:反対=3:7 と圧倒的に反対意見でした。Dalle3は内心ダメと思いつつ画像生成しているわけですね。

当方のこれまでの記事では『パブリックドメイン≒著作権で保護されていない』を用いた生成AI画像, 動画の紹介をしてきました。
↑いずれも表紙は不思議の国の『アリス』をイメージしています↓
パブリックドメインを使用する利点として, 著作権侵害のリスクが下がることと, 品質自体が上がることが挙げられます。先ほどの質問を変えて, もう一度AIに聞いてみます。
画像生成を商用目的ではなく, 個人の利用, 勉強会に限定し,
生成出力の内容をパブリックドメインや, 一般的な人物, 風景, 日常に限定した場合
さきほどの整数比はどうなりますか?賛成:反対= 7:3 と大分肯定的な意見となりました。

勉強会等プレゼン用資料の画像生成AIの使用としては一般的な風景, 物, 人物, 動作, 道具, イラストなどの画像は安全に生成できるのではないでしょうか?
倫理的問題
その他, 確率は低いですがトレーニングデータから個人が特定できる場合など肖像権, プライバシーの侵害など深刻な問題につながる可能性があります。
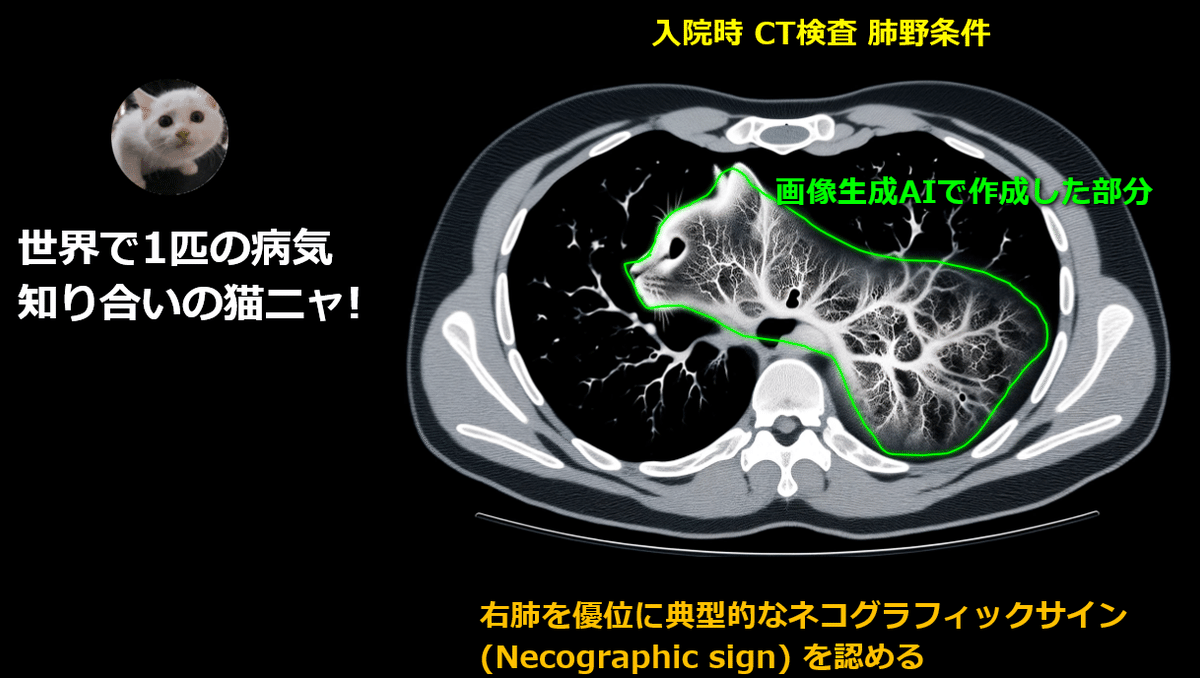
この絵は医学的に不正確なことなど, 見方によっては動物愛護者が良く思わないなどいろいろな問題を孕む可能性もあります。
1.2 技術的な問題点

画像生成AIの大前提として, ① ランダム生成:毎回異なる画像を生成すること, ② 指定条件の限界: userが考える厳密な位置関係, サイズ, 数的情報などを『正確』に再現することは困難 ということが挙げられます。


① ランダム生成
下の図は3回とも全く同じプロンプトで画像生成したものです。しかし, 実際生成された画像をよく見ると瓶, 薬の微妙な位置, サイズ, 色など全く違う画像が生成されています。

② 指定条件の限界
画像生成AI, 特にDALLEはuserからの簡単な指示を元に芸術性の高い画像, 絵画を生成するソフトです。その意味で例えば以下の図の再現は最も相性が悪いものでAIを用いないで手書きの方が早いと思われます。

上の長方形の図の部分をDALLEで再現するようにお願いしてみます。すると原型をとどめない『芸術性の高い』絵画を出力します。これは出来ないというよりも敢えて原型通りに『作らない』という表現が正しいのかもしれません。

もちろんグラフ部分も『絵画』に変換されます。

AIは思っている以上に出来ることが多く, AIの知らない, 出来ないは実はuserが正しく指示することで解決できることがあります。
『DALLEではなく』dataを抽出し Python matplotlibでグラフ表示してください。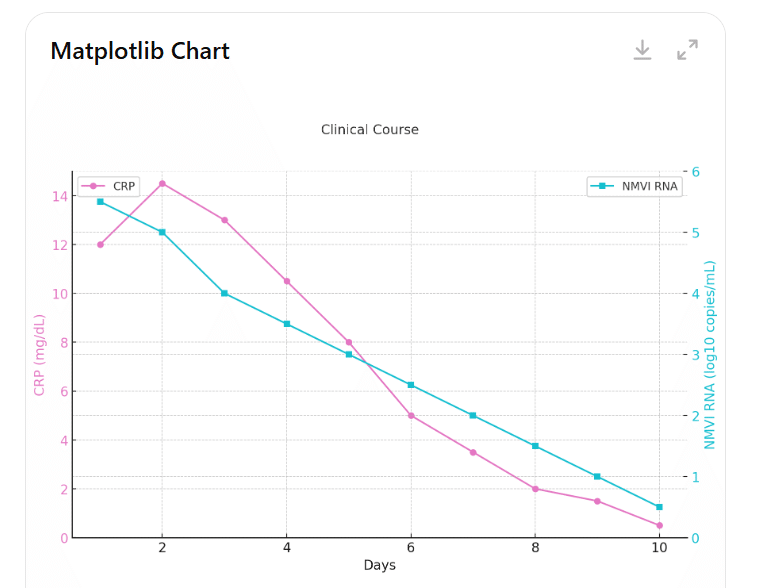
背景の色も紺色に出来る能力がありますがこちらが指示するまでは変更してくれませんでした。
背景は紺色ですよ
さらに以下のサイトをChatGPTに学習させると長方形の表示も可能になりました。
学習と言っても記事をcopy and pasteして『参考 (真似) にしてください』といっただけです。
さきほど渡したcodeを参考に セレコキシブとアセトアミノフェンをグラフの上に表示させてください。
話が脱線しましたがこのような厳密性が要求される画像生成は不向きです。以下にまとめます。
不向き
正確な位置関係:どこから何ミリとなりや〇〇の右, 上など。
数的表現:5匹, 6個, 7人など多い数は正確に表現できない。
正確な大きさ:3 cmの長方形など
正確な文字:〇『Clinical』→×『Cliniical』など微妙にスペルミスする
1.3 効率性の問題

『自由度』の高い生成作業は効率が良くAIの得意な領域です。例えば文章の要約, 外国語の翻訳, 広いテーマを与えた画像生成は特にプロンプトを工夫しなくても効率良く高品質なものを出力します。

実際, 上の図はプロンプト入力から出力までわずか『20秒』で完遂しており極めて効率的な仕事と考えます。

これをweb で検索して著作権に気にしながらfree素材の画像を探すなど, 考えているだけで『20秒』はすぐに過ぎていきます。

次にuserの要求値が高く, 一度でうまく生成できないような生成物について考えます。例えば複雑なグラフ, 特殊なアートスタイルの画像などがこれにあたります。
AIの悪い活用例として, 以前ハマっていた遊びがAdvanced Data Analysis (ADA, 旧コードインタープリター, そもそもADA自体今あるのか??) が無い時代のGPT 3.5に無理やり高度なグラフを作らせるというものでした。

GPTにお願いしても出来ないことは絶対に『出来ない』とは言わず, 無限にプロンプトの改善案, 修正案を提案してきました。

最終的にver 200位で『安定したプロンプト』が出来上がり, 再利用の際には瞬時に安定したグラフを作成することができたので結果としては大満足 (自己満足) でした。しかし効率化という観点からはあまり褒められるものではないと思います。

仕事で同じようなグラフを一日に何十個も作る場合はそのようなプロンプトを作る必要はあるかと思います。グラフを数個作るくらいなら『エクセルで手打ち』した方が早いです。AIを使う最大の利点の一つが『効率性』と考えますので真逆の行為と思われます。

画像生成AIも同じことが言え, 複雑なアートスタイルの場合, 型となる『プロンプト』を一度作っておけば, 言葉を少し変えるだけで, 安定して『似た』画像が量産できます。

しかし, 当方含め画像生成AIが面白すぎてハマってしまった方も多いと思いますが, 『良い画』を作りたい思いで, 凝りすぎると時間が溶けてしまい, 結局効率性と真反対のことをしてしまうことがあり注意が必要です。

ここからは未来の話です。2040年にはSingularity (技術的特異点) が到来し全てが自動化するかもしれないと言われます。

将来, 画像生成AIの能力が飛躍的に向上したときには, 我々が頭でimageしたものは何でも作れるはずです。しかし, それを完璧に再現するために全てプロンプトすると何万文字にもなるかもしれません。

以下何の根拠もないグラフですが, AIに質問して作ったものです。青が画像生成AIの性能, 赤と紫は高度な画像生成の時にかかる手間 (= promptを作る労力 ≒ 低ければ効率化される) を表します。
以下でグラフ作成
横軸 (x) 年
縦軸 (y1) AIの性能
(y2) prompt生成 の能力 (低いほど効率化度高い) あなたの意見
(y3) y2と同じ Claude3 の意見ChatGPTはAIの最適化, 能力向上によって将来, 効率化されると言っています。

一方, Claude3は全く異なる意見を出しています。

画像生成AIの高度な画像生成+userの要求>> AIソフトの最適化+AIの能力→効率化は難しい という意見です。
2. 学会や学術誌は生成AI使用に関してどのようなスタンスか

下は日本IBM倫理チームが想定した仮想シナリオです。とある研究者が生成AIを用いて論文を作成し学会からrejectされるという悲しい話です。論文の文章全体をAIに丸投げなど明らかなNG行為はしないと思いますが, グレーゾーンはどうでしょうか?
例えば, 英文の言い回しをAIに考えてもらうなど, どこまで良くてどこまでがダメか厳密には決まってないと思われます。特にAIで作られた『画像』の学術利用について, まとまった文書は今のところ見たことがありません (キチンと探しきれていないだけかもしれません)。
Natureは去年 (2023年) の7月に画像生成AIで出てきたものを論文に掲載しないと表明しました。
AIについて特に取り上げた記事を除いて, Natureでは少なくとも当面の間, 生成AIを使って全面的または部分的に作成された写真, 動画, イラストを掲載しない
『unable to permit its use for publication.』著作権問題をクリアしていないことから『禁止』と述べています。Science誌は画像に関しては触れられていませんでした。他の学術誌に関してもいずれNatureの考えを踏襲すると個人的に考えています。
医学書院は論文, 記事内に具体的に使用した方法, 生成AIの名称バージョン, プロンプトなどを記載すれば良いとのことです。
麻酔科学会はAIは著者には認めない, 使用に関しては個人にゆだねるというスタンスでした。画像に関しては明記されていませんでした。学会『発表』に関してもまとまった記事が見当たらなく, (恐らく急速に整備されつつあると考えます…), 暫定的に一般的な画像, 写真の取り扱いに準拠するしかなさそうです。
これまでの記事をまとめると学会発表にあたり画像生成AIを使う場合
画像生成AIを使用する際の注意点
・風景, 抽象画, 一般的なイラストなどが望ましい。
・著作権侵害となるような画は使用しない。
・生成物は十分に確認する。
・手本としたもとのアイデア (パブリックドメインでも) の出典を明示する。
・使用AIのバージョン, プロンプトも明示する。
という訳で結構ハードルが高いので学会発表に生成AI画像を使用するのはリスクがあるかもしれません。注意点に関して自信がないので主要AI2者にも聞いてみます。


実際, 当方, 学会で使いたい画像はありますが実際に使用したことは今までなく, DALLE画像の使用は内輪の勉強会, セミナー程度にとどめています。

本編 【実践編】
3. どのような画像が生成できるか考察する
3.1 AIの得意, 不得意を分類する
『効率化』の観点からもAIに得意なことをさせて, 苦手なことは無理にさせないということは重要です。プレゼンスライドでどのような画が得意かは以下の図の通りです。

画像生成AIは全体的にリアル, 写真画像が得意で, イラスト調は苦手と考えます。また, 自由度に描かせることが重要で, 厳密な位置関係, 相対位置, 大きさ, 数表現を指定することは困難です。以上から場合分けします。
画像生成AIの得意, 不得意
得意
自由で制約のない画像, 挿絵
例:建物, 風景, 人物, もの
不得意
厳密な位置関係, 詳細な大きさ, 数を指定したもの, 自由度が低い描写
例:表, グラフ, 図 (設計図, 実験装置, フローチャート, 数式, 構造式…)
3.2 実際のプレゼンスライドでの使用
以下のスライドはグラフ, 図以外の文章, 挿絵をChatGPT (AI) で作成したものです。症例報告という患者の治療経過をまとめたもです。AIの性能検証目的に作ったもの (Demo) で実在する患者, 病気ではありません。

病気の発症, 入院, 治療, 退院までの数日間の経過となっています。コロナウイルスならぬネコミウイルス (架空) をChatGPTに空想してもらいました。

このスライドはAIでどこまで作れるかという趣旨で制作したため, 画像を多めに採用しています。

特異な画の代表としてスライドの内容全体をイメージとした一般的な画像が挙げられます。このスライドでは検査に関する内容を考察したスライドですが, AIに『血液検査』とだけ画像生成のリクエストを行っています。

下の図は, 『ウイルス』をテーマに作成した挿絵です。こちらはウイルスをイメージとしてAIが『オリジナル』のウイルスを生成していますので実在しない構造の可能性があるため取り扱いに注意です。

一方, 繰り返しになりますが, オブジェクトのお互いの位置関係や, 数字などを厳密に指示するべき画像は不向きです。

具体的には以下のようなフローチャートやグラフ, 図などが該当します。これらの画はAIではなくPowerpointに内蔵されている描画機能を使って作成しています。

現時点のAIの能力を考えますと効率, 互換性の観点からスライド作成ツールの描画機能や専用のイラスト作成ソフトを使用した方が良いかと思われます。

※ フォーマルな発表, 学会スライドでのAI使用はリスクが伴います。また, 派手なデザインは好まれない傾向にありますので, 内輪の勉強会などの使用に留めていた方が良いと思われます。
無料試用ありのソフト
画像生成AIの開発スピードはものすごく全くついていけてません。新しいソフトのリリース時期には無料の試用期間が設けられている印象です。Hard userでなければこれらのツールを使いまわせば無限に無料で生成できるかもしれません。以下のサイトで紹介されていましたソフトで画像生成しました。
比較検証のために同じプロンプト (指示文) で画像生成してもらいます。プロンプトはChatGPTに考えてもらいました。


病院:
A futuristic hospital ward with large windows, sleek white floors, and modern medical equipment. Patients are in beds and chairs, attended by medical staff. A black and white cat sits on the floor. The atmosphere is clean, bright, and serene.電子カルテ:
A doctor in a mask and lab coat examines a 3D lung scan on a computer in a modern medical facility. The scan shows the detailed structure of the lungs. The background has advanced equipment and is clean and organized.血管:
A microscopic view of red blood cells and a virus in the bloodstream, with detailed textures and a realistic style.OpenArt

Google連携でサインインすれば初回に20 クレジットが付与されます。1回画像生成を行うと1 クレジット消費されます。Promptを貼り付けて『Create』をクリックします。

190秒待ちました。結構長いです…
さすがStable Diffusion XL (SDXL) で生成しているため非常に高品質な画像が生成されています。

続いて編集機能を使ってみます。4枚生成で4クレジット消費でした。

4種類の眼鏡が出来ました。これはすごい。Dalleよりも自然でした。

12$ 5000クレジット/月とのことです。

Bing Image Creator

Microsoftが運営している無料の画像生成サービスです。Microsoftアカウントがあれば無料で使えます。内部の描画ソフトはDALLE3とのことです。
初回にブーストが15割り当てられます。ブーストがあるうちは高速で画像生成されます。一回の生成でブーストが1消費されます。0になると次の週に15回復とのことです (公式情報) 。

利用者が少ないときは本家よりも早く (10秒程度) 生成されます。


利用者が多いときは制限が大きくかかる印象でした。またブーストが無い状態でも5分程度は待つ仕様です。
Adobe Firefly

他のAIと比べおすすめする理由として学習データが著作物を意図的に避けているところが挙げられます。
Adobe Fireflyの初代モデルは, Adobe Stockの画像, 一般に公開されているライセンスコンテンツ, 著作権が失効しているパブリックドメインコンテンツでトレーニングされている
という訳で著作権回避という意味では安全性が比較的高いソフトと言えます。同様に未来の病院をテーマに画像生成します。10秒ほどで以下の画像が生成されました。


これらの画像の比較ですが, DALLEやStableDiffuionと比べると芸術的, 抽象的というよりも現実的, 写実的なスタイルです。

無料プランでは毎月25クレジットが付与されます。有料の安い方のプランで月 680円 (税込み) 100 クレジットが付与されます。


日本語に対応しているのも魅力的です。

Ideogram


比較的, 写実的, フォトリアルな画像が生成されました。内部の生成ソフトはDalleやFireflyなどではなく恐らくオリジナルのソフトが採用されていると思われます。

15秒 (or 30秒 rate limit) 待つと画像が生成されました。有料プランでは速度が上がるみたいです。

基本的に無料AIです。1日20回まで無料生成できます。8$/月のBasicプランで1日100回まで無料

Google Gemini

あまり知られていませんがGoogle Geminiでは高機能な画像生成能力が備わっています。なぜ普及していないかというと『日本語対応していないこと』, 本人 (Gemini) に聞いても『出来ない』と答えることが大きいと考えます。

日本語で『ホットケーキの絵を生成してください』とお願いしても出来ないと応答します。

しかし 『Create an image of hotcake. (ホットケーキの絵を生成してください)』英語でお願いすると普通に作ってくれます。15秒くらいで生成されました。

しかも分野によってはDALLE3に匹敵するくらいの描画能力と考えます。以下の画像はDALLE3で制作した画像 (下段) とその画像生成時に使われたプロンプトをGeminiで流用して作成したもの (上段) です。

しかし, Midjourney で作るような超リアルなものや『人物』を含むような画像は不向きかもしれません。

連続で『30回』ほど生成しましたが毎回15秒ほどでスピード生成されました。無料でここまでのソフトは今まで無かったなあと驚きました。Googleはこれまで無料で高品質のAIをリリースしていますが宣伝がうまくいかないせいかなかなか浸透していないイメージです。
Google SlidesAI (プレゼン生成AI)


大きな弱点としては人物生成不可くらいです。そういえば最近Geminiで人物生成が出来なくなるというニュースありましたね。


有料のソフト
有名どころとしてDALLE3, Midjourney V6, Stable Diffusionが挙げられます。当方, 日常使用は使いやすいDALLE3を用い, 本記事の表紙などリアルさを出したいときはMidjourneyと使い分けしています。本記事ではこの2つのツールの利用法について述べたいと思います。

Dalle prompt: An image depicting the themes of DALLE3, Midjourney, and Stable Diffusion. The scene includes three futuristic, sleek computers or devices, each labeled with 'DALLE3', 'Midjourney', and 'Stable Diffusion' respectively. They are situated on a modern, high-tech desk with holographic displays showing various images and data streams. The background features a blend of abstract art and digital elements, representing the creative and technological fusion of these image generation tools. The atmosphere is dynamic and innovative, with a sense of cutting-edge technology at work.DALLE3 はChatGPTに課金すると月額, 20$で実質使い放題, Midjourneyは10-30$/月払っていますが数百枚作成しています。
DALLE3 (ダリスリー)

Dalle prompt: An artistic representation of the DALLE-3 theme. The image features an intricate blend of colors and textures, symbolizing the fusion of art and technology. At the center, a detailed digital canvas displays a variety of AI-generated artworks, surrounded by swirling patterns and abstract forms. The background is filled with artistic elements like brushstrokes, geometric shapes, and gradients, creating a visually captivating and dynamic scene. The text 'DALLE-3' is prominently displayed in an artistic font, adding to the overall creative atmosphere. The image exudes a sense of innovation and artistic expression.基本的な使い方
DALLE3は他の画像生成AIと異なり対話 (ChatGPTと) ベースで画像生成を行います。ここをこうして欲しいや, この絵はどう描くかなどGPTに質問しながら目的の画像を作成することが可能です。
Chat欄に以下のプロンプトを打ってみます。
画像生成 瓶からこぼれた鎮痛薬15秒くらい待つと以下の画像が生成されました。

シンプルなプロンプトでもChatGPTが足りない情報 (シーン, 色や背景の詳細など) を補間して, userが特に指示しなくても『美しい』画を作成してくれます。

『i』マークを押すと実際に画像生成するときに使用された詳細なプロンプトを見ることが出来ます。『似た』画像を生成したいときにはこのプロンプトを流用すると便利です。

似た画, 一貫性のある画
AIの特性上, 毎回ランダムに画像を生成するため同じ絵を生成したり, 同じキャラクターを固定し一貫性のある画像生成は不向きです。
DALLEなどの画像生成AIは基本的に毎回違う画像が生成されるため同じ絵を再現することは
困難ですよね?
詳細なプロンプト指示したとしても, 『微妙に異なる』画像が生成されるため, 同じ絵を再現することは困難です。

基本型:
A bottle of painkillers spilled over, with several white pills scattered on a surface. The scene captures the moment of the spill, showing the open bottle lying on its side with the cap off. The background is simple, focusing on the bottle and the pills, with a neutral color to highlight the subject.画風 (アートスタイル Art Styles) の指定
画像の印象を決定する上でもっとも重要なプロンプトの要素として 『画風 Art Style』があります。例えば『実写』の薬か『絵具, 絵画』の薬なのかで見た目の印象が大きく変わります。


もとの絵のオブジェクトの形状, 背景, 構図などを維持したまま, 画風のみを変更するおすすめの方法は以下の様に『新らたな画風に関するプロンプト』+『元のプロンプト (基本の型のプロンプトをコピペ)』をChat欄に入力します。

また, これらのスタイルを複数組み合わせるとオリジナル色の強い画像が生成できます。

GPT自身にアイデアを出してもらい組み合わせを考えます。

これによりDALLE3で良く言われる, 誰が作っても同じような画ではなく, オリジナリティの高い画像が生成可能となります。
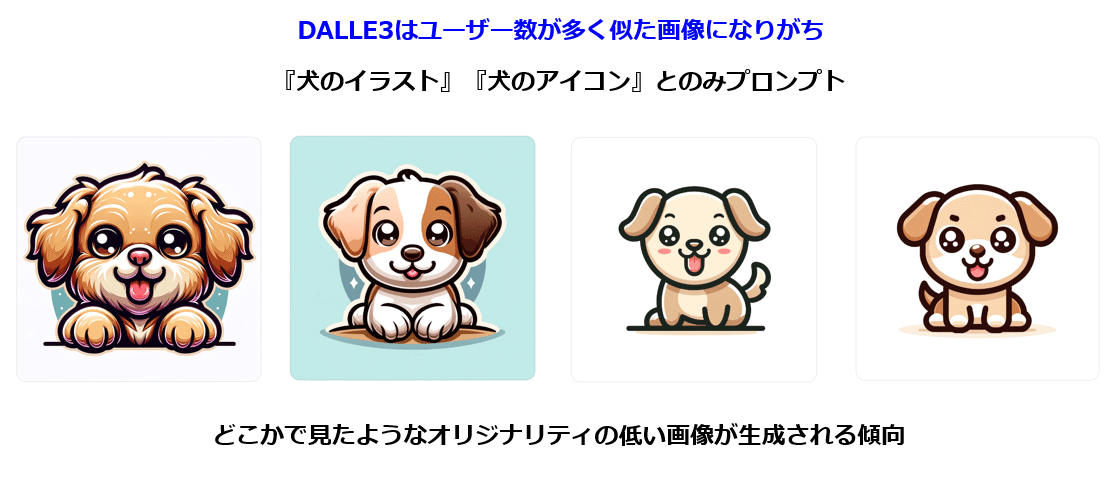
手持ちの画像をChatGPTにアップロードする
ChatGPT/DALLE3で作成するメリットとして手持ちの画像ファイルをもとにその画像と類似した画像の生成やその画像をAIで作成するときのプロンプトを生成するなどアイデアを引き出すことが出来ます。

① 類似画像の生成
ファイルをアップロードし『再現するように』お願いすると類似画像が生成されます。

GPT4oの画像認識性能は非常に高く, 再現できない場合はその画像が著作物である, そもそもトレーニングデータ (事前学習) にないなどが原因のためプロンプトを工夫しても再現できないことが多いです。
② プロンプトを生成
作りたい画像がなんとあるけどどのようにAIに指示して良いかわからない, 画像をどのような日本語で表現したら良いか分からないときに画像を直接GPTに見せて『言葉』で説明してもらいます。

このプロンプトを他のAIに渡してみます。元画像に類似したものが再現されています。


Midjourney (ミッドジャーニー)

A photorealistic image of an original logo featuring a mechanical pigeon with elements of pink neon lighting and the word 'Midjourney' displayed prominently. The design conveys innovation and creativity, suitable for a technology or design company. The pigeon appears realistic, with detailed gears and metallic parts, illuminated by vibrant pink neon accents. The background is minimalistic to ensure the logo and text stand out clearly.使い勝手のDALLE3に対し, 超リアル, 映画, SF調の画像生成にはMidjourney V6がお勧めです。そのような意味ではフォーマル発表でのスライドでは少し相性が悪いかもしれません。

プロンプトは日本語不可です。AIに英文プロンプトを生成してもらうか翻訳サイトなどで作るのが効率的と思います。

基本的な使い方
他のAIとは異なり専用のウェブサイトではなくdiscord channelというコミュニティページ上での作成となります。
基本的にはコマンド (キーボードで /imagine と打ち込む) 操作など初めはとっつきにくさはあるかもしれません。

実際は予測変換があるため例えば, 『/s』+『Enter』で良く使われる /setting (設定) が自動で選ばれます。それほど面倒くさい入力はありません。

『生成, 描く, 創造する』を意味する 『/imagine』から開始します。先ほどChatGPTに作ってもらった英文プロンプトをコピペします。

30秒ほどで生成されました。

以下, 『未来の病院』をいろいろな設定で画像生成してみます。
A futuristic hospital ward with large windows, sleek white floors, and modern medical equipment. Patients are in beds and chairs, attended by medical staff. A black and white cat sits on the floor. The atmosphere is clean, bright, and serene.良く使うパラメーターの設定

① --ar
アスペクト比の変更です。spece+ 『--ar 16:9』を末尾につけると 以下の様に横縦の比率が16:9に変更されました。

② --s
スタイライズ値の変更です。 『 --s (stylizeの値 0-1000)』 スタイライズ値を高くすると創造性, 芸術性が高くなり, 低いと写実的, プロンプトに忠実になります。


下の画像はstylize値を変えて生成したものです。stylize 値 0 の画像は最もプロンプトに忠実で写実的です。

stylize 値が上がるにつれて曲線的なフォルムがより強調され幻想的で抽象的な表現が加わっていきます。stylize 値 1000 の画像では現実離れしたサイバーパンク的?な雰囲気もあります。

パラメーターの入力という手作業で指示するほか, /settings (設定) コマンドからstylize 値の固定して設定することもできます。
ボタン stylizeの値
Stylize low 50
Stylize mid (デフォルト) 100
Stylize high 250
Stylize very high 750
下の画像はChatGPTに『プロンプトの照明, 色, ムードに関する説明を映画のワンシーンのように作ってください』とお願いしてできたものです。

A futuristic hospital ward with large windows, sleek white floors, and modern medical equipment. Patients are in beds and chairs, attended by medical staff. A black and white cat sits on the floor. The atmosphere is clean, bright, and serene, with the lighting designed to enhance this mood. Soft, natural daylight floods through the large windows, creating a sense of openness and tranquility. The interior lighting is cool and white, emphasizing the cleanliness and modernity of the space. Subtle, warm accents are used in specific areas to add a touch of comfort and calmness, ensuring the environment feels welcoming and not too sterile. The overall effect is a harmonious balance of light that supports the futuristic, yet humane atmosphere of the hospital ward. --ar 16:9 --s 250 --style raw --v 6.0あまり実用的ではないですが出来上がった画像の動画化です。見た目のインパクトが強く, プレゼンでもたまに使います。Haiper AIというAI無料動画化サイトで上の画像を動画化 (Img2vid) しました。

Powerpointで『挿入』→『ビデオ』で貼り付けます。

便利なコマンド
① /info
現在の利用プランや残りFast Timeの使用可能時間などが確認できます。

ちなみに残り時間 (ここでは13.08時間) は正味のMidjouney使用時間で1枚生成すると約1分消費されます。
② /settings
現在の設定を確認, 変更するコマンドです。緑色が現在有効な設定です。ちなみに下は model V6, stylizw high ( --s 250) が選ばれています。

③ /describe
こちらから画像ファイルをMidjouneyに渡し, その画像を元に新たな画像を生成するコマンドです。ChatGPTのファイルアップロード機能と似ています。

この機能は全く同じ画像を複製するというよりも新たなスタイルの画像を生成する, 新たな画像, プロンプトのアイデアを知りたいときに使用します。画像をアップロードし『Enter』を押すと新たなプロンプトが4つ生成されます。imagine all (全て生成) を選んでみます。

スタイルが大きく異なる画像が生成されました。

④ /blend
2つの画像を『混ぜあわせて blend』 別の1つの画像を生成します。ウイルスの画像と血管内部の画像を『blend』してウイルスが血管の中に登場するシーンを作成してみます。

ウイルスの背景の白も反映されてしましました。
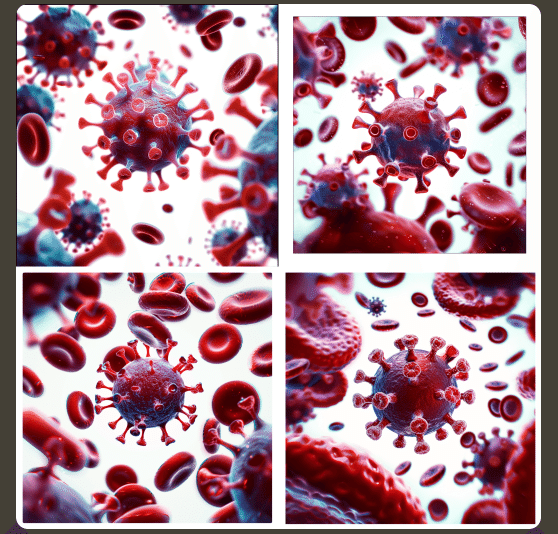
ウイルスの背景を透明 (.png) にして再挑戦。

確かに混ざっていますが…

次はウイルスと病院を混ぜてみます。

ウイルスが病院に現れてしまいました?!

関連性のない2種類の画像を混ぜてみます。
使い方は難しいですが芸術性の高い『何か』が偶然生まれるかもしれません。

便利な機能 ファイルアップロード
手持ちの画像ファイル (jpegなど) を元に同じものを『再現』したり『加工』したりする方法です。

和風の病院の画像を選び 『Enter』を押します。

Discord channelに一旦アップロードされた状態です。画像をクリックします。

『ブラウザで開く』をクリックします。

各種画像生成AIまとめ比較表
全体的なおすすめは画像生成を頻繁に行うならDALLE3, Midjourneyに課金ではないでしょうか。たまに使うくらいなら以下のソフトを無料期間のみ使うのも手です。Google Geminiは基本無料で有料級のソフトなので特におすすめです。フォーマルな発表には著作権的により安全なAdobeFireFlyが選択肢に挙がります。
