採用担当のKaggle挑戦④

4週目の挑戦
Bike Sharing demandの再挑戦したい。再挑戦というよりは、優秀なプログラマーのコードを参考にして順位を上げていきたい。そこで見つけたのがHyperparameter Tuningである。
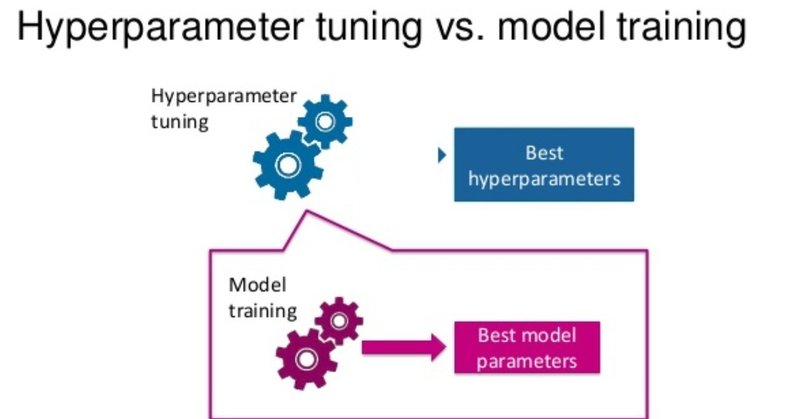
Hyperparameter Tuning
マシンラーニングモデルには多くのオプションがあるが、このオプションを通じてモデルの性能を上げることができる。このオプションを専門用語で「Hyperparameter」(以下'Hp')と表現する。
例え、適度な'Hp'を探し、モデルに適用することが可能であれば、モデルの性能を上げることができる。これをHyperparameter Tuningと言う。Hyperparameter Tuningは大きく二つの方法がある。1)Grid Searchと2)Coarse & Finer Searchと言う方法がある。
1)Grid Search
Grid Searchとはいくつかの'Hp'を候補として定めた後、これらを何度も組み合わせながら一番良い'Hp'を探す方法です。一般的にCross Validation点数が高いのを一番良い'Hp'と言う。
from sklearn.ensemble improt RandomForestRegressor
from skleran.model_selection import cross_val_score
#n_estimatorsはツリーの個数
#一般的に個数が高いほど良いが、その分時間がかかる
n_estimators = 300
max_depth_list = [10, 20, 30, 40, 50, 60, 70, 80, 90]
max_features_list = [0.1, 0.3, 0.5, 0.7, 0.9]
hyperparameters_list = []
2)Coarse & Finer Search
Grid Searchは非常に良い方法ではあるが、一つ大きな弱点がある。それはGrid Searchだけでは一番良い'Hp'を探すことができない。
例え、Bike Sharing Demand問題で一番良いmax_depthが83の場合、以上のGrid Searchでは探すことはできない。何故かと言うとmax_depthの候補を以下のように指定してる。
#ここではmax_depthが84の場合がない
max_depth_list = max_depth_list = [10, 20, 30, 40, 50, 60, 70, 80, 90]
そのため、Grid Searchでは一番良い'Hp'に近い一つの'Hp'を探すことはできるが、一番良い'Hp'を探すことが難しい。
それではどうすれば、一番良い'Hp'を探せるか。理論上存在可能な全ての'Hp'の範囲内でランダムに探してCross Validaitionすればよい。これがRandom Searchである。しかし、Random Searchは現実出来に時間がかかるため、Random Searchを応用した他のhyperparamaterのtuning方法を使用する。それが、Coarse & Finer Search。
Coarse & Finer Searchは大きく1)Coarse Search 2)Finer Searchで動く。
先ず、Coarse SearchではRandom Searchをするが、理論上存在可能なすべての'Hp'の範囲を入れる。その後、良くない'Hp'を整列させ、順位を決める。このように順位を決めて良くない'Hp'を捨てた後、もう一度Random SearchすることがFiner Search。そして、一番良い'Hp'を探したのであれば、Random Forestで学習させる。
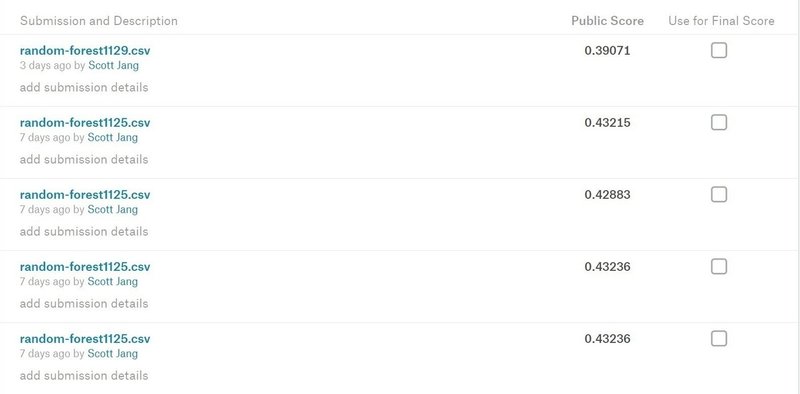
結果は見事に0.39!これくらいだと恐らく上位10%の中に入る点数だ!
4週間の振り返り
振り返ってみると確かにデータ解析?分析?に興味が沸いてきた。しかし、まだ自分のアイディアをコードに全て落とすことができない。
今まで問題を解決する方法は
➀自分で考えてみる→➁優秀なプログラマーのノートやコードを見る→➂マネしてコードを書く→④結果を振り返る
の順番でやってきたが、自分のアイディアを十分に生かしていない。理由としては3点ある。1)Pythonの基礎が足りない、2)圧倒的コードを書く時間が足りない、3)周りにプログラミング仲間(先生)がいない。以上の3点を踏まえて今後の目標を決めていきたい。
次の目標
次の目標はもう少し難しいKaggle大会に出てみたい(まだ挑戦していない:自然言語処理、画像処理など)。そのためには1)PythonとPandasに慣れる必要がある。また、自分の仕事においてデータを選択し、任意の問題リストを作成してPandasで問題を解いてみたい。特にここで使用するデータ(採用関連)はとしたい。とにかくこの2つを12月末まで繰り返いしてやってみたい。
2)毎日30分~1時間のコードを書く時間を確保したい。一般のエンジニアの皆さんに比べればはるかに少ない時間ではあるが、現在採用の仕事と並行してやるための現実的な時間だと思う。
3)良い先生を探したい。先生というのは自分より年上ではなく、プログラミングの先輩である。それは社内のエンジニアでも良いし、社外の知り合いでも良い。少なくとも課題にぶつかった時に相談でき、プログラミングに関して議論できる先生を探したい。
来年には少しレベルを上げて実際企業が開催している大会に参加し、知見を広げてみたい。
この記事が気に入ったらサポートをしてみませんか?