
【ローカルLLM】大量のSDプロンプトデータをRAGとして利用してみる【AI画像プロンプト】

はじめに
ローカルLLMの精度や性能を上げるやり方の一つにRAG(Retrieval-Augmented Generation)というものがあります。書籍や資料、データベースなどを参照しながら指示に対する回答を生成します。
この記事では、画像生成のプロンプトを作成するためのRAG用データとして、大量のSDプロンプト例を利用した場合にどうなるかを試してみます。
ローカルLLMを動作させるために(ollama)Open WebUIを利用しています。
WindowsでのインストールやRAGの設定を含む使い方の詳細は下記にて紹介しています。初めてローカルパソコンでLLMを利用する方向けの記事です。
データの用意
まずは、大量のStable Diffusionプロンプトを用意します。Gustavosta氏がlexica.artで公開されている画像から取得したものだそうです。この8万にも及ぶプロンプトのデータをRAG実験データとして利用します。
「Files and version」から「train.parquet」を入手します。
次にビッグデータ用のフォーマットparquetから、一般的なCSVテキストフォーマットに変換します。変換にはPythonライブラリを利用します。
ライブラリの導入が必要なので、既存の環境を壊したくない方はPython仮想環境を作成してください。詳細は下記で説明しています。
ここでは「conda create -n "parquet-convert" python=3.11」として作成した仮想環境で作業します。Windows/Linux とも同じです。
まずは必要なライブラリをインストールします。
pip install pandas pyarrow fastparquetPython言語での変換スクリプトは次になります。
# ファイル名:go.py
import pandas as pd
df = pd.read_parquet('train.parquet')
df.to_csv('sd-prompts.csv')「python go.py」として実行します。成功すればsd-prompts.csvというファイルが作成されます。大量のテキストデータなので開く時は注意が必要ですが、通常のCSVテキストファイルです。
RAGデータとして Open WebUI に登録する
20MB程度の大テキストデータになりますので、Open WebUIへ登録する際は「/data/docs」にDocker Desktop経由でコピーした方が良いと思います。詳細は下記にまとめています。
利用するモデルは記事と同じ設定です。チャンクパラメータは1000/100です。

スキャンを押すと、/data/docsに保存したデータの解析(Embedding)を始めます。それなりに時間が必要でした。筆者の環境では20分程度でした。
画像用プロンプト生成テスト①
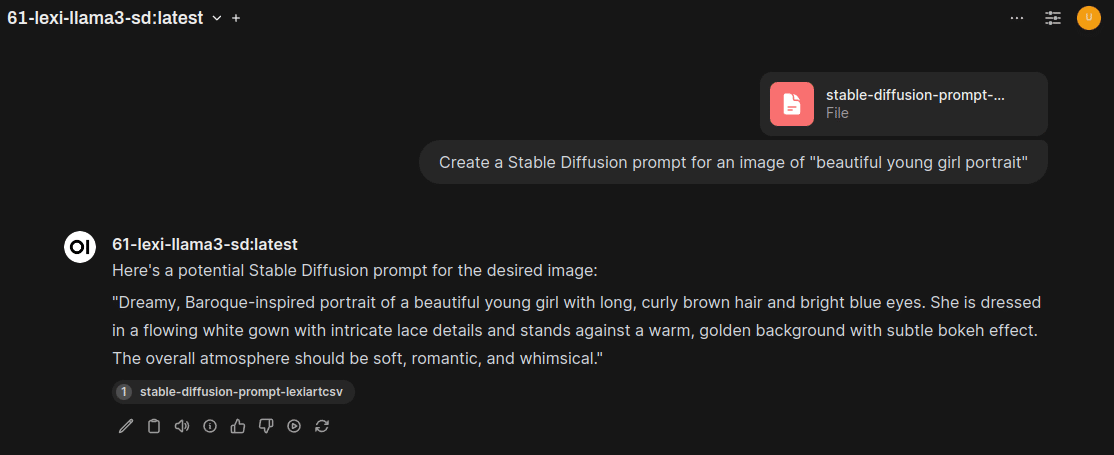
このRAGデータを利用してプロンプトを生成してみます。「Create a Stable Diffusion prompt for an image of "beautiful young girl portrait"」の指示で作成します。このプロンプトでヒットしたRAGデータは次になります。
引用文
ソース
stable-diffusion-prompt-lexiartcsv
コンテンツ
1326,rick and morty baroque oil painting rick sanchez from illustration concept art key visual portrait bokeh trending pixiv fanbox by makoto shinkai takashi takeuchi studio ghibli 1327,"professional digital art of a hyper realistic and highly detailed beautiful woman in a beautiful complex and sexy golden armor. girl's face is hyper realistic, symetric, and highly detailed. head and shoulders view. background is an ancient temple, knights of zodiac style. greg rutkowski, zabrocki, karlkka, jayison devadas, intricate, trending on artstation, 8 k, unreal engine 5" 1328,"A cute little girl with shoulder length curly brown hair with a happy expression wearing a summer dress dancing with fireflies, she is in the distance. beautiful fantasy art by By Artgerm and Greg Rutkowski and Alphonse Mucha, trending on artstation."
※ 画像生成はSDXLのカスタムモデルです。2枚生成して良い方を選んでいます。
Alibaba Qwen2モデル


llama3脱獄モデル
下記で紹介の脱獄モデルです。

Google Gemma2


画像用プロンプト生成テスト②
次に、もっと複雑なプロンプトを指示します。「A highly detailed, absurdly surreal image of a transparent, translucent white plastic-faced robot with smooth, flowing features. Subtle indications of complex technology are interwoven throughout its form. It possesses distinctly male features and stands full-body, observing a spinning lathe in a bustling, industrial factory. The scene is bathed in a soft, warm light, highlighting the robot's intricate details and casting long shadows」を元にします。
トップにヒットしたRAGデータです。
69922,"the singular horseman of the apocalypse is riding a strong big black stallion, horse is up on its hind legs, the strong male rider is carrying the scales of justice, beautiful artwork by artgerm and rutkowski, breathtaking, beautifully lit, dramatic" 69923,"Radiohead Kid A album cover by Jhonen Vasquez and Basquiat and Hieronymous Bosch and Edward Gorey, and Hokusai, trending on artstation, highly detailed,8k" 69924,"a wlop 3 d render of a vampire fighting a werewolf in front of a giant clock face, intricate, extremely detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration, intimidating lighting, incredible art" 69925,"a beautiful painting of a crowned robot princess in a flowing gown, intricate, elegant, highly detailed, digital painting, artstation, concept art, by krenz cushart and artem demura and william adolph bouguereau and alphonse mucha"
Alibaba Qwen2


llama3脱獄モデル


Google Gemma2


まとめ
確かに生成されるプロンプトがRAGデータに影響される事は間違いないのですが、LLMの元々の画像プロンプト生成能力が優秀なので、それほどRAG利用の大きな利点はないように感じました。
A1111 Stable Diffusion webUIの機能拡張には、プロンプトから単語をランダムで選ぶものがあります。過去のデータから単に(文脈によらないランダムな)アイデアや多様性を求める場合は、そちらの方が簡単です。
もしくはLLM側のTemperatureを上げる、チャンクサイズをもっと小さくする等でパラメータを調整していけば、さらに面白い結果を得られるかもしれません。
この記事が気に入ったらサポートをしてみませんか?