
ChatGPTの対抗馬!Meta発表のオープンソースLLM「Llama 2」をGoogle Colabで超簡単に動かす方法

Llama 2の利用申請を出す
Meta AIのLlama2の公式ページにアクセスします
Download the modelボタンを押すと、Llama2の申請ページに飛びます。
名前・Eメール・国・所属組織名を記入して利用規約に同意して続けます。
※ Hugging Faceのアカウントを持っている方は、同じメールアドレスを登録するようにしてください。

すると登録したメールアドレス宛にMetaから利用可能になりましたとの旨のメールが届きます。私の場合は数分かからず届きました。
Hugging Faceでの準備
Hugging Faceアカウント作成
Hugging Faceアカウントを持っていない方はアカウント作成をしてください。登録するメールアドレスは上記のLlama2の利用申請に使ったメールアドレスと同じものである必要があります。
Llama2リポジトリへのアクセス申請
下記のLlama-2-7b-hfのリポジトリにアクセスします。
Model Cardのところに、下記画像のようなLlama2のアクセスに関する説明があります。
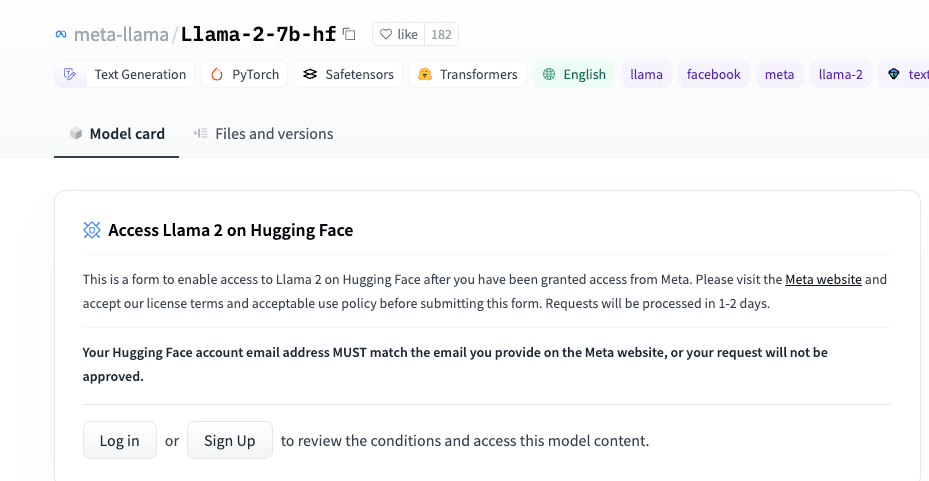
日本語訳
Hugging Face上のLlama 2へのアクセス これは、Metaからアクセス権が付与された後に、Hugging Face上のLlama 2へのアクセスを有効にするためのフォームです。このフォームを提出する前に、Metaのウェブサイトを訪れて、ライセンス条項と適切な利用ポリシーを受け入れてください。リクエストは1-2日で処理されます。
Hugging Faceのアカウントのメールアドレスは、Metaのウェブサイトで提供するメールアドレスと一致しなければなりません。それが一致しない場合、あなたのリクエストは承認されません。
これを提出したら、1~2日後Hugging Faceからメールが届きます。
(私の場合は1日以内に届きました)
アクセストークンの発行
Hugging FaceのSettingsから、Access Tokenを取得します。
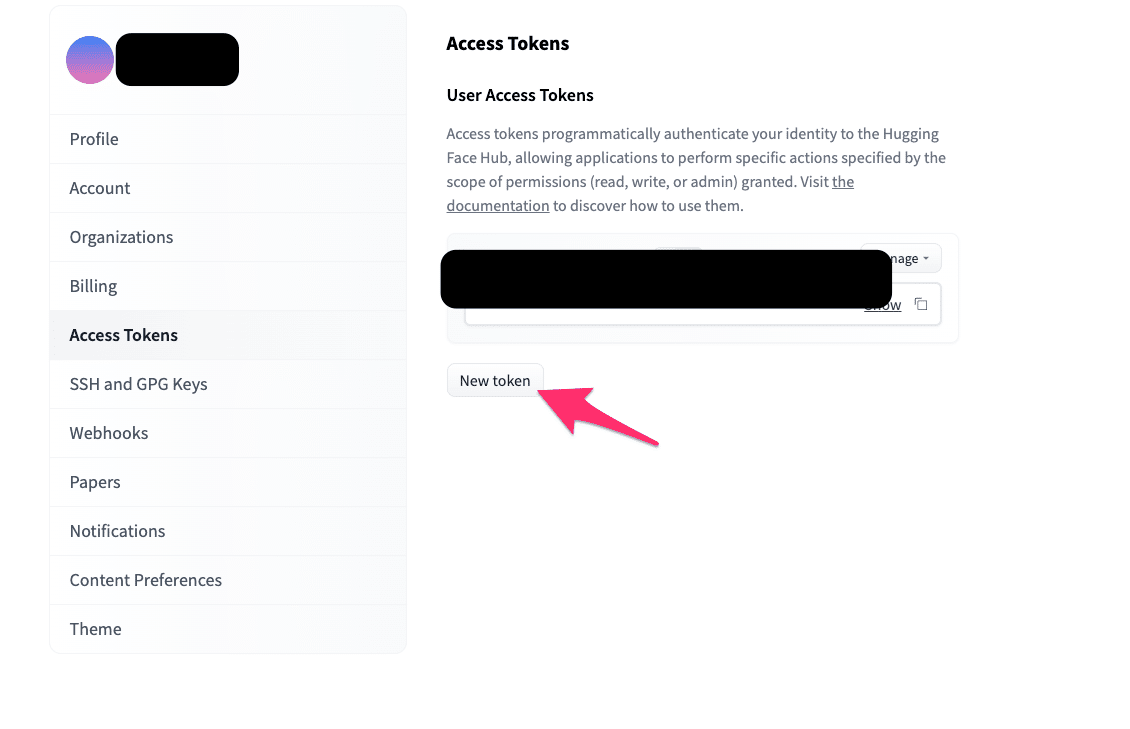
トークンの値は後ほど使うのでコピーしておいてください。
Google Colabのアカウント準備
Googleアカウントを持っていない場合は下記からアカウント作成します、持っている場合はログインしてください。
https://colab.research.google.com/?hl=ja
Google Colabの設定
メニューバーのランタイムから、ランタイムのタイプを変更を選択し、
ハードウェアアクセラレータ: GPU
GPUのタイプ: T4
を選択します。
※ Colab Pro以上のアカウントの方はGPUのタイプ: A100などを推奨

Google Colabでの実行
下記リンクにアクセスし、Google Colabのファイルを開く
※ コードはこの記事に載せるため、練習がてら新規でノートブックを作っても良いです。
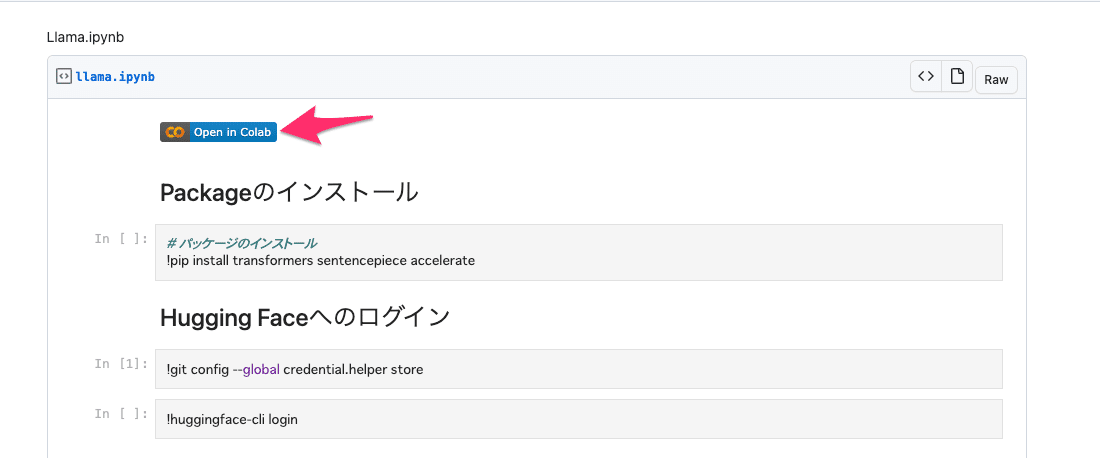
パッケージインストール
パッケージのインストールのコードの左側にある実行ボタンから実行する
# パッケージのインストール
!pip install transformers sentencepiece accelerate xformers
Hugging Faceにログイン
ログインをします。まずはgitで毎回パスワードを聞かれないように下記を設定してから、
!git config --global credential.helper storeHugging Faceにログインします
!huggingface-cli loginTokenを聞かれるので、Hugging Faceで先ほど取得したアクセストークン(hf_xxxxx)を入力します。

その後、「Add token as git credential? (Y/n) 」と聞かれるのでYで登録します。
トークナイザーとパイプラインの準備
下記コードを実行して、トークナイザーとパイプラインを準備します。
from transformers import AutoTokenizer
import transformers
import torch
# モデルID
model = "meta-llama/Llama-2-7b-chat-hf"
# トークナイザーとパイプラインの準備
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)推論実行
推論のコードを実行します。promptの内容は適時書き換えてください。
prompt = """USER: What is the highest mountain in Japan?
"""
sequences = pipeline(
prompt,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
print(sequences[0]["generated_text"])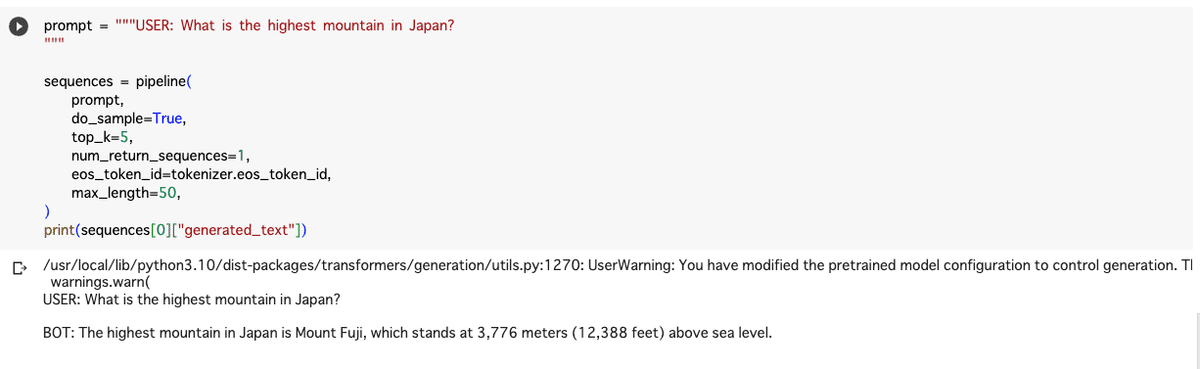
まとめ
Llama2をGoogle Colabで動作させる手順について、図解で解説しました。これほど早くにChatGPTと匹敵するLLMが、商用利用可能なオープンソースとして登場するとは想像していませんでした。LLMを利用したビジネスアイデアは、GPTのAPIに依存するだけでなく、独自にファインチューニングしたLLMを設ける可能性が広がったと考えています。次回は、Llama2のファインチューニングに挑戦してみたいと思います!
この記事が気に入ったらサポートをしてみませんか?