
DiffusersベースのStable Diffusion自作GUIを使う

既存のDiffusersベースのGUIだと画像生成の試行錯誤がしづらかったので、自作GUIの作成を続けています。AUTOMATIC1111版web UI(以下本家)が心の師匠です。
前回からの変更点
・七師氏のDiffusersベースライブラリ "Unstable Diffusion" を使用して画像生成。latent noiseでのinpaintを実現できた
https://github.com/nanashi161382/unstable_diffusion
・Unstable Diffusionに与えるTextEmbeddingはLong Prompt Weightingを使用。テキストモデルが扱える単語長の制限を超えてプロンプトを指定できる手法で、本家のアルゴリズム。
直接使用した版(AlanB氏の改造版)、使用箇所の実装はオリジナルと同一
※AlanB氏改造版のオリジナルはSkyTNT氏の実装(hugging faceのcommunity pipelineに登録)。こちらもリンクを掲載。
Unstable Diffusionではプロンプトに対するレイヤという概念があり、背景と人物とで異なるプロンプトを同時に使って画像生成したりと、いろいろ面白いことができそうです。複数呪文の同時詠唱…!
なお今のGUIでは、背景とプロンプトレイヤ1枚だけを使ってます。ポテンシャルをわずかに活用。
Diffusersの実装はコードが比較的読みやすいので、改造もしやすいように感じます。それにColab無料版でもRAM使用量の心配があまりないし。
準備
年末から正月にかけて、Stable Diffusionでの画像データの扱いや、理論面ではニューラルネットワークからAttention、拡散モデルまで軽く勉強し、GUIの実装に向けて知識を蓄えました。
キャラ生成のモデルには現状TrinArt v2を使用しています。なので今回は512x512サイズで画像生成します。
キャラを出現させる背景画と、キャラの位置をざっくりと指定するマスクを作成します。マスクはSVGで書いてPNGに変換しました。
(ブラウザの開発者機能からも保存できる→ https://www.omakase.net/blog/2020/10/screen.html が、CairoSVGを使って変換する方があとあと楽)

マスクの形状の狙いです。結果の通り、モデルは創意工夫して形状を使ってきますが…
・頭の位置と上半身の輪郭を指定
・ウェストのくびれまで入るとうれしい
元祖Diffusersや本家AUTOMATIC1111版ではマスク画像の白色をマスクの適用範囲とします。本家では白黒の反転指定も実装しているので、自作GUIでも反転指定を実装しています。マスクをSVGで書く場合、黒を適用範囲とする方がマスクを作りやすいですし。
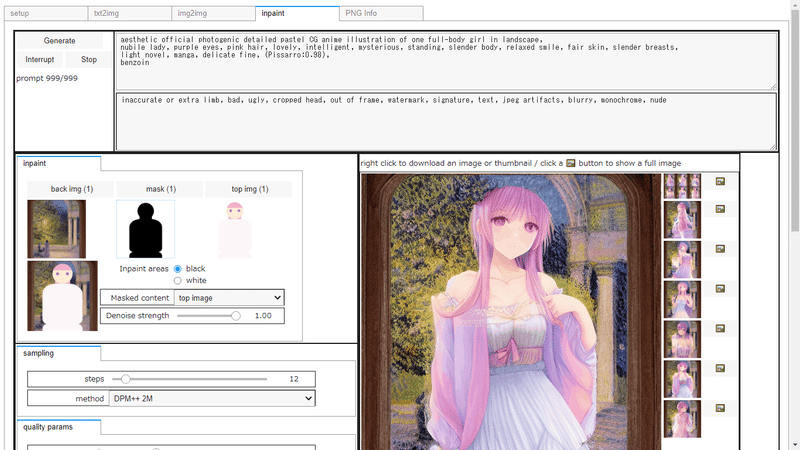
自作GUIでは生成パラメータを埋め込んだ縮小画像を作成し、特に複数画像をまとめたサムネイル化とパラメータの記録を兼用しています。このサムネイルを以下の結果でも活用しています。キャラ画像作成時にはシード値を大量に探すことになりますが、役に立ってくれることでしょう。
プロンプト:
aesthetic official photogenic detailed pastel CG anime illustration of one full-body girl in landscape,
nubile lady, purple eyes, pink hair, lovely, intelligent, mysterious, standing, slender body, relaxed smile, fair skin, slender breasts,
light novel, manga, delicate fine, (Pissarro:0.98),
benzoin
ネガティブプロンプト:
inaccurate or extra limb, bad, ugly, cropped head, out of frame, watermark, signature, text, jpeg artifacts, blurry, monochrome, nude
設定:
Steps: 8, Sampler: DPM++ 2M, CFG scale: 7.0, Seed: 20725624, Size: 512x512, Denoising strength: 1.0, Masked content: latent noise
Masked contentは自作GUI用のタグで、本家では使えません。Seed: 20725624はグリッドの左上の画像のシード値で、横方向にシード値が+1されて画像が生成されています。
あとプロンプトは作りたいゲームのキャラ設定に応じて自動生成しています。2段目と最後がキャラ設定に応じた部分です。
生成した画像


下段ではキャラがマスクにぶつかったり明後日を向いたりと自由
自作GUIの目的は、本家AUTOMATIC1111版にあるlatent noiseを使ったinpaintの再現です。本家同様に、Masked contentにinpaintの初期データの種類を指定します。初期データがlatent noiseだと背景の色に左右されず画像生成できるので、キャラクターを背景に書き込むにはちょうど良いです。
Diffusers純正のコードだと生成時にマスクと潜在空間上の初期データを両方同時に指定できないので、自分でDiffusersを改造するか、本家のようにイチから実装する必要がありました。Unstable Diffusionをはじめ先達に感謝です。
自作GUIの動作確認を兼ねて、ステップ数をいくつか振って比べました。
シード値を試行してキャラのあたりをつける用途では、DPM++ 2Mだと8stepsで十分そうです。設定をそろえたとはいえ、本家での生成とほぼ同じ画風のキャラが出てきたのはびっくりしました。
※DiffusersとAUTOMATIC1111版とでは、同じ計算手法を指すサンプラーでも実装の計算式が少し異なる。そのため生成画像も同一になるとは限らない。(だからこそ驚いた)

DPM++ 2Mの場合、キャラのあたりを付けるなら8stepsで足りる
Text Embeddingの違いについて
変更点でも触れましたが、自作GUIではText Embedding(プロンプトの文章を画像生成のヒントの情報に変換したもの)の生成に、Unstable Diffusionの実装ではなくLPW Stable Diffusion Pipelineの実装を使っています。無理やり呼び出しました…
というのも、デフォルトのShiftEncodingの結果も悪くないのですが、どうも生成結果がStable Diffusionのデフォルトのモデルっぽい画風になるためです。
CLIPを呼び出すだけのStandardEncodingだとTrinArtっぽい画風になったので、多分ShiftEncoding内でのテキスト処理によって画風の違いが出ているのだと思います。Text Embeddingの少しの違いでも画風に影響するのは意外でした。

初期データごとの違い
latent noiseを使ったinpaintの再現の前に、fillなどの再現もしました。こちらはLPW Stable Diffusion Pipelineで画像生成していた時に実装済みで、Unstable Diffusionに置き換えてもうまく動くよう実装できました。

本家にあるinpaintの機能として、与えた画像をピクセルベースで加工し、それを初期データに使用してマスクも適用した画像生成ができます。正確には inpaint というよりは img2imgに近い動作です。
・fill:指定した画像に対し、マスク適用部分を灰色で塗りつぶす。
・top image:独自実装。指定画像の上に画像を貼り付ける。その時にマスクで上側の画像を切り抜く。
・mode channel:独自実装。fillで色指定したような動作。指定画像のうちマスク適用範囲について色の最頻値(mode of RGB channel)をとり、その色で塗りつぶす。
・original:指定画像をそのまま使用。マスクも有効。img2imgを使ってinpaintした部分をなじませるときに重宝
なお本家ではMask Blurという設定でマスクをぼかしてinpaintができるのですが、自作GUIでは未実装です。
初期データに画像を使うinpaintの傾向として、元画像の色の影響をそれなりに受けます。fillではキャラが薄暗く、mode channelではマスク範囲が暗緑色になり、キャラにもやや緑っぽい服や背景が出たりしました。originalもmode channelと同様の傾向に近いです。
top imageでは使った画像が白っぽかったのでキャラの服が白く、というかスリップ姿で出てくる子も多かったです。画像に目を入れることで構図をがっちり固定できるのはimg2imgならではの特長です。出てくる構図をもう少し柔軟にしたい場合はstrengthを弱めるとよさそう。
後半に続く
長くなったので後半に続きます。自作GUIを使ったキャラ立ち絵制作の作業の流れを考えました。
この記事が気に入ったらサポートをしてみませんか?