
データ分析基盤のアーキテクチャ特性を考える。

分析屋の下滝です。
本記事では、データ分析基盤のアーキテクチャ特性として、どのようなものが議論されているのかを調査します。特に、データ分析基盤のアーキテクチャパターン(スタイル)の比較の際に、どのような議論がされているのかを見ます。具体的には、データウェアハウス、データレイク、データウェアハウス、データメッシュなどのアーキテクチャパターンです。
アーキテクチャ特性とは、非機能特性や品質特性としても表現される、機能要件ではないとされるものです[1]。通常、可用性(Availability)や信頼性(Reliability)など「イリティ(-ility)」として表現されるものです。
つまり、どのような評価基準で、それぞれのアーキテクチャパターンのメリットやデメリットが議論されているのかを見ます。
通常、新たなアーキテクチャパターンは、既存のアーキテクチャパターンが抱える問題を解決するような視点で議論されます。ただし、通常は、新たなアーキテクチャパターンが既存のアーキテクチャパターンを完全に置き換えることはなく、一定のトレードオフが発生します。つまり、すべてのアーキテクチャ特性を保ったまま、特定のアーキテクチャ特性を改善するようなケースは、それほど多くないと言えます。
アーキテクチャ
『ソフトウェアアーキテクチャの基礎』によれば、アーキテクチャは、次の4つで構成されます。
・システムの構造
・アーキテクチャ特性
・アーキテクチャ決定
・設計指針
システムの構造とは、そのシステムを実装するアーキテクチャスタイルの種類(マイクロサービスやレイヤード、マイクロカーネルなど)のことを意味します。
アーキテクチャ特性とは、システムの成功基準を定めるものとされます。
アーキテクチャ決定とは、システムをどのように構築すべきかのルールを定めるものを意味します。たとえば、レイヤードアーキテクチャのパターンにおいて、ビジネス層とサービス層のみがデータベースに直接アクセスできる、といったアーキテクチャ決定です。アーキテクチャ決定は、システムの制約となります。
設計指針は、ガイドラインのようなものです。たとえば、「開発チームはマイクロサービスアーキテクチャのサービス間の非同期メッセージングを利用して、パフォーマンスを向上させるべき」といったものです。
なお『ソフトウェアアーキテクチャの基礎』では、アーキテクチャスタイルとアーキテクチャパターンを区別するような記述は見られますが、本記事では同様のものと見なします。どちらも、個々のアーキテクチャを抽象化して名前をつけて表現したものだと捉えられます。
データ分析基盤のアーキテクチャパターン
本記事では、アーキテクチャ特性を、アーキテクチャパターンを比較・評価する上での項目であると見なしています。『ソフトウェアアーキテクチャの基礎』と同書の続きの『ソフトウェアアーキテクチャ・ハードパーツ』では、明確にそうは書いていないかもしれません(見つけられなかっただけの可能性もあります)が、そのように解釈しました。
いずれにせよ、我々は、どのアーキテクチャパターンを選ぶかは、特定の選評価項目に基づいていて行っている、と考えられます。
本記事では、以下の文献で述べられているアーキテクチャパターンが、どのような評価項目により議論されているのかを調査します。
・『ソフトウェアアーキテクチャ・ハードパーツ』
・Lakehouse: A New Generation of Open Platforms that Unify DataWarehousing and Advanced Analytics (PDF)
なお、アーキテクチャ特性は「イリティ(-ility)」として表現されると述べまたが、今回議論する評価項目は、イリティと表現されることはほとんどなさそうです。
各評価項目に関しての詳細な分析は、次回以降に行います。
『ソフトウェアアーキテクチャ・ハードパーツ』
『ソフトウェアアーキテクチャ・ハードパーツ』では、以下の3つのアーキテクチャパターンが紹介されています。
・データウェアハウス
・データレイク
・データメッシュ
データウェアハウス
同書では、データウェアハウスパターンの定義やアーキテクチャの構成図はなさそうでしたので、wikipediaから引用します。
コンピューティングにおいては、データウェアハウス(DWまたはDWH)とは、レポートやデータ分析に使用されるシステムであり、ビジネスインテリジェンスの中核をなすものと考えられている[1]。データウェアハウスは、一つまたは複数の異なるソースから統合されたデータの中央リポジトリーである。データウェアハウスは、現在および過去のデータを1つの場所に保存し[2]、企業全体の従業員のための分析レポートを作成するために使用される[3]。これは、データを照会して洞察を引き出し、意思決定を行うことができるため、企業にとって有益である[4]。
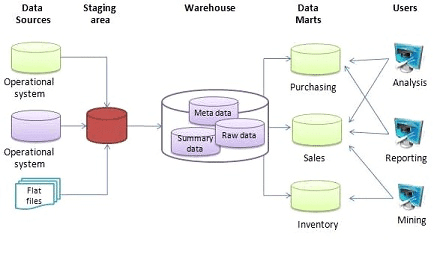
同書では、データウェアハウスの欠点には以下があげられています。
・統合の脆さ
・ドメイン知識の極端な分割
・複雑さ
・意図した目的に対する機能の制限
・同期化によるボトルネック
・業務用のコントラクトと分析用のコントラクトの違い
本記事ではこれらのそれぞれの項目がアーキテクチャ特性の一つ(あるいは複数)だと捉えます。
同書では、「ドメイン」という言葉がこれらの欠点を取り上げる上でのキーワードの一つとなっていると考えられるため、もう少し補足します。
データウェアハウスパターンは、ソフトウェアーキテクチャにおける技術による分割の良い例だ。ウェアハウスの設計者は、クエリや分析を容易にするスキーマにデータを変換するが、それによってドメインによる分割は失われ、必要に応じてクエリで再作成しなければならなくなる。そのため、このアーキテクチャでのクエリの作成方法を理解するには、高度な訓練を受けた専門家が必要となる。
「技術による分割」と「ドメインによる分割」は、うまく説明できるほど理解できていないのですが、図を引用します。

これら2つの分割は、アーキテクチャを決める上での最上位の決め事だとされます。技術による分割は、技術能力の分割とも表現されており、従来のレイヤードアーキテクチャのようなアーキテクチャが対応します。ドメインによる分割は、ドメイン駆動開発の考えをもとにしており、モジュラーモノリスのようなアーキテクチャが対応します。
各項目に関してざっくりと説明します。
統合の脆さ
これは、あるドメインでのデータベーススキーマを変更が発生すると、データウェアハウス側のデータ変換処理やスキーマに変更が発生することを意味します。
ドメイン知識の極端な分割
データウェアハウスでは、データを一箇所に集めて統合します(追加的にデータマートが作られることもあります)。そして、その統合されたデータを使って、BIシステム構築やレポート作成を行います。そのような構築や作成には、ドメイン知識と専門的な分析技術が必要になりますが、必要となる箇所は、部分的にしか重なっていません。それにも関わらず、アーキテクト、開発者、DBA、データサイエンティストは、全員でデータの変更や進化について調整しなければなりません。
なお「ドメイン知識の極端な分割」という表現がどうしてされているのかよくわからなかったので、違うかも知れませんが、統合されたシステムであることは、各システムの関係者にとっては余計なものが含まれている、という意味かもしれません。
複雑さ
これは、スキーマやデータ変換処理による、システムの複雑さを意味します。
意図した目的に対する機能の制限
これは、投資したコストとそれに見合うビジネス価値を提供できるかどうかを意味します。データウェアハウスを構築したとしても、データウェアハウスでは提供できない特定の種類のレポートがデータの利用者から求められるといった状況も存在するためです。
同期化によるボトルネック
データウェアハウスでは、さまざまな業務システム間でデータを同期させる必要があるため、業務上および組織上のボトルネックが発生するとされます。
業務用のコントラクトと分析用のコントラクトの違い
まず、コントラクトとは「アーキテクチャの部品が情報や依存関係を伝えるためのフォーマット」を意味します。具体的には、XML SchemaやRPC、GraphQL、REST、シンプルなJSONなどを意味します。
分析システムでもコントラクトのニーズはあるが、業務システムとは異なるニーズであることが多いことに関わるとされます。データウェアハウスでは、パイプラインがデータの取得だけでなく変換も処理することが多く、変換プロセスにコントラクト上の脆さが生じるとされます。この意味は恐らく、業務用のシステムからデータを取得する際に、コントラクトが分析システム用に必要ということかもしれません。
以上、正確に理解できてない箇所がいくつかありますが、データウェアハウスの欠点を確認しました。
次に、メリットとデメリットという視点でトレードオフとして次のように示されています。
<メリット>
・データの集中的な統合
・専用の分析サイロを隔離
<デメリット>
・ドメイン知識の極端な分割
・統合の難しさ
・複雑さ
・意図した目的に対する機能の制限
欠点のいくつかはデメリットに含まれています。
データレイク
データレイクパターンは、データを生のままそのまま保存するデータレイクと呼ばれる役割をもつストレージ(たとえばS3などのオブジェクトストレージ)が構成要素として存在するアーキテクチャです。
データウェアハウスでは、業務システムから取得したデータを「変換してデータウェアハウスにロード」しますが、データレイクは「データレイクにロードしてから変換する」というモデルになります。
データレイクパターンにより、データウェアハウスパターンの問題点のいくつかは解決できたものの、新たな問題が作り出したとされます。以下があげられています。
・適切な資産の発見が困難になる
・個人情報およびその他の機密データ
・技術による分割でなく、ドメインによる分割
本記事は、これらはデータウェアハウスと同様に、アーキテクチャ特性に関わる項目だと捉えます。
適切な資産の発見が困難になる
「関係としてデータの中に表現されているドメイン知識の多くは、構造化されていないデータレイクへと流れ込むと蒸発してしまう。そのため、ドメインエキスパートは、依然として手動で分析を行わなければならない」とされいます。これは、統合して分析する必要があるデータを扱う場合に、必要なデータを見つけるのが困難という意味かと思われます。
個人情報およびその他の機密データ
これは、構造化されていないデータをデータレイクに保存すると、プライバシーを侵害するような情報が露出する危険性を意味します。そうした偶発的な漏洩を避けるために必要な知識をもっているのはドメインエキスパートであり、ドメインエキスパートは、データレイク内のデータに対して、発見プロセスの中で行ったのと同じチェックを、データレイク内のデータに対して再度行う必要がでてくるとされます。なお、ここでいう発見プロセスが何を意味するのは具体的な説明はありませんでした。
技術による分割でなく、ドメインによる分割
データウェアハウスもデータレイクも、技術による分割の例だとされます。一方で、現在のアーキテクチャのトレンドは、ドメインに基づくシステムの分割です。ここでいう技術による分割とは、「取り込み」、「変換」、「読み込み」、「提供」といった技術能力での分割のことです。ドメイン分割では、それらの技術能力はドメインの中にデータも含めてカプセル化されます。データウェアハウスもデータレイクでは、データをドメインとは独立して分離しようとするため、個人情報のような重要なドメインの視点が失われたり、不明瞭になるとされます。
トレードオフとして次のように分析がされています。
<メリット>
・データウェアハウスよりも構造化されていない
・事前の変換が少ない
・分散アーキテクチャに適している
<デメリット>
・関係性の把握が困難な場合がある
・場当たり的な変換が必要
データメッシュ
データメッシュは「分析データを非中央集権的なやり方で共有、アクセス、管理するためのソシオテクニカルなアプローチ」とされます。ここでは詳しい説明は省略します。
データメッシュの欠点という説明はありませんでしたが、トレードオフとして次のように分析がされています。
<メリット>
・マイクロサービスアーキテクチャに最適
・現代的なアーキテクチャの原則とエンジニアリングに従っている
・分析データと業務データの間に優れた分離をもたらす
・慎重に形成されたコントラクトにより、分析能力を疎結合に進化できる
<デメリット>
・DPQ(データプロダクト量子)とのコントラクト調整を必要とする
・非同期通信と結果整合性を必要とする
データメッシュは、マイクロサービスのような最新の分散アーキテクチャに最適なパターンとされます。
『Lakehouse』
「Lakehouse: A New Generation of Open Platforms that Unify DataWarehousing and Advanced Analytics」では、現在のデータレイクとデータウェアハウスの2層で構成されるアーキテクチャの問題点として次の4点を挙げています。

レイクハウスは、このような問題を解決するアーキテクチャとなります。
以下、4つの問題点をそのまま引用します。
・信頼性(Reliability):データレイクとウェアハウスの整合性を保つことは難しく、コストもかかります。2つのシステム間でデータをETLし、高性能な意思決定支援やBIで利用できるようにするためには、継続的なエンジニアリングが必要です。また、ETLの各ステップでは、データレイクとウェアハウスのエンジン間の微妙な違いなどにより、データ品質を低下させる失敗やバグが発生するリスクがあります。
・データ陳腐化(Data staleness):ウェアハウスデータはデータレイクと比較して古く、新しいデータを読み込むのに数日かかることが頻繁にあります。これは、新しい運用データをすぐにクエリに利用できた第一世代のアナリティクス・システムと比べると、一歩後退しています。Dimensional ResearchとFivetranによる調査によると、アナリストの86%が古いデータを使用しており、62%が月に何度もエンジニアリングリソースを待っていると報告しています[47]。
・高度な分析への限られた対応(Limited support for advanced analytics):企業は、ウェアハウスデータを使って、例えば「どの顧客に割引を提供すべきか」といった予測的な質問をしたいと考えています。MLとデータ管理の融合について多くの研究がなされていますが、TensorFlow、PyTorch、XGBoostなどの主要な機械学習システムは、ウェアハウスの上でうまく機能するものはありません。少量のデータを抽出するBIクエリとは異なり、これらのシステムは、複雑な非SQLコードを使用して大規模なデータセットを処理する必要があります。ODBC/JDBC経由でこのデータを読み込むのは非効率的であり、ウェアハウス内部の独自フォーマットに直接アクセスする方法はありません。このような用途の場合、ウェアハウスベンダーはデータをファイルにエクスポートすることを推奨していますが、これは複雑さと陳腐さをさらに増大させます(第3のETLステップを追加することになります)。別の方法として、ユーザーはオープンフォーマットのデータレイクデータに対してこれらのシステムを実行することができます。しかし、この場合、ACIDトランザクション、データのバージョン管理、インデックス作成など、データウェアハウスが持つ豊富な管理機能が失われます。
・総所有コスト(Total cost of ownership):継続的なETLにかかる費用とは別に、ユーザーはウェアハウスにコピーされたデータに対して2倍のストレージ費用を支払うことになります。また、商用ウェアハウスはデータを独自のフォーマットに固定するため、データやワークロードを他のシステムに移行する際のコストが高くなります。
アーキテクチャ特性の一覧
これまで議論したアーキテクチャパターンのアーキテクチャ特性の一覧を以下にまとめます。
【データウェアハウス】
・統合の脆さ
・ドメイン知識の極端な分割
・複雑さ
・意図した目的に対する機能の制限
・同期化によるボトルネック
・業務用のコントラクトと分析用のコントラクトの違い
<メリット>
・データの集中的な統合
・専用の分析サイロを隔離
<デメリット>
・統合の難しさ
【データレイク】
・適切な資産の発見が困難になる
・個人情報およびその他の機密データ
・技術による分割でなく、ドメインによる分割
<メリット>
・データウェアハウスよりも構造化されていない
・事前の変換が少ない
・分散アーキテクチャに適している
<デメリット>
・関係性の把握が困難な場合がある
・場当たり的な変換が必要
【データメッシュ】
<メリット>
・マイクロサービスアーキテクチャに最適
・現代的なアーキテクチャの原則とエンジニアリングに従っている
・分析データと業務データの間に優れた分離をもたらす
・慎重に形成されたコントラクトにより、分析能力を疎結合に進化できる
<デメリット>
・DPQ(データプロダクト量子)とのコントラクト調整を必要とする
・非同期通信と結果整合性を必要とする
【レイクハウス】
・信頼性
・データ陳腐化
・高度な分析への限られた対応
・総所有コスト
考察
以下の3点で、考察します。
1.比較のための共通のアーキテクチャ特性の一覧
2.アーキテクチャ特性の抽象度や粒度
3.アーキテクチャ特性の出現
これらは、あるアーキテクチャパターンから他のアーキテクチャパターンへの進化をどのように評価し、意思決定すれば良いのかを容易にするために必要な視点と言えるかも知れません。

一つは、『ソフトウェアアーキテクチャ・ハードパーツ』の中でさえ、共通のアーキテクチャ特性ごとに評価されていないことです。これは、意図的なかもしれませんし、そうではないのかもしれません。データ分析基盤の各アーキテクチャパターンを比較する際は、各パターンがその他のパターンと比べてどのようなアーキテクチャ特性の点で、優劣があるのかを知りたいところです。
実際、『ソフトウェアーキテクチャの基礎』では、共通のアーキテクチャ特性の一覧をもとに、評価表により整理されています。以下に、レイヤードアーキテクチャの評価を示します。
アーキテクチャ特性 | 星評価
===============
分割タイプ | 技術
量子数 | 1
デプロイ容易性 | ★
弾力性 | ★
進化性 | ★
対障害性 | ★
モジュール性 | ★
全体的なコスト | ★★★★★
パフォーマンス | ★★
信頼性 | ★★★
スケーラビリティ | ★
シンプルさ | ★★★★★
テスト容易性 | ★★
同様にたとえば、マイクロサービスアーキテクチャの場合も同じアーキテクチャ特性を使って評価がされています。
アーキテクチャ特性 | 星評価
===============
分割タイプ | ドメイン
量子数 | 1以上
デプロイ容易性 | ★★★★
弾力性 | ★★★★★
進化性 | ★★★★★
対障害性 | ★★★★
モジュール性 | ★★★★★★
全体的なコスト | ★
パフォーマンス | ★★
信頼性 | ★★★★
スケーラビリティ | ★★★★★
シンプルさ | ★
テスト容易性 | ★★★★
2つ目は、欠点やトレードオフとしてメリットやデメリットとして見てきた項目が、上記のようなアーキテクチャ特性のような抽象度や粒度で表現されていないように見えることです。たとえば以下の項目は、アーキテクチャ特性でしょうか?
・意図した目的に対する機能の制限
・技術による分割でなく、ドメインによる分割
・マイクロサービスアーキテクチャに最適
・DPQ(データプロダクト量子)とのコントラクト調整を必要とする
これは、すでに述べましたが、そもそもアーキテクチャ特性ではない、別の概念という可能性もあります。この点に関しては、別の記事で議論したいと思います。
アーキテクチャ特性自体の性質をこのように議論する理由は、我々がそもそもアーキテクチャ特性という概念をまだ十分に理解できてない理論的な背景があるかも知れないためです。たとえば、
・アーキテクチャ特性は合成可能性でしょうか?あるいは分解可能でしょうか・
・アーキテクチャ特性は、何が決まれば決まるのでしょうか? あるアーキテクチャパターンに関するアーキテクチャ特性が網羅できているとは、どのように確認すればよいでしょうか? アーキテクチャの構成要素とその関係が決まれば、可能なアーキテクチャ特性の集合が決まるのでしょうか?
3つ目は、もう少し詳しい調査が必要でありますが、アーキテクチャ特性自体が、新たなアーキテクチャの出現により、増えることがありそうな点です。たとえば、データメッシュというアーキテクチャパターンが新たに出現したことにより、これまでのデータウェアハウスやデータレイクのアーキテクチャは、データメッシュと比べてどうなのか、といった比較がされることになりました。これはたとえば「技術による分割でなく、ドメインによる分割」といった視点があることからもわかります。ドメインによる分割にもとづくデータメッシュのようなアーキテクチャが出てこなければ、この視点での評価は出てこないと考えられます。
まとめ
本記事では、データ分析基盤のアーキテクチャ特性を考えるための準備を行いました。データウェアハウス、データレイク、データメッシュ、データレイクハウスの4つのそれぞれのアーキテクチャパターンが、他のアーキテクチャパターンと比べて、どのような項目で評価されているのかを確認しました。
次回は、もう少し踏み込んだ分析を行いたいと思います。
参考文献
[1] ソフトウェアアーキテクチャの基礎
メモ
株式会社分析屋について
ホームページはこちら。
noteでの会社紹介記事はこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。