
Snowflakeでテーブル比較してみた

分析屋の中田(ナカタ)です。
Snowflakeでテーブルを比較するプロシージャを作成してみました。
今回やること
2つのテーブルが完全に一致するのか確かめるストアドプロシージャを作成します。
環境
Snowflakeのエディション:エンタープライズ版
クラウド:AWS(東京リージョン)
①ストアドプロシージャの作成
いきなりですが、定義文は以下の通りです。
CREATE OR REPLACE PROCEDURE TRAIN.KNAKATA.COMP
("TABLE_FULL_NAME1" VARCHAR, "TABLE_FULL_NAME2" VARCHAR)
RETURNS TABLE ()
LANGUAGE SQL
COMMENT='テーブル2つの差分比較をする。列定義が異なる場合は事前にCASTすること。'
AS 'DECLARE
select_statement VARCHAR;
res RESULTSET;
begin
select_statement := $$WITH a AS (SELECT *, COUNT(*) AS "重複度" FROM $$ || TABLE_FULL_NAME1 || '' GROUP BY ALL),'' ||
$$ b AS (SELECT *, COUNT(*) AS "重複度" FROM $$ || TABLE_FULL_NAME2 || '' GROUP BY ALL)'' ||
$$(SELECT ''テーブル1に多い'' as "差分", * FROM a$$ ||
'' except '' ||
$$SELECT ''テーブル1に多い'' as "差分", * FROM b$$ ||
$$)UNION (SELECT ''テーブル2に多い'' as "差分", * FROM b$$ ||
'' except '' ||
$$SELECT ''テーブル2に多い'' as "差分", * FROM a$$ ||'' )'';
res := (EXECUTE IMMEDIATE :select_statement);
RETURN TABLE(res);
end';個別にアレンジが必要なのは1行目の以下の部分だけです。
ここは自身の環境のデータベース名.スキーマ名.好きな関数名を指定してください。
サンプルコードはTRAINデータベースのKNAKATAスキーマのCOMP関数です。
TRAIN.KNAKATA.COMPコードの上から順に、内容を見ていきます。
CREATE OR REPLACE PROCEDURE TRAIN.KNAKATA.COMP
("TABLE_FULL_NAME1" VARCHAR, "TABLE_FULL_NAME2" VARCHAR)プロシージャを宣言しています。
引数は2つで、比較したいテーブルの「データベース名.スキーマ名.テーブル名」を文字列で受け取ることを想定しています。
RETURNS TABLE ()
LANGUAGE SQL
COMMENT='テーブル2つの差分比較をする。列定義が異なる場合は事前にCASTすること。'上から順に
戻り値はテーブルだよ!
ロジック部分はSQLで書いているよ!
コメントを付けているよ!
という内容です。
AS 'DECLARE
select_statement VARCHAR;
res RESULTSET;
begin以降、ロジック部分をSQLで書いています。
ここでは変数を2つ宣言しています。
select_statementには比較するためのSQL文が格納されます。
resには比較結果のテーブルが格納されます。
select_statement := $$WITH a AS (SELECT *, COUNT(*) AS "重複度" FROM $$ || TABLE_FULL_NAME1 || '' GROUP BY ALL),'' ||
$$ b AS (SELECT *, COUNT(*) AS "重複度" FROM $$ || TABLE_FULL_NAME2 || '' GROUP BY ALL)'' ||
$$(SELECT ''テーブル1に多い'' as "差分", * FROM a$$ ||
'' except '' ||
$$SELECT ''テーブル1に多い'' as "差分", * FROM b$$ ||
$$)UNION (SELECT ''テーブル2に多い'' as "差分", * FROM b$$ ||
'' except '' ||
$$SELECT ''テーブル2に多い'' as "差分", * FROM a$$ ||'' )'';ここが比較用のSQL文を組み立てる場所であり、一番ぐちゃぐちゃしているところです。
この部分は実行時には以下のようになります。
WITH a AS (
SELECT
*
, COUNT(*) AS "重複度"
FROM
db_name.schema_name_table1_name
GROUP BY ALL
),
b AS (
SELECT
*
, COUNT(*) AS "重複度"
FROM
db_name.schema_name_table2_name
GROUP BY ALL)
(SELECT
'テーブル1に多い' as "差分"
, *
FROM a
except
SELECT
'テーブル1に多い' as "差分"
, *
FROM b)
UNION
(SELECT
'テーブル2に多い' as "差分"
, *
FROM b
except
SELECT
'テーブル2に多い' as "差分"
, *
FROM a)基本ロジックは集合演算のA-BとB-Aで差分を検知しています。
ただし、これだけだと重複は検知されません。
a,b,cとa,b,b,c,c,cなどは完全一致の扱いになってしまいます。
そこで、WITH句で重複の行数をカウントしています。
重複の行数を含めてA-BとB-Aを取ることで、重複を考慮した比較をしています。
②比較してみる
前提として、2テーブルは列構成が一致している必要があります。
今回は列構成が同じで内容の異なるテーブルを用意しました。
TRAIN.KNAKATA.BEFORE_DATAテーブル
TRAIN.KNAKATA.AFTER_DATAテーブル

比較するには以下のクエリを書いて実行します。
CALL TRAIN.KNAKATA.COMP('TRAIN.KNAKATA.BEFORE_DATA','TRAIN.KNAKATA.AFTER_DATA');こんな感じで比較結果が表示されます。
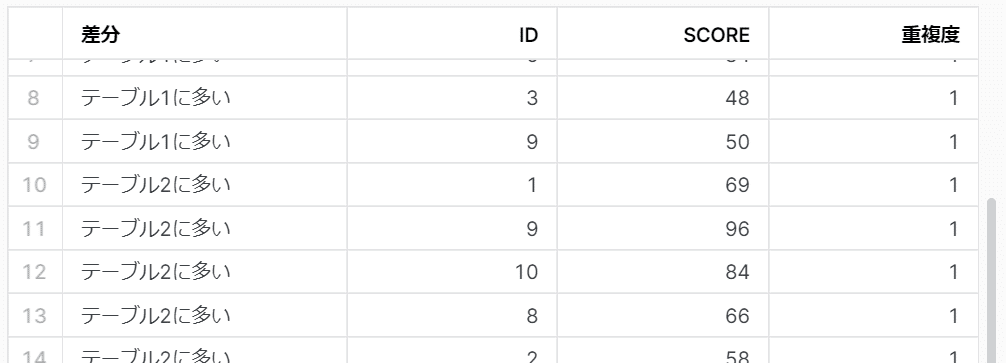
さらにこの比較結果を使用したい場合は
直後に以下のクエリを実行します。
SELECT * FROM TABLE(RESULT_SCAN(LAST_QUERY_ID()));こちらは直前のクエリ実行結果を取得するクエリです。
CREATE TABLE テーブル名 AS をつけてCTAS文にすれば
テーブルに保存することも可能です。
最後に
改善の余地はまだあるプロシージャだと思います。
まず、そもそもプロシージャではなく関数にすれば
LAST_QUERY_IDを使わずとも結果を容易に扱えます。
(今回は関数でうまく実装できなかったのでプロシージャにしました)
何より不便なのは、引数を文字列で渡すため
自動候補表示が効かないことです。
良き改善案を模索してまいります!
ここまでお読みいただき、ありがとうございました!
この記事が少しでも参考になりましたら「スキ」を押していただけると幸いです!
これまでの記事はこちら!
株式会社分析屋について
弊社が作成を行いました分析レポートを、鎌倉市観光協会様HPに掲載いただきました。
ホームページはこちら。
noteでの会社紹介記事はこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。