
【蒸留GPT】GPT3.5でGPT4を超える方法〜超実践的ファインチューニング〜

前回の記事では、ファインチューニングによってgpt4並の性能をgpt3.5-turboで実現する方法を解説しました。
今回はgpt4以上の性能をgpt3.5-turboで達成する方法を解説します。
要約を例に解説しますが、他のタスクも同様の手法が使えます。
要約タスクにおけるGPT4の弱点
それは厳密な文字数の指定ができないことです。
例えば「100文字で要約してください」と指示しても出力されるのは50文字だったり70文字だったりして、ほとんどの場合で100文字になりません。
文字数を指定するからには、その文字数を使い切ってできる限り多くの情報を含めてもらいたいものです。
今回はファインチューニングを利用して、gpt4の弱点である文字数指定をgpt3.5-turboで達成することを目指します。
Xにおける最適な文字数は100文字とも言われているので、これができれば最適なポスト文を作成するアシスタントAIも作れそうです。
やり方解説
前回と同じように、今回も「livedoor ニュースコーパス」を元に要約特化モデルを作成します。
手順は以下の通りです。
元データの用意
GPT4を用いて高品質な訓練データを作成
ファインチューニング
ファインチューニングしたモデルの検証
高品質な訓練データを作成する部分以外は前回と同じなので、前回の記事を読んでいる方は読み飛ばしても大丈夫です。
1. 元データの用意
まず、livedoor ニュースコーパスから必要なデータをダウンロードします。
こちらにアクセスして「ダウンロード(通常テキスト):ldcc-20140209.tar.gz」をダウンロードしてください。
ダウンロードしたファイルを解凍し、一例として以下のように配置してください。
main.py # 訓練データ生成のコード(後述)
text # 解凍したテキストファイルが格納されたディレクトリ要はmain.pyからtextディレクトリを参照できるようにすればOKです。
2. GPT4を用いて高品質な訓練データを作成
前回と同じように、今回もGPT4を用いて訓練データを作成します。
前回と違うところは、以下の3点です。
要約した文章の文字数が指定の長さになるまで改善を繰り返させる
100文字に要約させたいのであれば、95~105文字の範囲内に収まるまで改善をさせる
これによってすべての訓練データが95~105文字の範囲に収まった高品質なデータが作成できる
リアルタイムの処理に使うには速度・コストともに見合わないが、訓練データの作成には問題なし
大量のデータセットを用意する
公式では50~100個のデータで結果が出るとも言われているが、100個のデータを使用してもgpt4以上の性能は出せなかった
今回は500個のデータを用意させて検証を行った
ファインチューニング済みのGPT3.5モデルを利用して訓練データを作成させる
GPT4で大量のデータセットを作成しようとすると数十ドルのコストがかかってしまう
コストを削減するために、ファインチューニング済みのモデルを利用する
100個程度のデータを使ってファインチューニングしたモデルを使っても、改善を繰り返させるようにプログラムを組めば、問題なく高品質のデータセットを作成できる
今回は前回作成したモデルを使用する
高品質なデータを学習に使うことでGPT4以上の性能をGPT3.5-turboに持たせることが可能になります。
以下は訓練データ生成のコードです。
import os
import random
from openai import OpenAI
from tqdm import tqdm
import glob
import json
# APIキーを設定
client = OpenAI(api_key=API_KEY)
# 指定したディレクトリ内のtxtファイルからランダムに指定した数だけ読み込み、
# その内容を文字列のリストとして返す関数。
def read_random_txt_files(directory, num_files):
# ディレクトリ内の全てのtxtファイルのパスを取得
txt_files = glob.glob(os.path.join(directory, '**', '*.txt'), recursive=True)
# ランダムにファイルを選択
selected_files = random.sample(txt_files, min(num_files, len(txt_files)))
# 選択したファイルの内容を読み込む
contents = []
for file in selected_files:
with open(file, 'r', encoding='utf-8') as f:
contents.append(f.read())
return contents
# サマライズのシステムプロンプトを作成する関数
def create_summarize_system_prompt(char_count=100):
system_prompt = system_prompt = f"""\
You are a summary assistant.
The summary must meet the following
- three lines of bullet points
- Total of three lines is {char_count} characters
- **Include all important information**
- Include as much information as possible
- Output in Japanese"""
return system_prompt
# 指定の文字数で要約する関数
# 許容誤差の範囲内になるまで要約の改善を繰り返す
def summarize(
text,
ideal_chars_cnt=100,
tolerance=0.05,
model="gpt-4-1106-preview",
max_improvements_cnt=10,
):
# 要約を生成するためのシステムプロンプトを作成します。
system_prompt = create_summarize_system_prompt(ideal_chars_cnt)
# 許容する文字数の下限と上限を計算します。
lower_tolerance_limit = ideal_chars_cnt * (1 - tolerance)
upper_tolerance_limit = ideal_chars_cnt * (1 + tolerance)
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": text},
]
# 要約します
completion = client.chat.completions.create(
model=model,
messages=messages,
)
summary = completion.choices[0].message.content
# 要約の文字数を計算します。
chars_cnt = len(summary)
# 要約の文字数が許容範囲内になるまで、または最大改善回数に達するまでループします。
for improvements_cnt in range(max_improvements_cnt):
# 要約の文字数が許容範囲以下の場合、テキストを少し長くするように促します。
if chars_cnt < lower_tolerance_limit:
improve_chars_cnt_prompt = f"**The summary still has {ideal_chars_cnt-chars_cnt} characters to spare. Make the text a little longer.**"
# 要約の文字数が許容範囲を超えている場合、テキストを少し短くするように促します。
elif chars_cnt > upper_tolerance_limit:
improve_chars_cnt_prompt = f"**The summary is {chars_cnt - ideal_chars_cnt} characters over. Make the text a little shorter**"
# 要約の文字数が許容範囲内の場合、ループを終了します。
else:
break
# 改善を求めるプロンプトを生成します。
improvements_prompt = "Please improve.\n" + improve_chars_cnt_prompt
# メッセージリストにアシスタントとユーザーからのメッセージを追加します。
messages.append({"role": "assistant", "content": summary})
messages.append({"role": "user", "content": improvements_prompt})
# 改善された要約を生成します。
completion = client.chat.completions.create(
model=model,
messages=messages,
)
summary = completion.choices[0].message.content
# 改善された要約の文字数を計算します。
chars_cnt = len(summary)
# 最終的な要約を返します。
return summary
# 訓練データと検証データのサイズ
TRAIN_DATA_NUM = 500
TEST_DATA_NUM = 50
ALL_DATA_NUM = TRAIN_DATA_NUM + TEST_DATA_NUM
# 使用するモデル名(ファインチューニング済みのモデル
MODEL_NAME = "ft:gpt-3.5-turbo-1106:id::finetune"
# 要約文字数
IDEAL_CHARS_CNT = 100
# 許容誤差
TOLERANCE = 0.05
# フォルダの中からランダムにtxtファイルを読み込み
news_texts = read_random_txt_files("./text", ALL_DATA_NUM)
# 訓練データを生成
dataset = []
for nt in tqdm(news_texts):
for _ in range(5):
summary = summarize(nt, IDEAL_CHARS_CNT, TOLERANCE, MODEL_NAME, 5)
if len(summary) > IDEAL_CHARS_CNT * (1 - TOLERANCE) and len(summary) < IDEAL_CHARS_CNT * (1 + TOLERANCE):
break
# 訓練データ作成
system_prompt = create_summarize_system_prompt(IDEAL_CHARS_CNT)
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": nt},
]
# 訓練データに追加
dataset.append({"messages": messages + [{"role": "assistant", "content": summary}]})
# 訓練データと検証データに分割
train_dataset = dataset[:TRAIN_DATA_NUM]
test_dataset = dataset[TRAIN_DATA_NUM:]
# ファインチューニングを行うためのフォーマットで出力
with open("train_dataset_100char.jsonl", "w") as f:
f.write("\n".join([json.dumps(td) for td in train_dataset]))
with open("test_dataset_100char.jsonl", "w") as f:
f.write("\n".join([json.dumps(td) for td in test_dataset]))上記を実行して出力されるtrain_dataset_100char.jsonlとtest_dataset_100char.jsonlを訓練データとテストデータとして使用します。
ちなみに訓練データだけでもファインチューニングは問題なく可能です。
GPTの利用料が気になる方はコードを修正してください。
3. ファインチューニング
APIを使って行うことも可能ですが、今回はOpenAIのダッシュボードから行います。
前回の記事を読んでいる方はこの章は飛ばして大丈夫です。
まず、ファインチューンダッシュボードに移動し、右上の「+ Create」を選択してください。
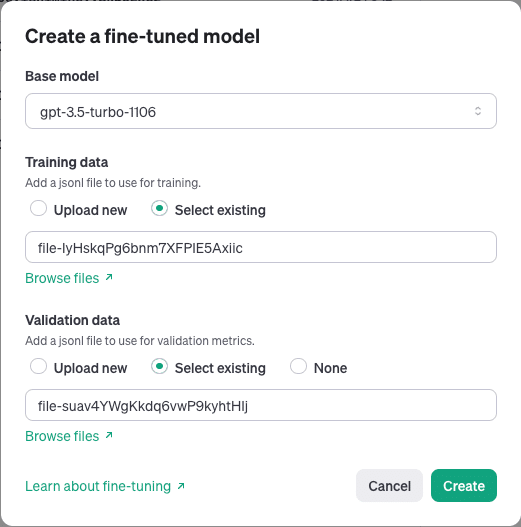
次に以下のように設定します。
Base model : gpt-3.5-turbo-1106
Training data : train_dataset_100char.jsonl
Validation data : test_dataset_100char.jsonl
あとはCreateを選択し、10分ほど待てばモデルが作成されます。
このとき、Validation lossを確認して、値が悪ければ再度実行すると良いです。
同じデータを使用しても、モデルの性能に差が出る時があります。
Azure OpenAI Serviceのようにバッチサイズなどを調整できると良いのですが、その機能はまだ無いみたいです。
4. ファインチューニングしたモデルの検証
私の記事を使ってgpt4とfinetune-model(今回作成したモデル)を比較しました。
システムプロンプトは訓練時と同じものを使用しています。
=gpt4=
- GPT APIをシステムに組み込む際は単純なプロンプトを用いて、GPT4とGPT3.5-turboを使い分ける
- GPTには特殊なタスクだけを任せ、安定化のためにfunction_callingやJSONモードを活用する
- バッチ処理、チャット活用、及びファインチューニングを用いて効率を向上させる
147文字
=finetune-model=
- GPT APIを活用した業務システム開発の要点を整理
- 重要: 単一タスクのシンプルなプロンプト、GPT3.5/GPT4の適切利用
- 安定性強化のためのfunction_calling/JSONモード活用、チャット導入
106文字=gpt4=
- ファインチューニングでGPT-3.5の性能向上
- GPT-4並みの精度、コスト大幅削減
- 短時間で試せる方法を解説
56文字
=finetune-model=
- GPT3.5をファインチューニングし、gpt-4並の高速・低コストモデル構築
- Pythonスキル、OpenAIアカウントのみ必要、実践的手順
- livedoorデータ活用した手順詳細、精度とコストの飛躍的改善を実証
107文字たまたまかもしれないので、訓練に使用していないlivedoor ニュースコーパスのデータ100個を用いて性能を検証してみます。
$$
\begin{array}{|l|c|c|c|c|c|c|}
\hline
\textbf{モデル} & \textbf{文字数平均} & \textbf{文字数中央値} & \textbf{文字数最小} & \textbf{文字数最大} & \textbf{文字数の分散} & \textbf{処理時間平均} \\ \hline
\text{GPT-4} & 92.4 & 94.5 & 59 & 129 & 10.9 & 20.9\text{秒} \\ \hline
\text{ファインチューニングモデル} & 98.4 & 98 & 63 & 128 & 8.8 & 6.1\text{秒} \\ \hline
\end{array}
$$
上記から、すべての値でGPT4よりもファインチューニングモデルの方が優っていることが確認できます。
まとめ
前回よりさらに実践的なファインチューニングの方法をまとめました。
ファインチューニングは高品質なデータを大量に集めることで、GPT4以上の性能を持たせることができるようになります。
要点をまとめると以下の通りです。
時間やコストをかけてもいいから、高品質な訓練データを用意する
大量のデータを用意する(目安500~)
ファインチューニング済みモデルを使ってコストを抑える
精度・コスト・速度の問題をいっぺんに解決できる可能性がある手法なので、ぜひ試してください。
また、以下の記事も一緒に読むとさらに効果的です。
この記事が気に入ったらサポートをしてみませんか?