
分散不均一性Heteroscedasticity

ここでは、計量経済学で大切な仮定の1つ、等分散性Homoscedasticityと分散不均一性Heteroscedasticity(もしくは不等分散性)について見ていきましょう。
等分散性はOLSにおいて3番目の仮定でした。計量経済学では、まず仮定がそれぞれ満たされているか、をチェックし、それが満たされていない場合、それに対応する方法を行っていき、最終的に正しい因果を導きだすをいう流れで行います。
よって、OLSを利用する場合にはその3つの仮定(前の記事参照)をどうチェックし、満たさない場合どう対応するかを知る必要があります。
ここでは、等分散性の定義と効果、いつそれが満たされないかを見た後、それのチェック法と対応をまとめています。
Def:
The variance of error term u conditional on the explanatory variances is a constant.
(or The variance of error term u is uncorrelated with each xj)

定義:誤差項のxの条件つき分散が一定値。誤差項の分散がxと関連していない。
解説:一定値というのは、変化がないということ。つまり、xによって誤差項に変化が起こらないという意味。また、ここには誤差項同士に共分散がないので、誤差項同士で関連性がないということも含む。
Effect:
The estimator become efficient.
If OLS1-3 hold, OLS become best unbiased estimator.
効果:推定器が効率的になる。また、OLS1-3が成り立つとき、OLSが最良な不偏推定器になる。
If vaolated, std erro & t stat has no meaning.
また、成り立たないときは標準誤差やt値が正しく読み取れない。ただし、共変量coefに影響はない。
Violation:
Different (groups of) observations have different residual variances in the model
If different subgroup of variable X have different variation in Y.
異なるサブグループの観察対象が異なる誤差項の分散を持つ。
Autocorrelation(if there is time dimention)
また、Autocorrelationも誤差項の分散に影響を及ぼします。これは時間データがある場合に限りますが、もし時間データがある場合、前の期と次の期でyが関係する場合は誤差項の分散に関連が起こる場合があります。このとき、誤差項の共分散は0でなくなるので、共分散性は成り立ちません。
Cross-section data(一次元データ)ではこの問題はよく起こります。
Example:
Ex1: wages of men have higher variation than wages of women.
例としては、男女の変数があり給与との関係を知りたいとき、男女で給与の分散は違うと思います。(おそらく女性は給与=0が多く、男の方が大きい)この時、homoscedasticityが満たされない可能性があるでしょう。
Ex2. People with higher income have higher variation in their saving.
また、給与と貯蓄の関係を見たとき、給料が高い人の方が貯蓄の額の分散は大きいかもしれません。(その傾向があるといわれる)
上記のような例はグラフからみるとわかりやすいです。
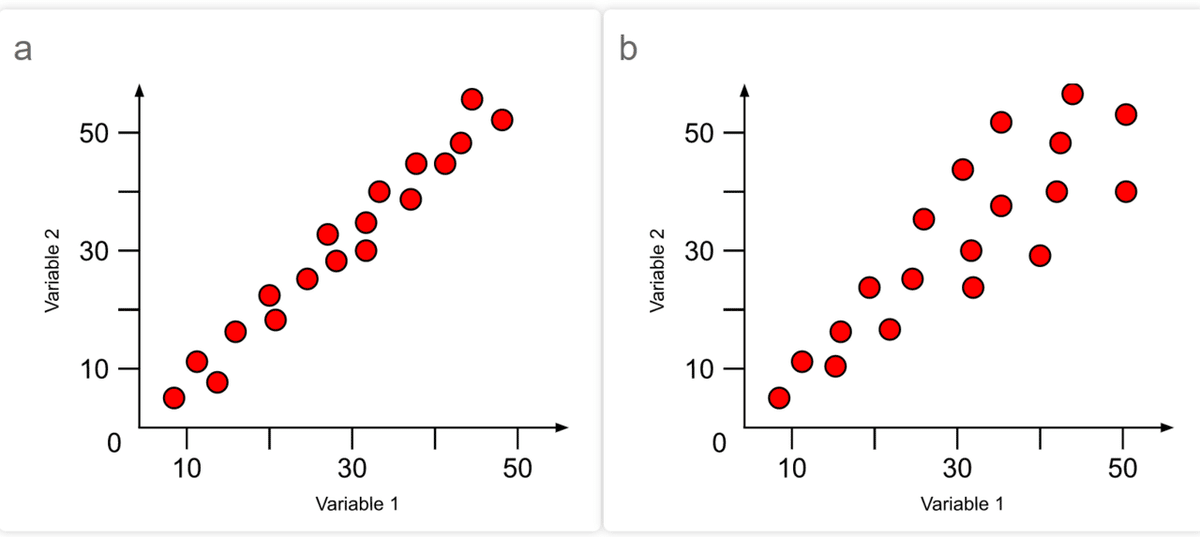
以下の絵で、aはhomoscedastic, b は heteroscedasticです。
aはVariable1の値が変わってもすべて似たようなライン上の値で、分散は変わりませんが、bではVariable2が大きくなるにつれて、ラインから離れた値を取りやすくなっており、分散は増えていますね。
図1
Test: White test
OLSを行ったら、まず仮説があっているかの検証をします。このテストはその検証で行うものです。
簡単なheteroscedasticityのテストはWhite testです。
このテストでは、上記のdefで話した誤差項の分散が一定値かどうかをテストします。帰無仮説をHomoskedastic(誤差項の分散が一定値)とし、p値が基準値よりならsignificant有意としてreject棄却します。
コマンドは、Stataだと
Regress y x
をした後に、以下のコマンドをたたきます。
estat imtest, white
ちなみに、White testは1980年にホワイトが作ったものらしいです。他にもいくつかテスト手法はあります。
Solution:
もし上記のテストを行い棄却された場合、それを考慮した分析に変えることができます。1つ目の方法はrobust std errorというもの、2つ目の方法はGLSというものです。
Solution1: x Vce(robust)
これはWhite robust standard error といわれます。ロバストというのは、頑丈性、という意味で、ここでは特に分散不均一に頑丈な標準誤差、およびそのような計算を行うことで分散不均一に対応する、ということを示します。
これによって不均一がなくなるわけではないのですが、少なくとも標準誤差、t値は正しく読み取れるようになります。
コマンドでは(stata)、以下の通りです。
regress x y, robust
ちなみに、パネルデータの場合には、個体ごとにクラスター(集合)をとります。これにより、より正確に標準誤差が計算できます。こちらは以下のようにコマンドします。
regress x y, cluster(id)
Solution2: GLS
GLSというのは、Generalized Least Squareの略で、上記のrobustよりさらに強力な不均一分散への方法です。ここでは、ただstandard errorを不均一に対応させるのではなく、そもそもerror termを均一分散になるように式の変形をすることで、不均一分散に対応しよう、という考えになります。
GLS gives best estimator under heteroskedasticity.
このGLSを使うことで、誤差項は仮定3を満たすことになります。robustの際にはただ標準誤差を変えているだけなので、仮定3は満たされておらず、OLSの性質BLUE(the Best Linear Unbiased Estimator)ではなくなっていました。つまり、efficientではなかったということです。しかし、GLSではこれを満たすことができます。
Summary:
ここでは仮定の1つ不均一分散性をまとめていきました。
均一分散というのは、計量経済学においてただ計算を簡単にするだけにとどまらず、有意性を示すためにとても重要な仮定です。
もし不均一分散が疑われる場合にはまずテストをし、もし棄却なら上記で示したrobustかGLSを用いてそれに対応することで有意性を示すことができるようになります。
参照:図1 https://sites.google.com/site/mb3gustame/warnings/warning-heteroscedasticity
この記事が気に入ったらサポートをしてみませんか?