
OCRについて その1

こんにちは!ボンズ企画の編集部員です!
前回はスキャナーについて5回に分けてご紹介しましたが、今回はボンズ企画の電子化事業における、OCRについてお話します。
このOCRも2回に分けてお話していきたいと思います。
まず1回目はOCRとは何なのか簡単な説明と、活用方法についてです。
2回目では、弊社で使用しているOCRソフトについてです。
そもそもOCRとは何かご存じでしょうか?
(私はこの電子化という仕事をするまでは、全く知りませんでした…)
まずは名前についてお話します。
OCRとは「Optical Character Recognition」の頭文字をとった略称で「オー・シー・アール」と読み、日本語で言うと「光学文字認識」のことです。
どのようなものかといいますと、印刷された文字や手書きの文字などをスキャナーやカメラで読み取り、コンピューターが利用できる文字データに変換する技術のことです。
(※弊社では、まだ手書き文字のOCRは対応しておりません)
読み取った文字データは、テキストとしてコピー&ペーストすることも可能ですし、キーワードでの検索も可能になります。
簡単ですが、画像でOCRを付けたPDFの活用方法について説明します。
テキストのコピー&ペースト





ワード検索
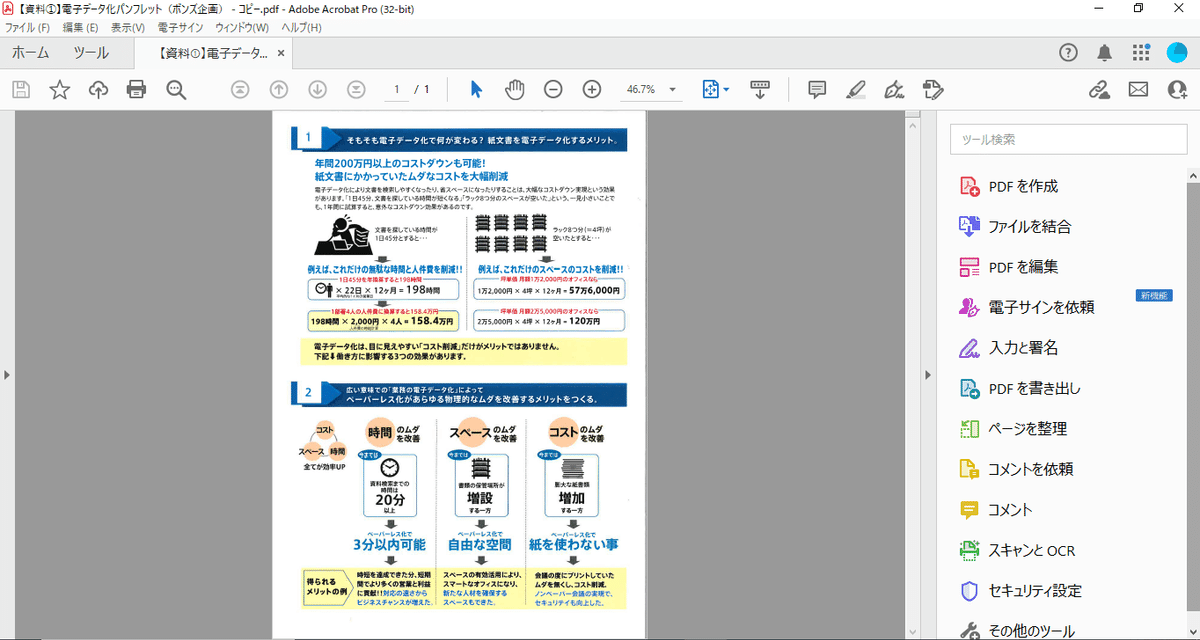
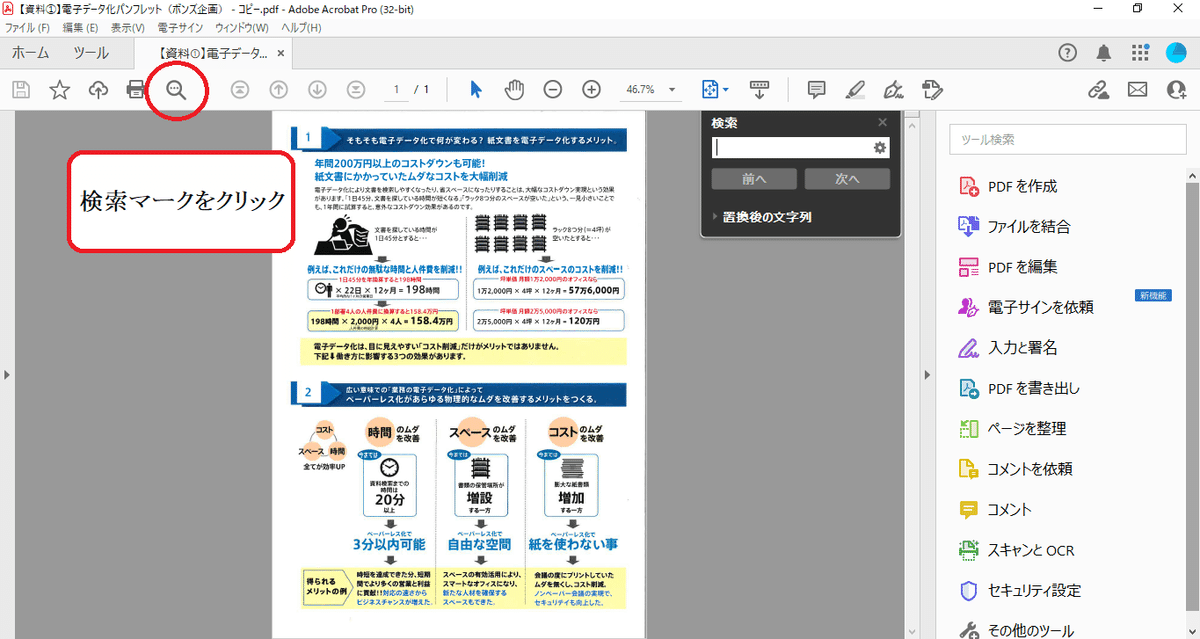

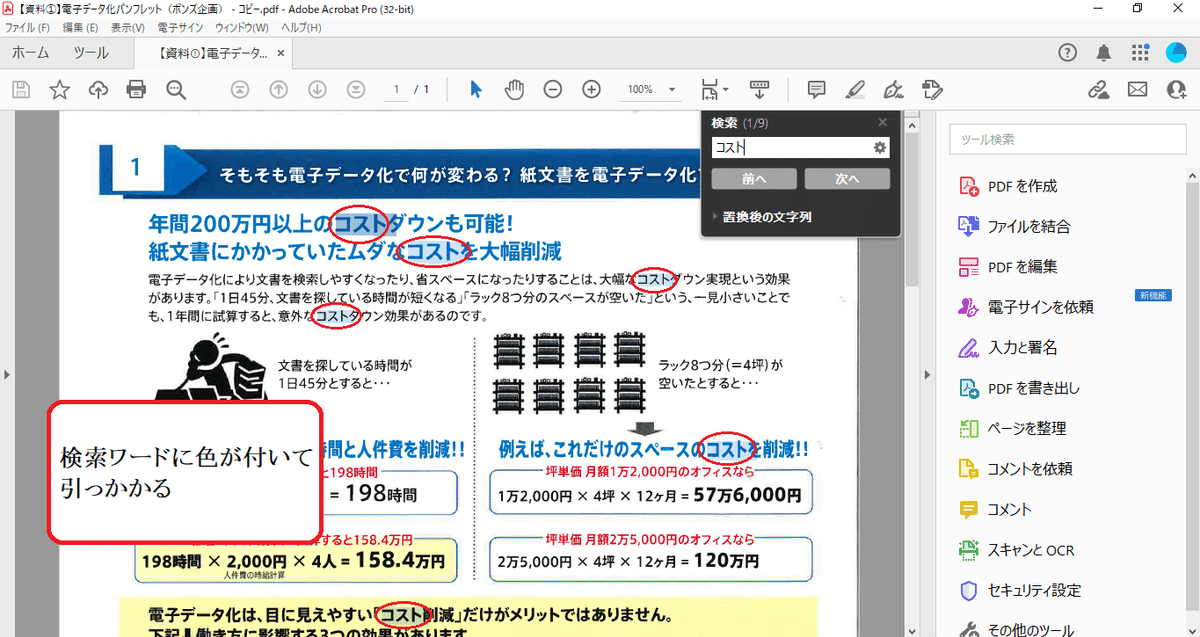
キーワード検索ができれば、データの中から自分の知りたい・探している情報がどこのデータにあるのか、すぐに分かるようになります!
いくらDXやペーパーレスといって紙資料をPDF化しても、大量のデータから必要なデータを探すのに時間がかかっては、効率化という面では紙資料とあまり変わらないのではないでしょうか。
このように、ただのPDFデータではなく、OCRを付けることで活用しやすいデータになり、効率アップにつながります!
なんとなくはOCRについて分かりましたでしょうか?
今回はここまでとなります。
次回、複数あるOCRソフトの中でも、弊社で実際に使用しているOCRソフトについてご紹介していきます!
この記事が気に入ったらサポートをしてみませんか?