フォルダに保存されているExcelファイルを統合(+不要な行を削除・行ラベルを任意のものに変更)

やりたいこと
あるフォルダに保存されているすべてのワークブックのデータを統合する。


データの加工
データを統合するにはデータを加工する必要がある。
やることは2つ
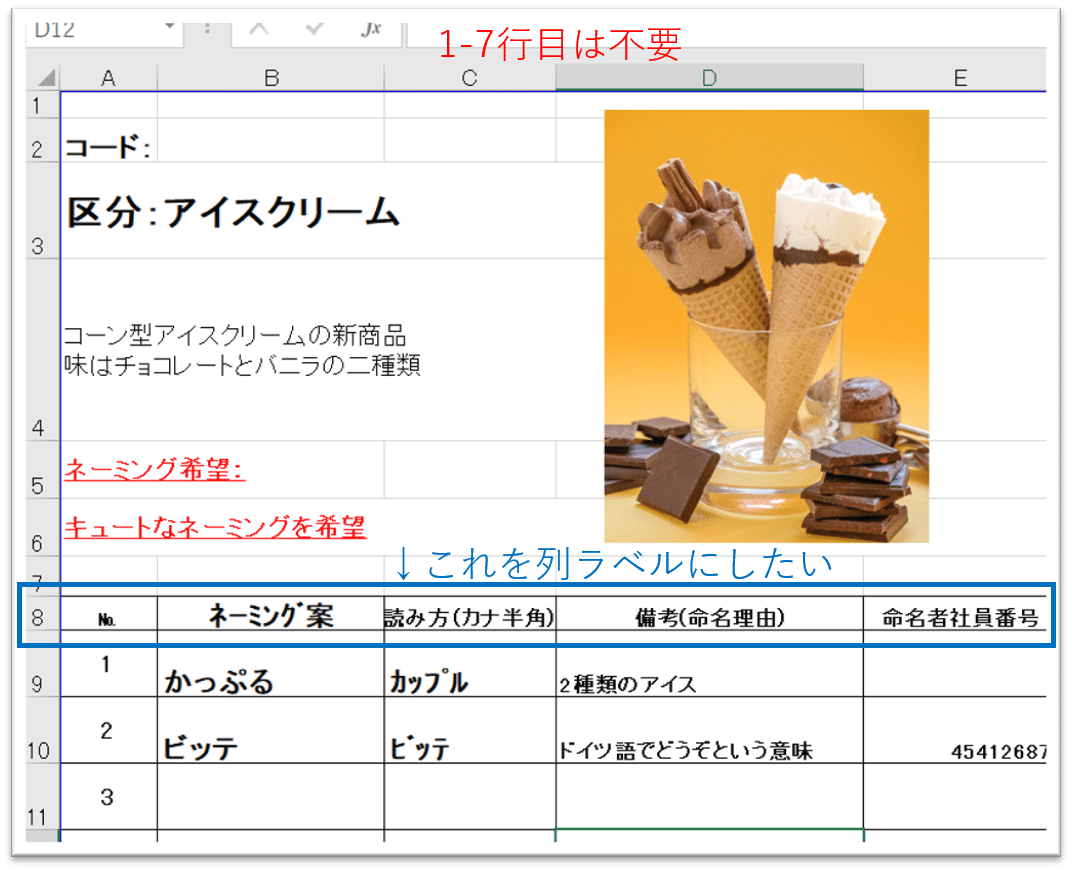
1. 不要列の削除 (1-7行目)
2. 列ラベルの変更(デフォルトだとuntitledになった)
使用したライブラリ
import openpyxl as excel # エクセルを扱う
import pandas as pd # データフレームを扱う
import numpy as np # numpy関数を使えるようにする(今回はなくてもできたかも)
import glob # データの結合globを使って、フォルダに入っているすべてのエクセルを取得。
files = glob.glob("excels/*.xlsx")
print(files)空の配列を用意し、繰り返し処理によって各エクセルファイルのデータをデータフレームにしていく。不要なデータを削除。
data_list = []
for file in files:
df = pd.read_excel(file, sheet_name='アイス')
df.columns = ["No.","ネーミング案","読み方(カナ半角)","備考(命名理由)","命名者社員番号"]
droped_df = df.drop([0,1,2,3,4,5,6])
com_df = droped_df.dropna(how='any')
data_list.append(com_df)
con_droped_df = pd.concat(data_list)
con_droped_df.to_excel("アイス新商品.xlsx")完成形

使用したメソッド/関数の解説
df = pd.read_excel(file, sheet_name='アイス')
# pd.read_excel: エクセルデータをデータフレームに変換、シート名も指定可能
df(変数1).columns = ["行ラベル名"]
# column: 行ラベルを任意のものに変更
droped_df(変数2) = df(変数1).drop([0,1,2,3,4,5,6])
# drop: 指定した行を削除
com_df = droped_df.dropna(how='any')
# dropna(how='any'): 空白行を削除
data_list.append(com_df)
# データを配列に追加
con_droped_df = pd.concat(data_list)
# concat:データ同士を結合
con_droped_df.to_excel("アイス新商品.xlsx")
# .to_excel("シート名.xlsx"): データフレーム➡エクセルに変換参考にしたページ
pandasで欠損値NaNを除外
https://note.nkmk.me/python-pandas-nan-dropna-fillna/
Pythonで一つのフォルダ内にあるExcelファイルを連続処理
https://teratail.com/questions/89443
Pandasで指定した行・列を削除するdrop関数の使い方
https://deepage.net/features/pandas-drop.html (編集済み)