
ComfyUI-LCMによるVid2Vidの高速変換を試す(Latent Consistency Models)

Latent Consistency Models(LCM)は、最小限のステップ数で迅速に推論できる新たな画像生成モデルです。
例えば768x768の画像が2~4ステップ程度で生成できるとのこと(Stable Diffusionだとざっくり20ステップくらい)。

このLCMをComfy UIの拡張機能として実装したのが「ComfyUI-LCM」です。
Comfy UI-LCMを使ったVid2Vidの動画変換ワークフローが紹介されていたので、試してみました(ControlNetやAnimateDiffを使わない古典的なVid2Vidです)。
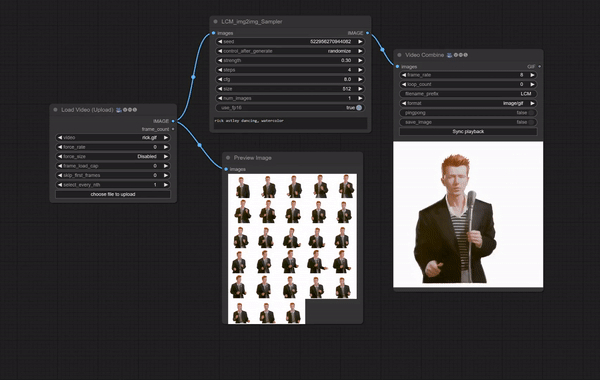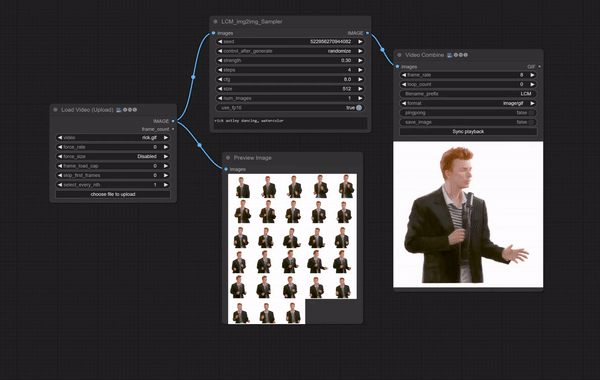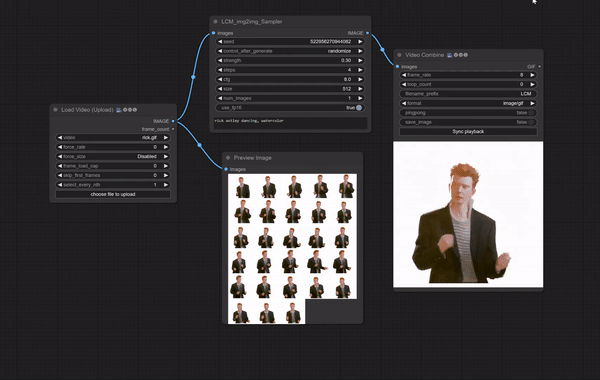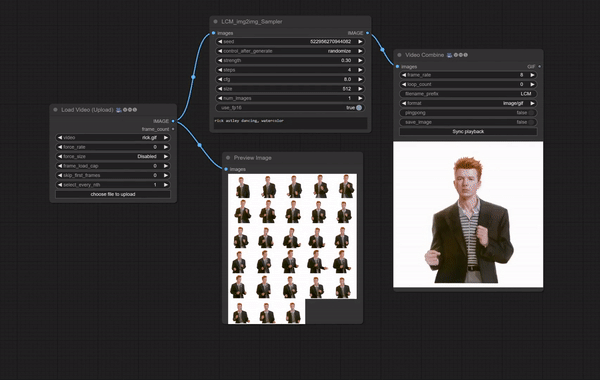
必要な準備
ComfyUI本体の導入方法については、こちらなどをご参照ください。
今回の作業でComfyUIに追加したものは以下の通りです。
1. カスタムノード
カスタムノードには次の2つを使いました。
ComfyUI-LCM(LCM拡張機能)
ComfyUI-VideoHelperSuite(動画関連の補助ツール)
ComfyUI Managerを使っている場合は、いずれもManager経由で検索しインストールできます(参考:カスタムノードの追加)。
2. 画像生成モデル
ComfyUI-LCMを含むワークフローを実行するとモデルが自動でダウンロードされたので、事前のダウンロードは不要でした。
なお現時点では、StableDiffusion1.5系のモデルであるDreamshaper_v7のLCM版「LCM_Dreamshaper_v7」しか対応モデルがないので、これがダウンロードされます。
ワークフロー
「ComfyUI-LCM」のGithubに掲載されているImg2Img / Vid2Vidのワークフローをそのまま使用しています。

元動画には、VRoidStudioでつくったアニメ調3Dモデルの動画を使いました。これを洋画(油絵)調に変換してみます。
アウトプット
Google Colabの標準GPU(VRAM 16GB)で試したところ、512x512サイズの120フレームの動画変換で1分弱。1024x1024サイズの120フレームの動画変換だと12-13分ほどでした。
*ComfyUI-LCMによるVid2Vidの高速変換を試す(Latent Consistency Models)https://t.co/PcMgEKbPfn #comfyui #aiart pic.twitter.com/x3LIYnfbaX
— Baku (@bk_sakurai) October 24, 2023
以前に標準GPU+StableDiffusion(WebUI)で同様のVid2Vid変換を試したときは1時間をゆうに超えたので、それよりも格段に速いです。
今後、ControlNetやAnimateDiffのようなツールと併用できるようになれば、長めの動画を手軽にAI変換できるようになりそうです。
関連記事
ComfyUI AnimateDiffについての記事は、以下のnoteにまとめています。