
Macで簡単 AI画像生成(未経験者向け)

まえがき
本記事は、未経験者向けにMacOSのアプリケーションソフトで簡単にAI画像を生成する方法を解説します。
ちょっと補足:画像生成スピードが気になる方もいらっしゃると思いますが、
私が使っているMacBook Air M2 8G RAMだと512x512の1画像が20ステップで15〜20秒、速くもなく、遅くもなく、私はストレスなく画像生成できています。Macで生成された画像を見てみたい方は、私のTwitterアカウントを確認してみてください。
歴史の流れ:2022年8月にStable Diffusionがオープンソースで公開されて、PCでのAI画像生成が盛り上がってきた頃の2022年12月にAppleから突然!Stable Diffusionを機械学習フレームワーク(CoreML)で利用できるようにするよ!という発表があって、MacOS, iOS / iPadOSからStable Diffusionを利用できるml-stable-diffusion(Core ML Stable Diffusion)というツールが公開されました。その後、MacOSやiOS/ iPadOSでStable Diffusionを使えるアプリケーションソフトの開発が盛んになりつつあります。
MacOSアプリについて
2022年12月の発表から、現在(2023年2月)までに色々なアプリケーションソフトが誕生していますが、私が使ったことのある3つを紹介します。
Swift Core ML Diffusers
Core ML Stable Diffusionを開発しているPedro Cuencaさんが作った純正アプリと言えるDiffusersです。販売元はStable Diffusionなどのツールなどを開発しているHugging Face, Incです。今の所一握りの(数少ない)モデルの利用しかできませんが、App Storeで無料配布されているので、気軽に試してみたい方にはお勧めです。動作条件は macOS 13.1 Ventura以上, Apple Silicon Macが必要です。
PromptToImage
開発中のソフトをベータテストするTestFlightで公開されています。これはAppStoreからTestFlightというアプリをダウンロードして、このアプリからインストールできます。モデルは限定されますがImage2Image(画像を元に画像を生成する)機能を持っています。動作条件は macOS 13.1 Ventura以上, Apple Silicon Macが必要です。Text2Imageであれば一応モデルの変更はできます。
Mochi Diffusion
ml-stable-diffusion(Core ML Stable Diffusion)はmacOS 13.1 Venturaでないと本領を発揮しないとのことで、macOS 13.1 Venturaの正式アップデートが配布される2022年12月13日までお預け状態でした。正式アップデートが配布されて、しばらくPythonで画像生成していましたが、やはりめんどくさいので、誰かSwiftのMacOSアプリを開発してないかな?と探して見つけたアプリがMochi Diffusionです。当時から現在も積極的にアップデートされ Intel Macにも対応して、かなり使い勝手も良くなっています。動作条件は macOS 13.1 Ventura以上, Apple Silicon Mac または 高性能GPUを備えたIntel Macが必要です。モデルの変更は自由自在です。(2023/05/02追記:Mochi Diffusion v3.2からIntel Macでは動作しなくなりました。)
モデルについて
Stable Diffusionモデル
Stable Diffusionでテキストから画像を生成(Text2Image)する場合には、学習済みのモデルが必要になります。学習済みモデルはHugging Faceがサーバーで公開しており、自分で学習させたモデルをHugging Faceのサーバで公開することもできます。また、画像を生成したい人は、このサーバーから学習済みのモデルの情報を取得して利用できます。
サーバで公開されているモデルにはscheduler, safety_checker, text_encoder, tokenizer, unet, vae の5つが含まれています。unetとvaeを一つのファイルにした.ckptファイルのみ配布されていることも多いです。.ckptは高性能GPUを搭載したPCで画像生成するために使われるソフトウェア(AUTOMATIC1111/stable-diffusion-webuiなど)で利用されています。
ml-stable-diffusion(Core ML Stable Diffusion)ではStable Diffusionモデルのsafety_checker, text_encoder, tokenizer, unet, vaeのデータを利用します。従って、.ckptファイルのみ配布しているモデルを利用することは、できないことは無いですが難易度が高くなります。
Core MLモデル
ml-stable-diffusion(Core ML Stable Diffusion)を使うには、Stable Diffusionモデルからデータを取得してAppleの機械学習フレームワークCore ML用へ変換したCore MLモデルが必要です。変換方法はml-stable-diffusionに解説がありますが、変換にターミナルを使わなければなりません。ターミナルを使ったことがないような方々は、このモデル変換が最大の難関です。そこで、Core ML Stable DiffusionのMacOSアプリを使っている有志の方々が、MacOS用の変換済みモデルをHugging FaceのCore ML Models Communityで配布しています。
画像の生成方法(Text2Image)
Mochi Diffusionのインストール
私が古くから使っているMochi Diffusionを使って説明します。まず、Mochi Diffusionの配布先のリンクから最新版をダウンロードします。ダウンロードされた.dmgファイルを開いて、Mochi Diffusionをアプリケーションフォルダにドラッグ&ドロップすればインストール完了です。
アプリケーションフォルダのMochi Diffusionを開くと、まず、「ダウンロードされたアプリですが、信用して使いますか?」のようなダイアログが出ますので、OKボタンで同意してください。その後、Mochi Diffusionが利用するモデルの保存先をたずねられると思いますので、とりあえずデフォルトでOKしてください。おそらく、モデルフォルダは以下のような配置になっていると思います。○○○○はあなたのPCでのアカウント名になります。
/Users/○○○○/Documents/MochiDiffusion/models/
(これは、2ヶ月前位に私が始めて使った時の記憶を元に書いているので、もしかすると、現在は変わっているかもしれません。modelsフォルダはMochi Diffusionの設定で自由に変更できます。)
Core MLモデルのインストール
先ほどのCore ML Models Communityから、
まずは無難なcoreml-community/coreml-stable-diffusion-v1-5をダウンロードしましょう。
このページの上にタブがありますので、「Files & versions」タブをクリックしてファイル一覧が見れるmainページへ移動します。(直リンクも下におきます)
https://huggingface.co/coreml-community/coreml-stable-diffusion-v1-5
この中に「split_einsum」というフォルダがありますので、それをクリックして中に入ります。(直リンクも下におきます)
https://huggingface.co/coreml-community/coreml-stable-diffusion-v1-5/tree/main/split_einsum
移動したページにv1-5_split-einsum.zipというファイルがありますので、これをクリックするとページが変わって
「This file is stored with Git LFS . It is too big to display, but you can still download it.」という文章が出てきます。この文章のdownloadをクリックするとモデルがダウンロードされます。(直リンクも下におきます)https://huggingface.co/coreml-community/coreml-stable-diffusion-v1-5/blob/main/split-einsum/v1-5_split-einsum.zip
.zipファイルがダウンロードされたら、ダブルクリックして解凍します。解凍された「v1-5_split-einsum」フォルダを上記で指定したMochi DiffusionのModelsフォルダへ移動します。これでCoreMLモデルのインストールは完了です。
Mochi Diffusionでの画像生成
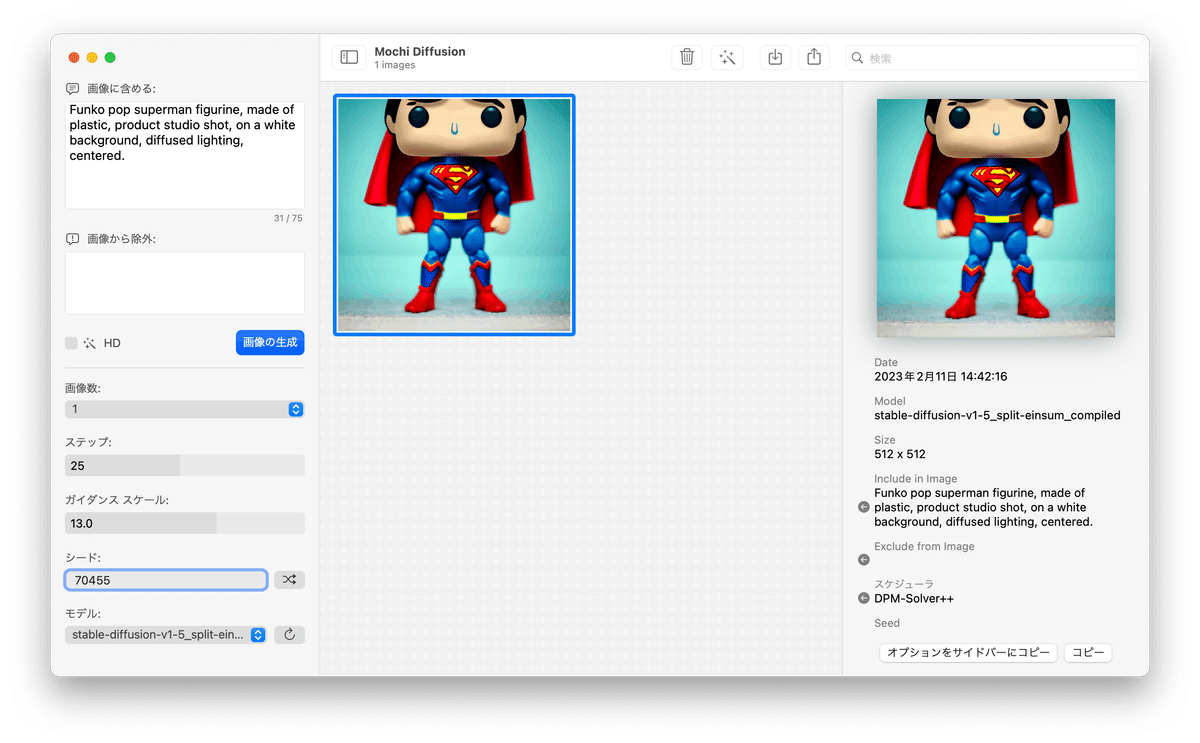
Mochi Diffusionを起動すると、下図のようなウインドウが開きます。左は設定パネル、中央は生成された画像一覧を表示するスペース、右は生成された画像一覧の画像を選択すると画像の情報が表示されるスペースです。

左の設定パネルは上から
・画像に含める(Propmpt)を入力するテキストボックス
・画像に含めない(Negative Prompt)を入力するテキストボックス
・高解像度(HD)の生成を選択するチェックボックスと
画像の生成を実行するボタン
・一回の画像生成で生成する画像の枚数を選択するセレクタ
・一枚の画像の生成で演算するステップ数を指定するスライダ
・画像に含める言葉、含めない言葉にどれだけ従うかの尺度
(ガイダンス スケール)を指定するスライダ
・シードの値を入力するテキストボックスと、シードをランダムに設定するボタン
・モデルフォルダにあるモデルを選択するセレクタとモデルフォルダの更新ボタン
(起動中にモデルを入れ替えた場合に更新するためのボタン)
です。
画像に含める(Prompt)と画像に含めない(Negative Prompt)には英文や英単語を入力なければなりません。入力した文字列の初めの方が画像に与える影響力が強く後ろの方になるにつれて弱くなります。初めての場合は何を入れて良いか分からないと思いますので。OpenAIのPromptBookの例文を使ってみると良いと思います。PDFなのでコピー&ペーストできます。
例えば、OpenAIのPromptBookの8ページの例を入力して画像の生成ボタンを押すと、しばらくして(最初はモデルのロードのため長めに数分かかりますが、2枚目以降は速くなります。)以下のようにサイズが512x512の画像が生成されます。8ページの例とはちょっと違いますね。使われているハードとソフトが異なるので、全く同じ画像は生成できません。そこで自分の好みの画像が生成されるようにPromptやステップ数、ガイダンス スケール、シードを変えて調整しましょう。
”生成した画像はMochi Diffusionを終了すると全て消去されますので、気に入った画像が生成された場合は、中央の一覧で選択してファイルメニューか右クリックメニューの「別名で保存」で保存しましょう。 Mochi Diffusion v2.5から生成した画像はmodelsフォルダと同じ場所に作成されるimagesフォルダに保存されるようになりました(場所は設定から変更可能)。起動時はimagesフォルダの画像が中央の一覧へ表示されます。また、右クリックメニューの消去は画像をゴミ箱へ移動するようになりました。” Mochi Diffusion v2.2以降で生成した画像ファイルであれば、ファイルメニューの「画像のインポート」で中央の一覧へ戻すことができます。
高解像度HDオプションは、元の画像を縦横4倍に変換します。左の設定パネルにある高解像度(HD)を選択するチェックボックスをオンにすれば初めから高解像度(HD)のファイルが生成されます。生成済みの画像選択して高解像度(HD)変換することもできます。なお、高解像度(HD)の画像はファイルサイズが多いのでご注意ください。他の画像の設定を再利用したい場合は、中央の一覧で設定を利用したい画像を選択して、右の情報表示スペース下にある「オプションをサイドバーにコピー」ボタンを押すとその画像の設定が左のパネルに反映されます。
以上で、基本的な使い方の解説はおわりです。
慣れてきたら、他のモデルを試したり、Promptに使える良さそうな呪文を探索してみてください。
注意点など補足
メモリ使用量の削減
私のようにメモリが少ない機種を使っている方は、設定ダイアログ「一般」で、メモリ使用量の削減をオンにしましょう。これは画像生成していない時のメモリの使用量を減らします。

ML Compute Unit(Intel Mac要注意)
Intel MacはNE(Neural Engine)を備えていませんので、設定ダイアログ「画像」の「ML Compute Unit」で「CPU & GPU」を必ず選んでください。M1, M2はCPU & GPU & NEを使う「全て」と「CPU & GPU」と「CPU & Neural Engine」が選べます。NEを使うと本記事のタイトル画のように"ふわっ"とした画像が生成される傾向があって、NEを使わないと"カチッ"とした線になる傾向があります。M1, M2 Macの注意点としては、Core ML Models Communityからダウンロードしたモデルの名前に"ORIGINAL"を含んだモデルは「CPU & GPU」の設定でないと画像が生成されません。スケジューラは変更する必要はないですが興味があれば変更して試しても大丈夫ですし、お好み次第です。

Promptの制限
ml-stable-diffusion(Core ML Stable Diffusion)は画像に含める言葉(Prompt)と画像に含めない言葉(Negative Prompt)に()や[]による強弱や75を超えるトークンは使えません。(現在使っているトークン数はテキストボックスの右下に薄く表示されています。)残念ながら今話題のAI画像生成呪文などで、これらを使った長い呪文での画像生成はできませんが、試行錯誤次第で色々な画像生成を楽しめますのでお試しください。
おわり
※ 現在、モデル名やモデルフォルダのパスに非ASCII文字が含まれていると、NEを使った画像生成が非常に遅くなるそうです。ご注意ください。(2023/02/27)
※ Mochi Diffusion v3.0がリリースされました!
画像から画像を生成する i2i(Image To Imege)機能が搭載されています。i2iを使うには対応したモデルが必要です。Core ML Models Communityでは、i2iを使えないモデルのzipファイル名に「no-i2i」を追加しています。i2iを使いたい場合はzipファイル名に「no-i2i」を含まないモデルをダウンロードしてください。また、画質を保ったままでファイルサイズを大幅に減らすことができるHEICでの画像保存もできるようになりました!気軽にHD画像を保存できます。(2023/03/03🎎)
更新履歴
2023/02/23:リンク切れを修正
2023/02/26:Mochi Diffusion v2.5の更新内容を反映
2023/02/27:NEの注意事項を追加
2023/03/03:Mochi Diffusion v3.0の更新内容を追加
2023/05/02:Mochi Diffusion v.3.2からIntel Macでは動作しない件追加
2023/11/06:リンク切れの修正
この記事が気に入ったらサポートをしてみませんか?