論文解説 4M-21: An Any-to-Any Vision Modelfor Tens of Tasks and Modalities

Project Page : https://4m.epfl.ch/
arxiv : https://arxiv.org/abs/2406.09406
github : https://github.com/apple/ml-4m/
ひとことまとめ
任意の画像条件から任意の画像条件を作成できるAny to Anyモデル
概要
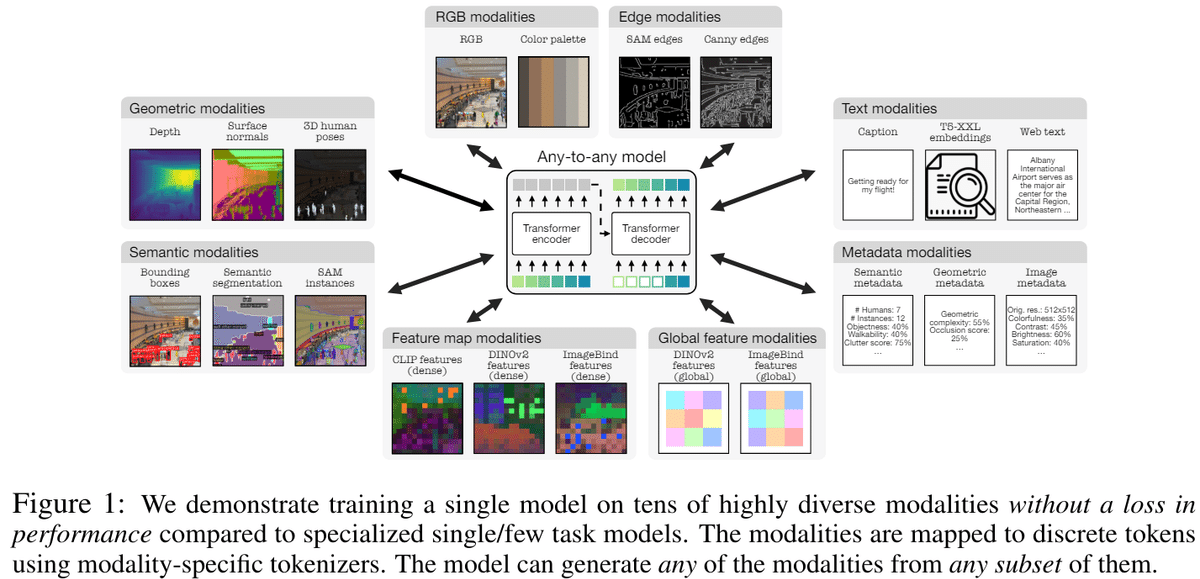
Any to Anyの研究は以前から行われていたが、使用されているモーダル数が少なく変換に制限があった。そこでSAMや4DHumansなどの疑似ラベルや画像のメタデータやカラーパレットなどのモダリティを追加した。既存のモデルよりも性能の低下なしに3倍多くのタスクやモダリティを解けることを示した
提案手法
提案手法は4M(https://arxiv.org/pdf/2312.06647) の事前学習手法をそのまま用いている。モデルの構造などの変更はせず、モダリティとデータ量を増やした

4Mは複数のモダリティを同時にMAE(Masked Auto Encoder)に近い手法で学習を行う。複数のモーダルの画像の一部をランダムに入力し、入力していない部分を予測する。
提案手法はこの入力データのモダリティと画像量を増やすことで性能を上げるとともに、汎用性を向上させた。

Tokenization

それぞれのモダリティは合計4つのtokenizerのどれかで処理が行われている。どのtokenizerを使うかはモダリティの性質に基づく。
VQVAE + Diffusion
画像の解像度が高い場合に使用する画像エンコーダで、RGB画像, normal, depthなどが該当する
VQVAE
画像の解像度が低いモデルの出力データに使用する画像エンコーダで、Segmentation, CLIP, DINOv2などが該当する
VQVAE MLP
DINOv2などのglobal token (画像全体の意味を1つのベクトルで表現したもの)の生成にはMLPを使用したVQVAEを用いる。また、このときの量子化手法はMemcodesという手法を用いる
Sequence Tokenizer
テキストやbounding boxなどの順序データをWordPieceという手法で離散値に圧縮する。
Dataset
CC12Mを事前学習に用い、その後COYO700Mでモデルを再訓練した。COYO700Mは4Mと同じ方法で疑似ラベルを作成した。ただし、新規で追加するSAMなどの疑似ラベリングコストが高いので、CC12Mのみ疑似ラベル付けを行い、COYO700Mを一定の割合で使用することで、新旧両方のモーダルを学習させた
実験
操作可能なマルチモーダル生成

提案手法は任意のモーダルから任意のモーダルを生成できるが、複数のモーダルを条件付けにしたり、細かな条件付けを行うことができる。特にmetadataでは人数や元の解像度など条件付けすることで品質の調整も行うことができる
マルチモーダル検索

提案手法は任意のモーダルからDINOv2やImageBindのglobal embeddingを予測することでマルチモーダルな画像検索を行うことができる。DINOv2やImageBindなど元のデータでは行えなかった別のモーダルの検索を行うことができ、また複数の条件付けを合わせた検索も行うことができる
Out-of-the-box vision tasks

提案手法は任意の画像処理をすぐに行うことができる。画像にあるように大量の異なるモーダルを1つのモデルで予測することができる。

提案手法の定量評価では、疑似ラベルや他のベースラインに一致またはそれを上回った。また、面法線推定とセマンティックセグメンテーションでは複数の出力をアンサンブルすることで性能が向上した。
これらの数値を見ると、UnifierdIOなどのマルチモーダル対応モデルと比べ性能が大幅に向上していることがわかる。
まとめ
大量のモダリティに対応するAny-to-Any Vision モデル4M-21を提案
多様なモダリティ間でのタスク処理と生成を実現した
これらのモダリティを離散トークンに変換し、統一的な表現空間で学習を行うことで、性能を損なわずに多くのタスクを処理できるモデルを構築
既存の単一/少数タスクモデルに匹敵する性能と新しいマルチモーダル生成・取得機能を単一モデルで達成した
この記事が気に入ったらサポートをしてみませんか?