論文解説 StarGAN v2

arxiv : https://arxiv.org/abs/1912.01865
github : https://github.com/clovaai/stargan-v2
ひとことまとめ
複数ドメイン間での画像変換 (男→女や犬→猫など)をきれいに行えるモデル

関連技術
Cycle GAN

複数のペアになっていない画像からドメイン間の変換を行うモデル
例えばシマウマ⇔ウマの変換であれば、シマウマの画像とウマの画像をそれぞれ同じくらいの量用意すれば学習ができる

モデルの学習自体の理論は単純で、ドメイン変換X→Yを行うモデルGと、ドメイン変換Y→Xを行うモデルの2つを用意して、それぞれのドメイン(例えばX) からもう一方のドメイン(Y)に変換し、再度元のドメイン(X)に変換したときに元のデータになるように学習すれば良い。
ドメインらしさは、そのドメイン固有のDiscriminatorで学習することでペア画像がない状態でもモデルを学習できる
StarGAN

Cycle GANはドメイン間のそれぞれの変換に対して別々のGeneratorを用意しなければならない。例えばN個のドメイン変換を行う場合モデルがN (N-1)個必要になるという問題がある。そこで、それを1つのモデルで代用したのがStarGANである
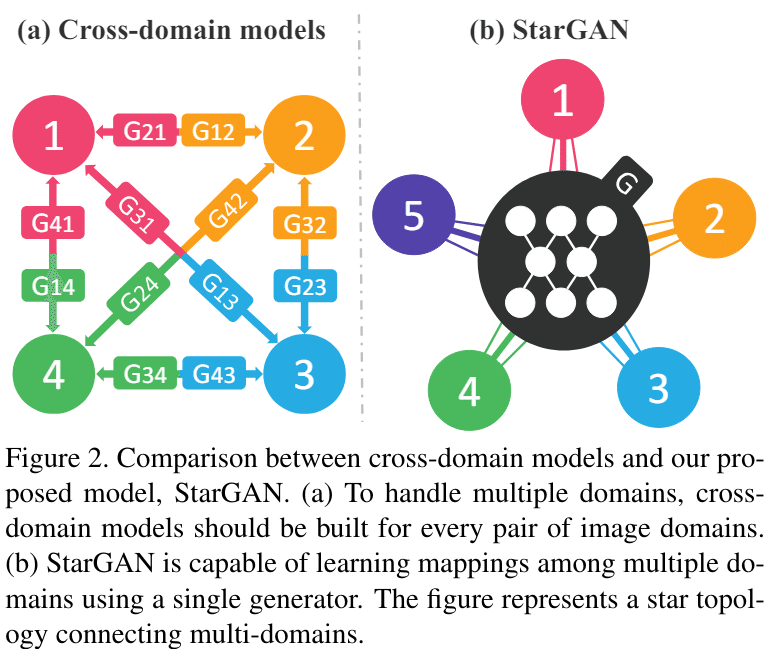
StarGANはドメイン情報をGeneratorに与えることで、任意のドメイン間の変換を行うことができる。

学習は基本的にはCycleGANと同様に、別ドメインに画像を変換後、もう一度正しいドメインに変換すると元の画像と同じになるはずという理論で行う
つまり、Cycle GANのGeneratorをモデルごと切り替えるか、入力に出力先のドメイン情報を加えるかの違いだけである
(厳密にはクラス分類損失が存在する)
StyleGAN
StyleGANは単純な画像生成のモデルであり、img2imgの手法とは関係がないが、StarGAN v2で用いられている手法なので追加で説明する

StyleGANはAdaIN(Adaptive Instance Normalization)とよばれる手法でGeneratorに乱数を与えることで非常にきれいな画像を生成することができる手法である(現在もDiffusion Transformerの条件付けなどで用いられる)

この構造にすることで、学習時に特定の画像しか出力しない問題(モード崩壊)が抑制され、比較的学習が安定する

また、StyleGANはノイズに対してmapping networkという長いFFNを通すことで、本来モデルにとって扱いづらい乱数を理想的な特徴量空間に変換することができ、安定的な生成や潜在変数の操作を行える
StarGAN v2の手法
StarGAN v2は簡単に言えばStarGANにStyleGANを足したようなモデルである

StarGANと同じように1つのGenerator, Discriminatorがあり、StyleGANと同じようにmapping networkを持つ。
また、画像からその画像のstyleを予測するStyle Encoderの4つのモデルで構成されている
Generatorを除く3つのモデルの出力はドメイン数だけ用意され、それぞれのドメインに対しての出力が作成される
損失関数
損失関数はStarGANと酷似しているが、いくつか違いがある。
(以下はGenerator目線での損失関数なので、真の画像を入れた時になるべく0を出力するような損失になっている)
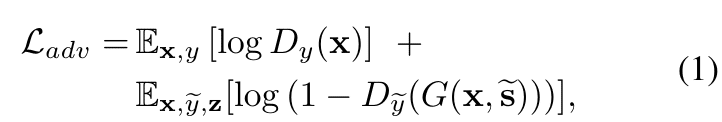
まず、敵対的損失はDiscriminatorが元のドメインの画像を偽の画像と認識する第一項と、Generatorで画像を別ドメインに変換した場合に、Discriminatorが変換先のドメインで真の画像と認識する第二項から成り立つ。$${\tilde{S}}$$は変換先のドメインのスタイルである。(mapping networkの出力か、そのドメインの画像をStyle Encoderに通したもののどちらか)
つまり、ドメイン変換を行った場合、そのドメインらしさが表れるようにする損失である。

次に別ドメインのStyleに変更した場合に、Style Encoderを再度通すことで入力したStyleになる損失である。例えば、人であれば変換先の髪型や髪色の情報をGeneratorに与えた場合、その出力にそれらの情報が正しく画像に埋め込まれているかテストしているようなものである
ただし、この損失単体では学習しづらく、例えばStyleの出力として常に0を出力するようにしてしまえば損失としては下がるが、styleへの情報の埋め込みが行われなくなってしまう
そこで、生成画像が各スタイルで異なるように強制する以下の損失を追加する

(損失を足し合わせる際に符号を逆に使用しているので、画像が違うほど損失が小さくなる)
これにより、異なるスタイルは元の画像が同じでもGeneratorの生成画像を変化させなければいけない効果を持ち、Styleの出力を常に0にするなどが起こらないようにする

最後に、元の画像を別のスタイル($${\tilde{S}}$$)で変換後、元の画像のスタイル($${\hat{S}}$$)で再度変換することで元の画像と同じになるようにする(CycleGANやStarGANとほぼ同じであるが、追加で元の画像のStyle情報を利用できる)
これにより多様性のある変換でありながら、元画像のStyleがあれば正しく復元できることを保証できる
全体として以下のような損失になる

実験結果

提案手法は他の手法と比べて多様性のある顔生成を行いながら、各ドメイン固有の画像の見た目に変換できていることがわかる

特に、Style(上の画像でいうReference)情報は髪の色や長さ、目や唇の色などの抽象的な情報を保持しており、これらがSource画像によらず維持されていることがわかる。逆にSourceは顔の向きや目の位置など座標情報を保持していることがわかる
したがって、Source画像を変更した場合は顔の向きなどの変更、Reference画像を変更した場合は髪の色などの抽象的な変更を行うことができる
この記事が気に入ったらサポートをしてみませんか?