
MM-VID: GPT-4V(ision) を用いてビデオの理解を促進するシステム

本記事では論文の一部を要約し紹介させていただきます。詳細は以下より、論文を参照してください。
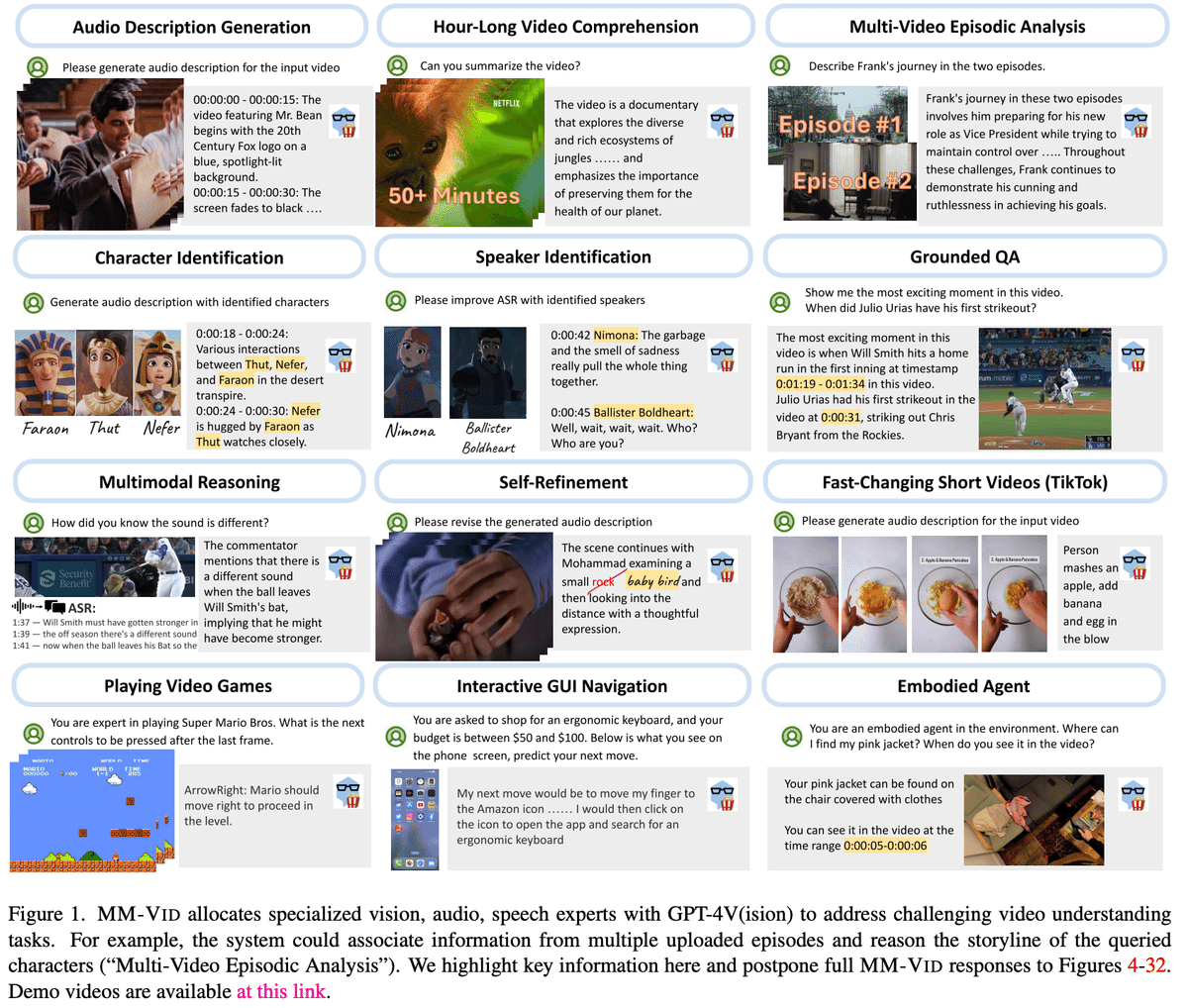
MM-VIDは、GPT-4Vとビジョン、オーディオ、スピーチの専門ツールを組み合わせたシステムで、長時間のビデオ内容やエピソードを跨るストーリーラインの理解を目的としています。ビデオのマルチモーダル要素を長文テキストに変換し、キャラクターの動きや対話などを記録することで、ビデオ理解を実現しています。様々なジャンルのビデオやインタラクティブな環境での有効性が示されています。
Introduction
人々は日々、様々な種類のビデオを創造していますが、特に長時間のビデオ理解は複雑な課題を含んでいます。これは、シーン内の人物の識別や動作の理解、さらには物語の一貫性の維持など、多角的な情報の抽出を必要とします。従来のビデオモデルは短いクリップや限定されたアクションクラスの分析には有効ですが、実世界の長いビデオには対応していません。本研究では、実世界の長いビデオを直接理解するための手法を探求しており、MM-VIDはこのようなビデオを理解し、対話型環境での適用可能性を実証しています。
MM-VID

MM-VIDは、ビデオファイルを入力として受け取り、ビデオ内容を記述するスクリプトを出力するシステムです。生成されたスクリプトにより、大規模言語モデル(LLM)は、様々なビデオ理解機能を実現します。MM-VIDは、マルチモーダル前処理、外部知識収集、クリップレベルのビデオ記述生成、スクリプト生成の4つのモジュールで構成されています。
マルチモーダル前処理では、Automatic Speech Recognition (ASR)ツールを使用してビデオからトランスクリプトを抽出し、PySceneDetectのようなシーン検出ツールで重要なシーンの境界を特定します。
外部知識収集では、YouTubeからメタデータ、タイトル、要約などを収集します。
クリップレベルのビデオ記述生成では、GPT-4Vを用いて、10フレームから成るクリップごとにビデオ記述を生成します。
LLMを使用したスクリプト生成では、各クリップの記述を統合し、ビデオ全体の包括的な記述となる一貫したスクリプトを生成し、ビデオ理解のための様々なタスクに使用します。
ストリーミング入力についても、MM-VIDはストリーミングビデオフレームを連続的に処理し、動的な環境での視覚情報を解釈して、情報に基づいた決定と応答を生成します。このシステムにより、ビデオゲーム、自律エージェント、GUIナビゲーションなどのアプリケーションで視覚データを有用な洞察に変えることができます。

MM-VIDの実行フロー例
ビデオ長の推定:
野球のビデオが入力されると、MM-VIDはまずビデオの推定長を提供します。
シーン検出とASRの呼び出し:
次に、MM-VIDはシーン検出と自動音声認識(ASR)ツールを呼び出します。
外部知識の収集:
同時に、MM-VIDはタイトルや要約などのビデオメタデータを含む外部知識を収集します。

クリップレベルのビデオ記述の生成:
GPT-4Vを使用して、ビデオの各セグメントに対するクリップレベルのビデオ記述を生成します。

ビデオ記述の出力:
GPT-4Vはビデオフレームとテキストプロンプトを入力として受け取り、それに基づいてビデオ記述を出力します。

一貫したスクリプトの生成:
クリップレベルの記述、ビデオメタデータ、ASR情報を元に、GPT-4を用いて入力ビデオのための一貫したスクリプトを生成します。

この記事が気に入ったらサポートをしてみませんか?