データ解析の流れ(2): データの連結

データの読み込みに続いて、2つのデータの連結を行います。データ解析の際、計算や、グラフを作成する前に費やされる時間のほとんどが、このデータの連結と、データの抽出(フィルタリング)の作業になりがちです。tidyverse には、それらをサポートする関数が整備されているので、大変助かります。
inner_join() によるデータの連結
input_data の中身は、下記のようになっています。ある Id のアイテムについて、Sample1 と Sample2 の数値データがあります。
> input_data
# A tibble: 3 × 3
Id Sample1 Sample2
<chr> <dbl> <dbl>
1 id1 1 4
2 id2 2 5
3 id3 3 6これに連結したいデータが meta_data です。これは、各IDについて説明したデータで、それぞれの Id について、Symbol (シンボル)と Description (記述)があります。
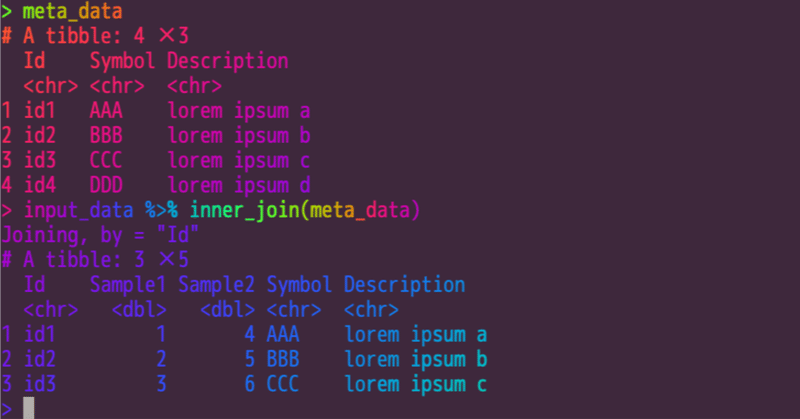
> meta_data
# A tibble: 4 × 3
Id Symbol Description
<chr> <chr> <chr>
1 id1 AAA lorem ipsum a
2 id2 BBB lorem ipsum b
3 id3 CCC lorem ipsum c
4 id4 DDD lorem ipsum d計算に用いる数値データと、それを説明する情報のデータ(計算には必要ない)という組み合わせは、よくあります。その場合、どちらも共通な項目があれば、それをキーに、2つのデータを関連づける(結合させる)ことができるはずです。
つまり、 id1 の数値データ (Sample1, Sample2) に、これを説明する Symbol である AAA を、id2 には BBB を、 id3 には、 CCC を結合させることになります。
これを実現する関数が、 inner_join() です。
「inner_join(input_data, meta_data, by = "Id")」と、コンソールに入力すると結果が表示されます。
> inner_join(input_data, meta_data, by = "Id")
# A tibble: 3 × 5
Id Sample1 Sample2 Symbol Description
<chr> <dbl> <dbl> <chr> <chr>
1 id1 1 4 AAA lorem ipsum a
2 id2 2 5 BBB lorem ipsum b
3 id3 3 6 CCC lorem ipsum c意図していた通りに結合されていることが確認できます。by = "Id" として、Id をキーにして結合させることを明示していますが、2つのデータに共通な項目が1つしかない場合は、省略も可能です。下記は、省略した例です。 Joining, by = "Id" と推測して処理されていることが確認できます。
> inner_join(input_data, meta_data)
Joining, by = "Id"
# A tibble: 3 × 5
Id Sample1 Sample2 Symbol Description
<chr> <dbl> <dbl> <chr> <chr>
1 id1 1 4 AAA lorem ipsum a
2 id2 2 5 BBB lorem ipsum b
3 id3 3 6 CCC lorem ipsum cこの inner_join という考え方は、データベースのテーブルを連結する際に使用されていたSQL言語のクエリーの「INNER JOIN」が元になっています。2つテーブルの共通部分を結合するので「インナー」です。そのため、上記の例でも、meta_data にしかない id4 のデータは、結果に含まれていません。
補足: left_join, right_join
共通でないものを残す場合は、left_join() または right_join() を使います。この場合、右 (right) の meta_data に対して連結させると、 id4 が残ります。input_data には、 id4 がないので、 Sample1 と Sample2 の値は、NA (not available) になります。
> right_join(input_data, meta_data)
Joining, by = "Id"
# A tibble: 4 × 5
Id Sample1 Sample2 Symbol Description
<chr> <dbl> <dbl> <chr> <chr>
1 id1 1 4 AAA lorem ipsum a
2 id2 2 5 BBB lorem ipsum b
3 id3 3 6 CCC lorem ipsum c
4 id4 NA NA DDD lorem ipsum dこの記事が気に入ったらサポートをしてみませんか?