
AWS Inf1上でBERTモデルの推論を走らせる―モデルコンパイルから速度比較まで

今回のテックブログは、BERTの系列ラベリングをサンプルに、Inferentia、GPU、CPUの速度・コストを比較した結果を紹介します。Inf1インスタンス上でのモデルコンパイル・推論の手順についてのお役立ちチュートリアルも必見です。
AWS Inf1とは
こんにちは。メディア研究開発センター (通称M研) の田口です。今回はAWSのInf1インスタンス上でBERTモデルを動かす際の流れをご紹介したいと思います。
さて、みなさんは機械学習モデルの推論をどこで走らせていますか?
BERTのようなサイズの大きいモデルを走らせる場合、コスト上問題なければTPU・GPUを使いたいですよね。とはいえ、できるだけコストは抑えたいのでCPUを選択すると「推論速度が…」という悩みがでてきます。そこでM研では、GPU・CPUに代わる選択肢としてInferentiaというチップを搭載したAWS Inf1の検証を進めており、一部のタスクではInf1を採用しています。
AWS Inf1インスタンスがどのようなものかというと、公式ページでは下記のように説明されています (太字は筆者による) 。
Amazon EC2 Inf1 インスタンスは、クラウドで最も低いコストで高性能 ML 推論を提供します。これらのインスタンスでは、同等の現行世代の GPU ベースの Amazon EC2 インスタンスと比較して、スループットが最大 2.3 倍高く、推論あたりのコストが最大 70% 低くなっています。AWS Inferentia チップには4つのNeuronコアが含まれています。
一見するといいこと尽くしなのですが、もちろんInf1にはデメリットといいますか不便な面も存在します。メリット・デメリットを簡単にまとめると下記のようになります。
メリット
・GPUと比較してコストが安い
・GPUとほぼ同等の速度が出せる
デメリット
・モデルのコンパイルが必要
・float32で訓練したモデルの重みをBfloat16に変換しているため一部の予測結果が変わる
デメリットの箇所に「モデルのコンパイルが必要」とありますが、これは先ほど引用したInf1の説明にある「Neuronコア」上で動かせる形式に変換する必要があるからです。これに関してはAWSが提供しているSDK (Neuron SDK) があるのでそちらを使います。
本記事では、Hugging Face TransformersのBERTの系列ラベリングモデル (Pytorch) をInf1上で動かす流れを説明していきます。最後に、「CPU・GPUと比較してどのくらい速くなるのか?」という疑問に答えるため、ベンチマークの結果も載せています。
Inf1利用の流れ
まず最初にInf1インスタンス上でBERTモデルを走らせる際の流れは、大まかにはこのようになっています。
1. インスタンス作成:AMIはDeep Learning AMI (Ubuntu 18.04) を利用し、インスタンスタイプはinf1を選択
2. Neuron SDKのアップデート
3. BERTモデルのコンパイル
4. コンパイルしたモデルのデプロイ (本記事では省略)
2番目に「Neuron SDKのアップデート」とあるのは、先月末 (2021年10月末) にNeuron SDKがアップデートされてコンパイルオプションなどが変わったので最新のものを使うためです。それでは環境構築をしていきましょう。
Inf1上での環境構築
まずはInf1のEC2インスタンス (今回はinf1.xlarge) を立ち上げます。この際、Neuron SDKが既に入っている「Deep Learning AMI」を利用しましょう。そして、今回は最新のNeuron SDKにアップデートしたいので、こちらのドキュメントを参考にSDKのアップデートをします。下記は公式ドキュメントで記載されているもののコピペです。
# Note: There is no DLAMI Conda environment for this framework version
# Framework will be installed/updated inside a Python environment
# Update OS packages
sudo apt-get update -y
###############################################################################################################
# Before installing or updating aws-neuron-dkms:
# - Stop any existing Neuron runtime 1.0 daemon (neuron-rtd) by calling: 'sudo systemctl stop neuron-rtd'
###############################################################################################################
################################################################################################################
# To install or update to Neuron versions 1.16.0 and newer from previous releases:
# - DO NOT skip 'aws-neuron-dkms' install or upgrade step, you MUST install or upgrade to latest Neuron driver
################################################################################################################
# Update OS headers
sudo apt-get install linux-headers-$(uname -r) -y
# Update Neuron Driver
sudo apt-get install aws-neuron-dkms -y
####################################################################################
# Warning: If Linux kernel is updated as a result of OS package update
# Neuron driver (aws-neuron-dkms) should be re-installed after reboot
####################################################################################
# Update Neuron Tools
sudo apt-get install aws-neuron-tools -y
# Activate PyTorch
source activate aws_neuron_pytorch_p36
# Set Pip repository to point to the Neuron repository
pip config set global.extra-index-url https://pip.repos.neuron.amazonaws.com
# Update Neuron PyTorch
pip install --upgrade torch-neuron neuron-cc[tensorflow] torchvision余談ですが、新しいNeuron SDKになってからneuron-topコマンド (Neuronコアの使用状況を確認するコマンド) がより見やすくなりました。

さて、アップデートが完了したらNeuronのバージョンを確認してみましょう。Neuronコアで動くPytorchということでtorch-neuronというライブラリがインストールされています。また、今回はtransformersのv4.12.0を使うのでそちらもインストールしましょう。
# Neuronのバージョン確認
$ pip freeze | grep neuron
neuron-cc==1.7.3.0+c02f9fde4
torch-neuron==1.9.1.2.0.392.0
# transformersのインストール
$ pip install transformers==4.12.0BERTモデルのコンパイルをする
環境構築も終わったところでさっそくモデルをコンパイルしていきましょう。今回は、日本語の品詞解析を行う系列ラベリングモデルをサンプルに用います。系列ラベリングというのは、単語ごとにラベルを予測するものです。単語の品詞解析はMeCabなどでもできますが、今回はBERTの系列ラベリングモデルのサンプルとしてこれを利用します。
Hugging Face Model Hub上で「これが系列ラベリングです。」という文の予測結果を得ることができます。

品詞タグが英語ですが、これはUniversal POSタグとなってます (タグの日本語対応はこちらが参考になります) 。
# 解析結果
これ:代名詞
が:設置詞
系列:名詞
ラベリング:名詞
です:助動詞
。:句読点
さて、系列ラベリングの説明はこのくらいにして、さっそくモデルをInf1上で動かせるようにコンパイルしていきましょう。「モデルのコンパイル」といっても、モデルの読み込み・コンパイル・保存のすべてを書いても30行程度で済みます。流れとしては、TorchScriptでtraceするのとほぼ同じです。
from transformers import AutoTokenizer, AutoModelForTokenClassification, AutoConfig
import os
import torch.neuron
# BERTモデルの読み込み
bert_path = "KoichiYasuoka/bert-base-japanese-upos"
tokenizer = AutoTokenizer.from_pretrained(bert_path)
model = AutoModelForTokenClassification.from_pretrained(bert_path)
sample_input = "これはtrace時に使うためのダミーテキストです。"
# 入力の最大系列長を事前に指定する
max_length = 256
tokens = tokenizer(
sample_input,
padding="max_length",
max_length=max_length,
return_tensors="pt",
truncation=True,
)
example_input = (
tokens["input_ids"],
tokens["attention_mask"],
tokens["token_type_ids"],
)
# コンパイル (Neuron)
model_neuron = torch.neuron.trace(model, example_input, strict=False)
# torch.jitの場合 (CPU)
# traced_model = torch.jit.trace(model, example_input, strict=False)
# モデルの保存
model_neuron.save("bert_neuron.pt")さて、モデルのコンパイルが終わったら実際に読み込んでみて予測をしてみましょう。無事にモデルの読み込みと予測ができています。
# import文など一部省略
sample_input = "Inf1用にコンパイルしたモデルで予測してみる。"
# 入力の最大系列長を事前に指定する (コンパイル時と同じ長さに設定する)
max_length = 256
tokens = tokenizer(
sample_input,
padding="max_length",
max_length=max_length,
return_tensors="pt",
truncation=True,
)
example_input = (
tokens["input_ids"],
tokens["attention_mask"],
tokens["token_type_ids"],
)
# 各トークンごとの予測ラベルを出力
with torch.inference_mode():
logits = model_neuron(*example_input)["logits"]
pred = np.argmax(logits.detach().numpy(), axis=2)
# [CLS], [SEP]を除いた範囲でトークン・IDに該当するラベルを出力
for label, token in zip(pred[0][1:-1], tokenizer.tokenize(sample_input)):
print(token, config.id2label[label])
"""
I B-NOUN
n I-NOUN
f I-NOUN
1 NUM
用 NOUN
に ADP
コ B-VERB
ン I-VERB
パ I-VERB
イ I-VERB
ル I-VERB
し AUX
た AUX
モ B-NOUN
デ I-NOUN
ル I-NOUN
で ADP
予 B-VERB
測 I-VERB
し AUX
て SCONJ
み B-AUX
る I-AUX
。 PUNCT
"""コンパイル時のtips
上述のサンプルでInf1上でBERTモデルを走らせることができましたが、Neuron SDKではコンパイル時のオプションがいくつか用意されています。ここでは2つほど取り上げて紹介します。
パイプラインモード
サンプルコードでは4つあるNeuronコアのうち、1つのコアだけにモデルを載せて推論させていました。本来は4コアあるので、2つの使い方ができます。
1. 各コアにモデルを配置してリクエストを処理
2. 1つのモデルを各コアに分割して配置する
このうち、2に該当するものがパイプラインモードです。イメージとしては、公式ドキュメントに記載されている下記図がわかりやすいです。各コアにモデルのパラメータを配置するわけですが、これはNeuron SDKがコンパイル時に自動で行ってくれるので、Neuronコアの数のみ指定すればOKです。

※画像はNeuron SDK公式ドキュメントより引用
パイプラインモードのサンプルコードは下記のとおりです。引数を一つ追加するだけでパイプラインモードでコンパイルしてくれます。推論を走らせている間にneuron-topコマンドを叩いてみると、各Neuronコアが使用されていることが確認できます。
# コンパイル (Neuron)
# --neuroncore-pipeline-coresにはNeuronコアの数を記載 (inf1.xlargeの場合は4)
model_neuron = torch.neuron.trace(
model,
example_input,
strict=False,
compiler_args=["--neuroncore-pipeline-cores", "4"],
)ただし、inf1.xlarge上でコンパイルすると下記のようなメッセージが出るので、パフォーマンスを上げたい場合はInf1.6xlargeなどのインスタンスを使うことも考慮に入れた方がいいかもしれません。
INFO: The requested number of neuroncore-pipeline-cores (4) may not be suitable for this network, and may lead to sub-optimal performance. Recommended neuroncore-pipeline-cores for this network is 16.
精度のチューニング
もうひとつ紹介するのが、"--fast-math"オプションについてです。Neuron SDKでモデルをコンパイルするとBfloat16に変換されるため、同じデータでもCPU・GPU上での予測結果と変わってしまうことがあります。そこで"--fast-math"オプションで、すべてのfloat32の演算をBFloat16に置き換えるのか、一部のみキャストするかなどを選ぶことができます。こちらもパイプラインモードと同様で、引数を追加するだけで簡単に行えます。詳細については公式ドキュメントを参照してください (下記) 。
どのくらい高速になったのか?
ここではInf1がCPU・GPUと比べてどの程度高速になったのかを検証していきます。今回は下記の環境および条件でCPU・GPU・Inf1の速度比較を行います。
# AWSのインスタンスタイプ
CPU: c5.xlarge
GPU: g4dn.xlarge
Inf1: inf1.xlarge
# 推論の実験設定
バッチサイズ: 1
最大系列長: 256 (CPU・GPUではpaddingしないパターンも実験)
パイプラインモードの有無: Inf1でのみ実験
TorchScriptの有無: CPU・GPUでのみ実験
# ライブラリのバージョン
pytorch==1.9.1
transformers==4.12.0
2021年11月時点での各種インスタンスの時間単価 (東京リージョン) は以下のとおりです。

検証には、2021年10月に朝日新聞紙面に掲載された記事本文からランダムに抽出した1,000文を使用してスループットと標準偏差を算出しています。また、各インスタンスの時間単価から1,000文を推論する際のコストも計算しています。推論対象のデータの平均文字数は58.8文字で、最大でも136文字のためコンパイル時と同じように最大系列長は256で揃えて実験をします。
実験した結果は下記の表のとおりです。スループットに関しては、g4dn上でpaddingをしないケースが最も高かったです。バッチサイズ=1の場合はpaddingをせずに推論が可能なので、256トークンでpaddingした時と比べてCPU・GPUともに2倍以上高速になっています。また、パイプラインモードに関しては、速度の向上は見られませんでした。
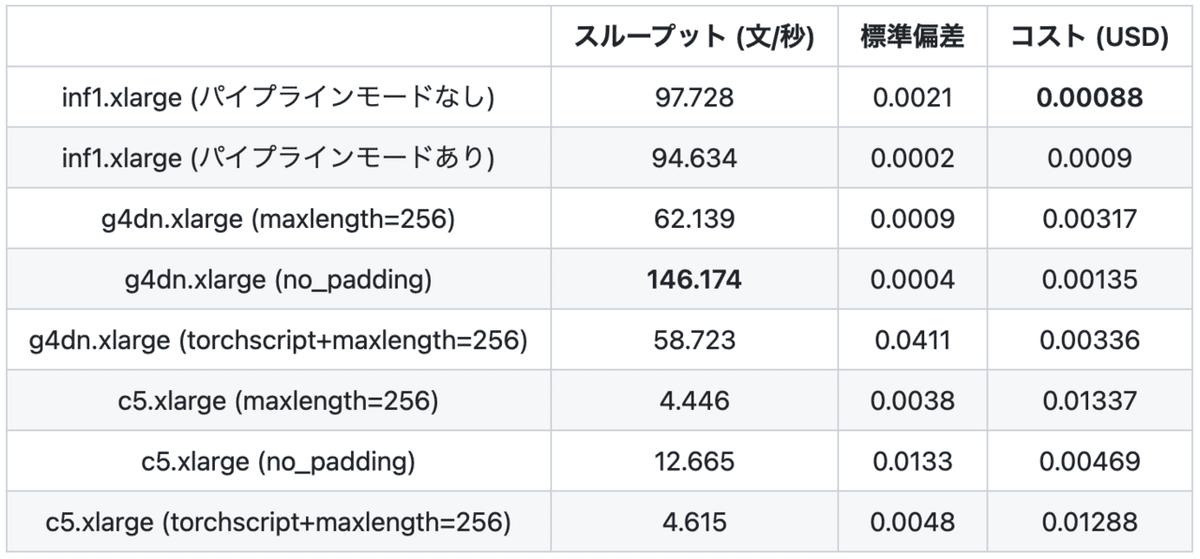
1,000文あたりのコストでは、inf1が最も安上がりでした。paddingなしと比べるとCPU比で5.3倍、GPU比で1.5倍ほどコストパフォーマンスが良かったです。
まとめ
本記事では、AWSのInf1インスタンス上でBERTモデル (系列ラベリング) を動かす際の流れについて説明し、CPU・GPUインスタンスとの速度比較を行いました。モデルコンパイルの手間はあるものの、そこまでの負荷はないので、Inf1上でコンパイルしたモデルの予測精度が許容範囲内であれば選択肢の一つにしてみてはいかがでしょうか?
今回は、バッチ推論は考慮せず、またコンパイルオプションの違いによる精度・速度のトレードオフについても特に言及しませんでした。この辺の話はまたどこかでまとめられればと思います。
Inf1を利用する上で参考になったサイト
・Neuron SDKの公式ドキュメント
・AWSの推論用インスタンスInf1について (part1), (part2)
・Amazon EC2 Inf1 インスタンスを使用した深層学習の推論のハンズオン
・AWS Inferentia上のPyTorch自然言語処理アプリケーションにおいて、12倍のスループットと最小のレイテンシーを実現
(メディア研究開発センター・田口雄哉)