
朝日新聞クロスサーチ爆誕!〜データベース横断検索を強化〜

今回のテックブログは、朝日新聞社の膨大な記事情報にアクセスできる「記事検索サービス」のリニューアルにまつわるお話です。複数のデータベースを一気通貫させる改修には大きな壁がありました。どんな体制で取り組み、どう解決したのか、その詳細をご紹介します。
はじめに
みなさん、初めまして。
開発部・2年目の中阪と申します。
今回は私が所属する商用DBチームでの業務を、運営するサービスのプロモーションも兼ねてご紹介したいと思います。
是非最後までお付き合いください。
突然ですが、みなさん朝日新聞が創刊したのは何年かご存知でしょうか?
正解は1879年(明治12年)。
1879年と言えばエジソンが白熱電球を実用化した年らしいです。そう考えると、とても歴史を感じますね。
DBチームでは朝日新聞が創刊してから現在に至るまで発行してきた紙面、記事、雑誌、写真などをDBに保管しています。
二大サービス 聞蔵と朝日けんさくくん
そして、それらのコンテンツを現在は主に公共図書館や学校図書館でご利用いただいています。つまりBtoBのビジネスをやっています。
そのDBを閲覧する窓口となるサイトが以下の二大サービス、聞蔵(きくぞう)と朝日けんさくくんになります。
聞蔵は主に大学・公共図書館向けのサイトで、記事や紙面は勿論のこと、著名人の人物情報や英文ニュースも閲覧できます。

一方の朝日けんさくくんは小・中学校、高校向けのサイトで、天声人語漢字トレーニングや和英対照など学習コンテンツを取り入れたラインナップとなっております。

開発に至る経緯
今回、この2つのサイトをフロントエンドからバックエンドまで大幅に改修する運びとなりましたので、その取り組みをご紹介していきたいと思います。
そもそも何故これらのサイトを大幅に改修することとなったのか。
それには深い訳がありまして....。
実は朝日新聞社が保有する商用DBは保管場所からDBの種類、検索エンジンまで全部バラバラで仕様が全く異なる状況にありました。
それを現在は聞蔵・けんさくくんサービス側がDBの仕様に沿ったリクエストをDB側に投げることでデータを貰ってきていたのです。
でも、これじゃ商用DBを活かした新しいサービスを作ろうにも、またサービス側でDBの仕様の違いを考慮する必要があり、大変な労力がかかってしまう....と!
このままだと、いくらたっても聞蔵・けんさくくんに次ぐサービスを作れないじゃないか!!!
商用DBという、朝日新聞社が長年の間培ってきた強力なコンテンツを最大限に有効活用できていなかったのが今までのBad Pointでした。
解決策
そこでこのボトルネックを解消するため、今回、DBとサービスの間にBFF(Backend For Frontendの略です。Best Friend Foreverじゃないですよ!)
としてリクエストを一括して受け付けるAPI基盤を作り、難しいことは全部コイツにやらせようということになったのです。
サービス側はこの基盤にリクエストを送るようにして、仕様の差異はAPI基盤の方で捌いてもらおうというわけです。
図にすると次のような感じです。
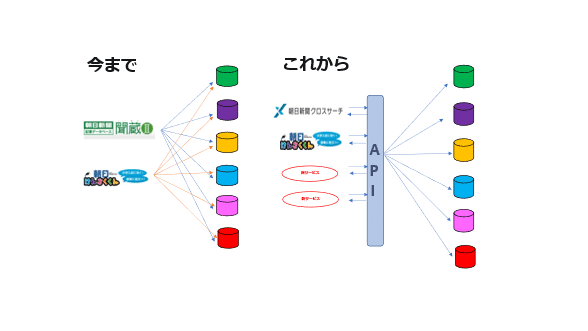
左が今までの構成、右がこれからの構成です。
それに合わせて聞蔵・けんさくくんもAPI基盤を使用した構成に作り替え、全面リニューアル。
聞蔵は朝日新聞クロスサーチに名称変更します。何故クロスサーチなのか。
今回の改修で各DBをまたがって検索できる横断検索機能を全面プッシュすることになりました。
次の画像が横断検索実行時の結果です。各コンテンツ別に検索結果を表示できるようになりました。
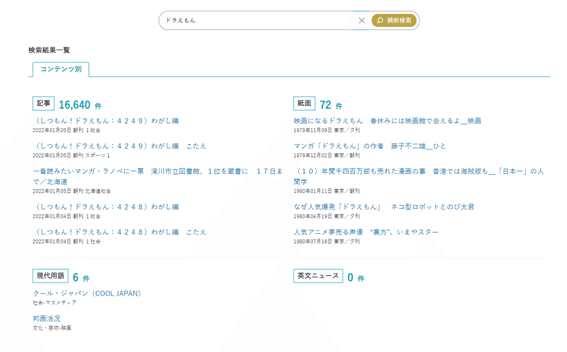
さらにクロスサーチ・新けんさくくんともレスポンシブデザインに対応。これはGIGAスクール構想の推進で、学校でタブレット端末等にて閲覧される機会が増えることを想定したものです。
実は今まで聞蔵・けんさくくんの実装はほとんど外注で開発ベンダーに頼りっきりだったのですが、今回のタイミングで内製中心の開発体制に大きく転換しました。しかし、今まで内製での開発経験が少ない私たちにとって、いきなり全て自前で開発するのはハードルが高い、ということもあり業務委託で数名の社外エンジニアに参画していただきました!
どの方も経験豊かな†歴戦の強者†ばかりで、彼らから高い技術力を吸収することで社内に内製開発に関するノウハウを蓄積する、というのもこの方々を招いた理由のひとつでした。私も分からないところは彼らの作業を止めてまで聞きまくってました!
私は主にAPIの開発を担当。
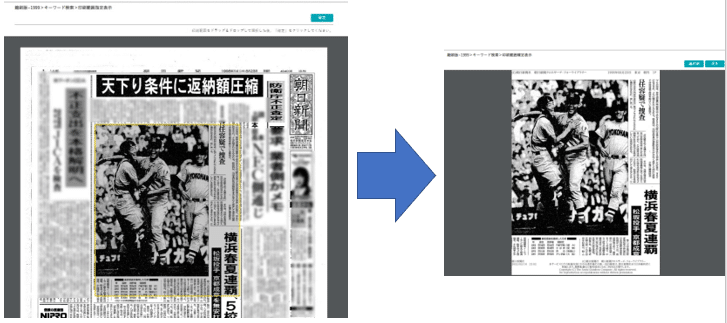
ほんの一例ですが、DBからとってきた紙面をユーザーの意図したサイズで切り取る機能は私が作りました!!フロントから切り取る四隅の座標を貰ってAPI側で切っています。紙面を切り取る度に「あ~、ここは中阪が作ったんだな」と思い出して欲しいです!
開発言語はTypeScript、実行環境はNode.jsを使用しました。横断検索実行時はPromise.all()で各DBへの検索を非同期/並列実行しているので、しっかり速度も出ています。
TypeScriptの魅力については先輩の松原さんが存分に語ってくれていますので、詳しくは以下の記事をご覧ください。
https://note.com/asahi_ictrad/n/n08061a964a07
一方のフロントエンドではフレームワークとしてVue.jsを用いています。
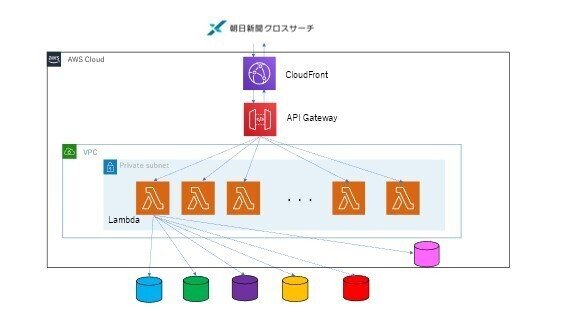
また、API、フロントサービス共にAWS S3やAPI Gateway、Lambdaを用いたサーバーレス構成を実現しました。AWSの構成図はだいたい以下のような形になります。セキュリティー上の観点から詳細な構成図をお見せすることはできませんが、流れとしてはCloudFront→APIGateway→Lambda→商用DBという順にデータを取得しに行きます。
開発環境はAWS Cloud9を使用しています。
AWS Cloud9はブラウザベースで動く統合開発環境(IDE)です。Cloud9サーバーの実体はAWS EC2ですので全員同じOSで環境構築できますし、コードをデプロイしてすぐに他のAWSのサービスと連携させることができる点が魅力的でした。全員の開発環境を揃えるために全員の貸与PCを同じにするという選択肢もありましたが、Cloud9を用いることでコスト削減を実現しました。また、他にも環境構築の手間が省けたり、ブラウザで動くので場所を選ばなかったりする点もメリットです。
リニューアル版のリリース予定
朝日新聞クロスサーチ(旧:聞蔵)は2022年3月1日に先行リリース、2022年4月1日に正式リリース予定です。
朝日新聞社データベース事業部が用意したプロモーションサイトは以下になります。
http://www.asahi.com/information/db/2022renewal/
また、朝日けんさくくんも大幅リニューアル予定です。学校での活用事例は以下になります。
http://www.asahi.com/information/db/kensaku.html
皆さんの通われる学校、またはお近くの公共図書館でもきっと閲覧できるかと思いますので、是非是非チェックしてみていただければと思います。
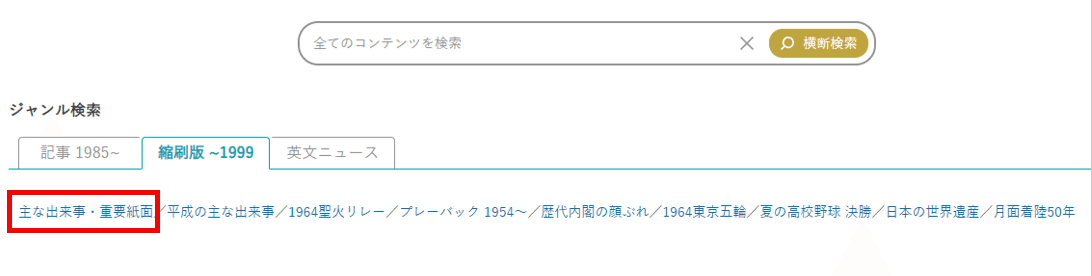
ちなみに私のおすすめは「主な出来事・重要紙面」ボタンで表示できる歴史上の重大ニュースを一覧表示したページです。タイムマシンに乗ったみたいで、歴史好きな人は夢中になって読めると思いますよ!
今後
今後はこのAPI基盤を使って商用DBを活かした他のサービスを新たに立ち上げることになると思いますので、その際はまた宣伝しに来ます!
ゆくゆくは朝日新聞社の看板サイト、朝日新聞デジタルの一部機能もこのAPI基盤を経由することになるかも??
それでは、また別のエントリでお会いできる日を楽しみにしています!!
(開発部・中阪真明)