
【きっかけから研究成果まで】新聞社で取り組むリサーチインターンのすべて

今回のテックブログは、インターンに興味のある学生さんは必見!
M研でインターンとして活躍されている山田さんの登場です。
「NLPのリサーチインターンって何してるの?どこまでやれるの?」
「リモート環境下でのインターンってどんな感じ?」
そんな疑問にお応えしつつ、インターンになったきっかけから研究成果までをじっくりご紹介。読み応えあるエントリをどうぞ〜。
はじめに
はじめまして!
朝日新聞社メディア研究開発センターでインターンをしている山田康輔と申します。2020年4月(当時、博士前期課程2年)から自然言語処理分野のリサーチインターン生として、完全リモートで週2日、自動要約に関する研究に取り組んでいます。
今回の記事では、リサーチインターン生になった経緯と、インターン生としての研究活動、実際に取り組んだ研究「指定語句を確実に含む見出し生成」について簡単に紹介します。企業で自然言語処理に関するリサーチインターンシップに参加したい方や、朝日新聞社で自然言語処理に関する研究開発に取り組んでみたい方の参考になったら嬉しいです!
リサーチインターン生になった経緯
私は現在、名古屋大学大学院情報学研究科博士後期課程の1年次に在籍しており、所属は武田・笹野研究室です。そこでは、主に自然言語処理分野の意味解析領域に関する研究に取り組んでいます。現在、研究室では語の意味を理解するために必要な背景知識である意味フレーム知識のリソース構築を行っています。Webサイトにこれまでの私の研究活動等をまとめているので、興味のある方がいれば是非ご覧ください!
ここから朝日新聞社のインターン生になった経緯について書いていこうと思います。インターン生になったきっかけは、Peakersが主催するコンペティション形式のイベントに参加したことです。これは自分の専門分野である自然言語処理技術の活用をテーマとしており、新聞記事データを使ったタスクに取り組むことができるため、実データを扱うノウハウが獲得できると考え、参加しました。また、当時は対面でイベントが開催されており、自然言語処理を扱っている仲間や企業の方と交流したいと考えていました。
実際、イベントでは、「朝日新聞社の記事データを用いて『その記事が多くの人に読まれたかどうか』を規定の基準で2値分類する」というタスクに取り組みました。このタスクに取り組んでいる中で、大きく2つのことを体感しました。
1つは、記事データが綺麗であると感じたことです。自然言語処理技術を応用したシステムを構築するときには、テキストデータの前処理がかなり重要になってきます。このため、ノイズ除去のような処理が必要であることが多いです。しかし、ここで扱ったデータはそのような処理をあまり行う必要のないデータになっており、とても扱いやすい印象を受けました(裏で扱いやすいデータにしていただいていたのもありますが、実際にインターン生として参加する中でも、とても扱いやすいデータになっていました)。
2つは、朝日新聞社が自然言語処理技術にかなり力を入れていることです。コンペティション中では、提供されたものより大規模な記事データを用いて学習した単語ベクトルや、記事から短い要約文を生成する自動要約APIを自由に使わせてもらえました。これらを実際に使用したのですが、両方ともかなり有用で精度が高いのがとても印象的でした。
これらのことから朝日新聞社での自然言語処理研究開発に興味を持ちました。この日の懇親会のときに、ちょうど朝日新聞社でリサーチインターンシップに取り組みたい人を探しているという話を聞きました。また、その当時、自動要約のようなテキスト生成タスクに取り組みたいと考えており、インターンシップに挑戦することにしました。
リサーチインターン生としての研究活動
ここからは実際にインターン生としての研究活動について紹介していきます。
まず、インターンは、週に2日程度、10時から18時まで(1時間休憩含む)、完全リモートという形式で行っています。ミーティングは不定期で月に1,2回行っています(リモートワークが当たり前の状況になる前は、月に1回程度出社し、それ以外はリモートで作業するという話になってました)。個人的には、研究室の活動も完全オンラインでしたので、特に不都合なく進めることができ、快適に研究活動が行えています。また、年に数回、東北大の乾先生と東工大の岡崎先生と研究について議論する機会があり、他の研究室の先生と議論するというとても貴重な機会が得られています。
実際の研究活動は、研究テーマ決めから始まりました。通常のリサーチインターンシップの場合、事前にある程度テーマが決まっていたり、実務の一部分に取り組むことが多いです。しかし、このインターンは、現在取り組んでいるものに関係なく、自由に決めていいという形式でした。限られた日数の中でこれを行うのはかなり大変で、特に、朝日新聞社の持つリソース内で取り組めるもの、実際のサービスとして提供できるもの、研究テーマとして成立するものという制約があり、それを満たすテーマとアイデアを求められたことに苦戦していました。インターンを開始した当初は記事からの見出し生成の精度を高めようと意気込んでいたのですが、現行のモデルの生成結果を見るとかなり質が高く、ここを進めてもあまり面白くないと思い、すぐにやめました。
その後、テーマを出し続けるもなかなか決定せず、最終的なテーマが決まるまで半年間くらいかかりました。テーマを考えている間は「現行の要約モデルによる見出し生成」や仮テーマとして「指定語句を含まない見出し生成」などに取り組んでいました。指定語句を含まない見出し生成に関しては、生成する際に単語候補から指定語句を除去するのみで、かなりうまく動作することを確認しました。
この仮テーマに取り組んでいる最中に、その逆の指定語句を含んだ見出し生成はどうかという話になりました。最初は生成する中で無理やり出すかという話をしていたのですが、それよりも指定語句から外向きに生成すればいいかもしれないというアイデアが出て、この研究テーマとアイデアを進めていこうということになりました。
その後は順調にモデルの実装、実験を進めることができ、言語処理学会第27回年次大会(NLP2021)への発表に至りました。以下がその予稿になります。次の章で簡単に内容を紹介します。
山田 康輔, 人見 雄太, 田森 秀明, 岡崎 直観, 乾 健太郎: 指定語句を確実に含む見出し生成, 言語処理学会第27回年次大会
実際に取り組んだ研究内容
ここからは「指定語句を確実に含む見出し生成」の研究内容を紹介します。そもそも見出し生成とは、以下のように記事から見出しを自動生成することが目標です。これによりTwitterなどの様々な媒体で表示するための見出し作りを効率的に行うことができます。
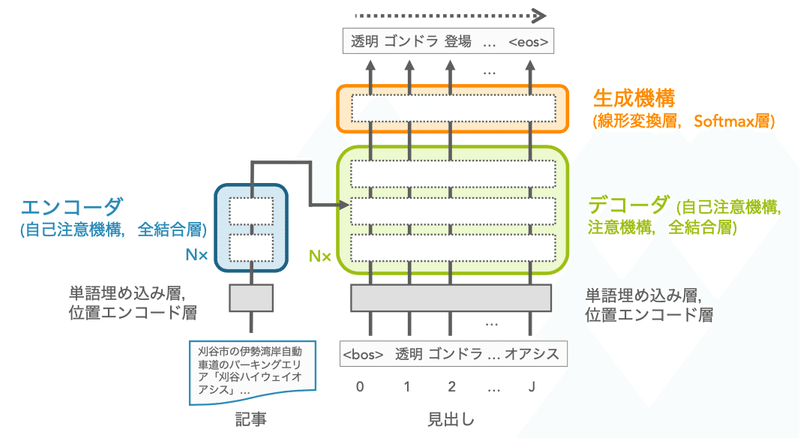
見出し生成では、生成型要約モデルを用いた研究が盛んに行われています。多くはエンコーダ・デコーダモデルを用いており、エンコーダに記事を入力し,デコーダで見出しを生成するようになっています。この研究では、以下に示すようなエンコーダ・デコーダモデルとして代表的なTransformerモデルを利用しています。このモデルにおける見出しの生成は、エンコーダに記事の単語トークン列、デコーダにこれまでに生成された見出しの単語トークン列(最初は文頭トークン<bos>)を入力し、次の単語トークンを生成していく(文末トークン<eos>が生成されるまで繰り返す)ことで実現します。
上記のようなモデルを用いて、最近では、指定語句を挿入するように制御された見出し生成も行われています。たとえば、上記の例で言えば「透明ゴンドラ登場」を指定したとき、
「透明ゴンドラ登場 刈谷ハイウェイオアシスの観覧車」
のような見出しを生成することが目標となります。このタスクは広告記事などの見出しを生成するとき、商品名や企業名などを含めた見出しを自動生成したいという要望を実現します。
先行研究の1つとして、事前学習済みTransformerであるBARTを用いたHeら (2020)の研究が存在します。彼らは、エンコーダに入力する記事の直前に指定語句(学習時は記事に対応する人手で作成された見出し中の語句、生成時は任意の語句)と”|”を挿入、また、記事中の指定語句を一定の確率で削除するといった工夫をすることで、このタスクに取り組んでいます。以下がその入力記事の例です。

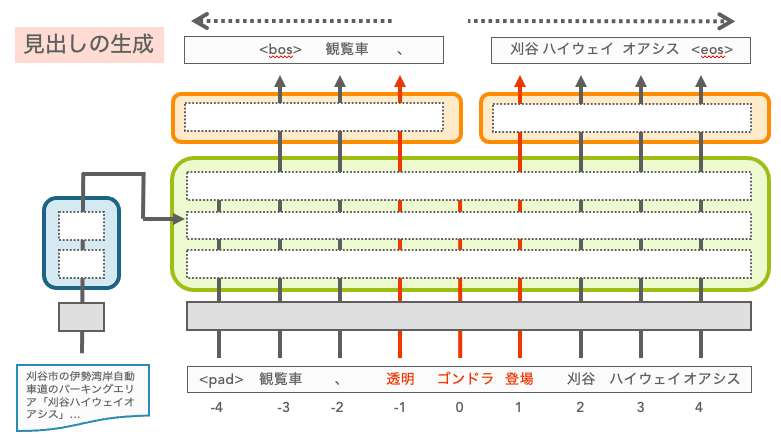
しかし、このような手法ではエンコーダ側を工夫するのみで、必ず指定語句を含む可能性は上げられますが、必ず含むとは限りません。これは実応用する上で大きな欠点となります。そこで考えたのは指定語句から文頭、文末へ向けて同時に生成する方法です。このようにすれば、指定語句が最初から入っているので、確実に指定語句を含む見出し生成が可能となります。この研究では、この生成メカニズムをDual Outward Generation mechanism (DOG)と呼んでいます。

TransformerモデルをベースとしたDOGによる生成の概要は以下のようになります。通常のTransformerとのネットワークの違いは生成機構が2つ存在することです。これは前方の単語トークン予測と後方の単語トークン予測を異なるネットワークで行った方が良いという考えからこのようになっています。また、前方と後方にどれだけの単語が生成されるかが不明なため、入力する単語トークン位置が指定語句の中心の位置が0となるようにしています。
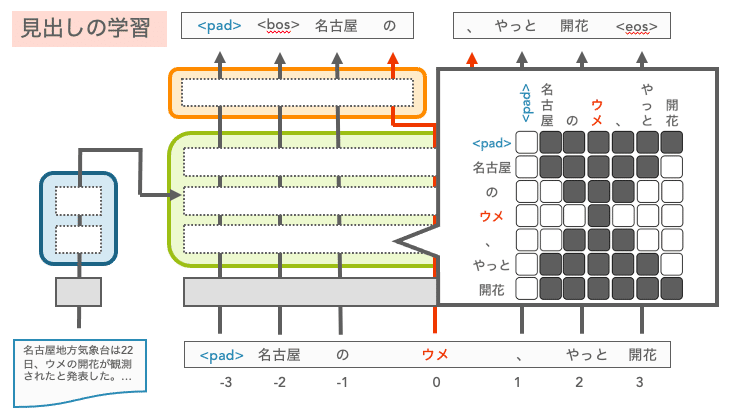
また、このモデルの学習時には、デコーダの自己注意機構で使用するマスク方法に工夫が必要です。通常のTransformerでは入力時点以降の単語を参照しないようにしますが、DOGでは入力時点以降の単語も参照しないようにする必要があります。そこで、以下の図に示すようなマスクを利用しています。
実験は朝日新聞社メディア研究開発センターが公開している日本語ニュースコーパスであるJapanese News Corpus (JNC)の2019年版を用いて行っています。JNCには1,932,399件の記事-見出しペアが存在し、これらを学習セット、開発セット、テストセットとして 98:1:1 の比率で無作為に分割して使用しています。
実験結果の詳細はここでは省略しますが、簡潔にまとめると、Heらのモデルが指定語句出現率95.9%のところ、提案したDOGは指定語句出現率100%を達成し、その上で生成された見出しの質もTransformerやHeらのモデルと同等であることを確認しました。
実際の生成結果の例が以下のようになります。「桜といわしのパフェ」や「6月末まで」のような商品名や日付情報を指定した結果、これらの語句に合わせて自然な見出しが生成できています。このような語句は忠実性が求められるため、確実に含めることができるのは実応用上有用だといえます。しかし、DOGは両方向同時に生成するため、「泳ぐ」を指定した生成例のように指定語句の前後どちらにも出現しうる単語を両方向共に生成させてしまったり、「展示」を指定した生成例のように両方向とも早い段階で生成を止めるものが確認され、課題が残っています(現在では、このような生成がほとんど起こらないモデルに改良できています)。

もう少し詳しく知りたい方は、こちらの予稿を見ていただけると嬉しいです。また、この研究はありがたいことにサイバーエージェント賞と委員特別賞をいただくことができました!その受賞理由も載せておきます!
- サイバーエージェント賞
弊社においても広告文生成を行っているプロダクトがあり, 実務環境においても特定のキーワードを含んだ文生成が非常に課題になります.
今回の提案手法では, 既存の手法であるTransformerをうまく改良し, 指定の語句を中心に前後方向に文生成をするといった方法をとっており, まさにコロンブスの卵的発想でした.
また, 特定のキーワードを確実に含めた上でRougeが先行研究と比べて遜色ない点も受賞の理由となります.
- 委員特別賞
【有用性】の観点での評価
おわりに
朝日新聞社メディア研究開発センターで取り組んだリサーチインターンシップについて書かせていただきました。インターンへの参加は勢いでしたのもあり、序盤は苦戦してかなり焦っていましたが、粘り続けることで最終的に良い研究成果を出すことができました。本当に挑戦してよかったと思っています。この記事を読んで、リサーチインターンに挑戦してみよう、朝日新聞社での自然言語処理に関する研究開発に取り組んでみたいと考えてくださる方がいたら嬉しいです。最後までお読みいただき、ありがとうございました!
追記(2021/8/26):EMNLP2021にて採択
上記の論文は、自然言語処理のトップカンファレンスのひとつであるEMNLP 2021にて採択されました。
(英文タイトル)
Transformer-based Lexically Constrained Headline Generation
(メディア研究開発センター・山田康輔)