DALL-E 3もどきの作り方

みなさんはChatGPTを使いますか?
ChatGPT、特にChatGPT 4は主に返答する文章を生成してくれる機能がありますが、最近では場合に応じて画像を生成してくれるようになりました。その画像を生成してくれる機能はDALL-E 3と呼ばれる画像生成AIによって実現されています。ChatGPTのDALL-E 3は入力した文章を具体化してくれて、画像を生成してくれる機能があるため、非常に便利です。ただし、DALL-E 3の中身は秘密となっています。
そこで今回はDALL-E 3の中身を予想して再現したDALL-E 3もどきの作り方を説明します。ちなみに無料のデモを以下の通りに貼ります。マルチモーダル生成AIの参考にしていただければ幸いです。なお、本記事は生成AIアドベントカレンダー5日目の記事となります。
DALL-E 3のおさらい
そもそもDALL-E 3とはどのような特徴をもっていて、どんな構造になっているかを確認してみましょう
再現のための特徴整理
ChatGPTのDALL-E 3は他の画像生成と違い、以下の特徴を持っています。
入力したプロンプトを具体化して、詳細なプロンプトにする
詳細なプロンプトは英語にしなければならない
詳細なプロンプトに従うように画像を生成する
ChatGPTのDALL-E 3では入力したプロンプトをGPT-4を使い具体化して、詳細なプロンプトにしていると技術報告で明言されています。そのため、GPT-4のようなLLMが別途必要となります。
DALL-E 3自体は基本的に英語のプロンプトしか受け付けないため、入力プロンプトを具体化する際に英語に翻訳する必要があります。
詳細なプロンプトに従うように画像を生成するには、画像生成に使うテキストエンコーダーの質を上げたり、学習用のテキストを詳細にする必要があります。
想像できるDALL-E 3のアーキテクチャとその挙動
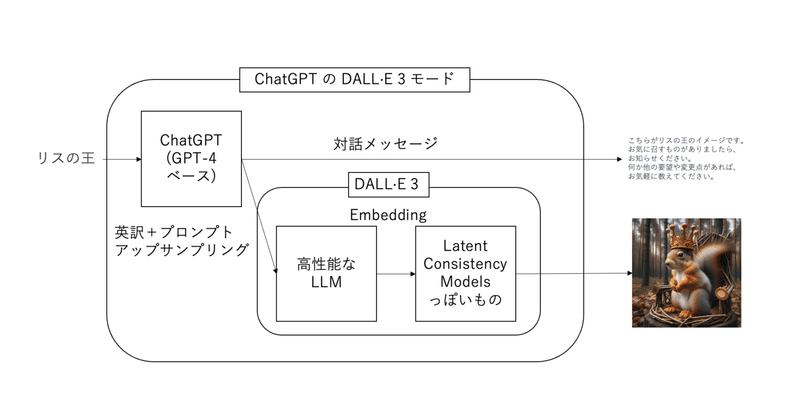
以上の特徴を持つアーキテクチャを想像すると下図のようになります。
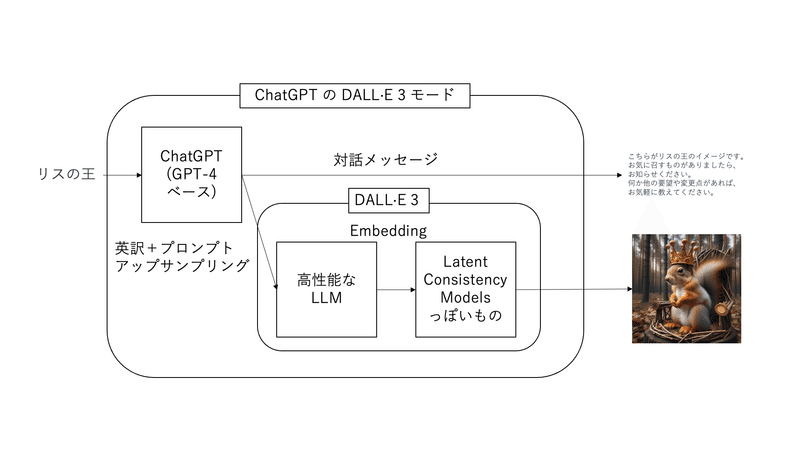
上の図は、「リスの王」というプロンプトを入力から、具体的なリスの王の画像を生成しながら、返答する文章を生成するシステムの概要図になります。この図を見ながらChatGPTのDALL-E 3の挙動を予想してみます。まず、入力したプロンプトはChatGPTのシステムプロンプトにより具体化されます。(このシステムプロンプトはそこらへんに転がっているので、頑張って探してください。)これを私はプロンプトアップサンプリングと呼んでいます。また、同時に英語に翻訳する必要があるため、これもChatGPTで変換します。その後、この英訳+アップサンプリングしたプロンプトをDALL-E 3に入力します。アップサンプリングされたプロンプトを複雑であるため、これをきれいなEmbeddingにするために、高性能なLLMを用いていると考えられます。Embeddingにされたプロンプトから画像を生成するには高解像度かつ高速な画像生成アルゴリズムであるLatent Consistency Modelsっぽいなにかを使っていると予想されます。最後に生成された画像と返答を返して処理は終了となります。
DALL-E 3を再現する方法
これまで説明したようにDALL-E 3は普通の画像生成AIに比べて複雑な構造をしています。しかし、意外とこれを代替する方法は簡単です。ここではこれまでに説明したDALL-E 3の特徴を保持したシステムを提案し、説明します。
DALL-E 3を代替するアーキテクチャ
DALL-E 3を代替するアーキテクチャは次のとおりとなります。
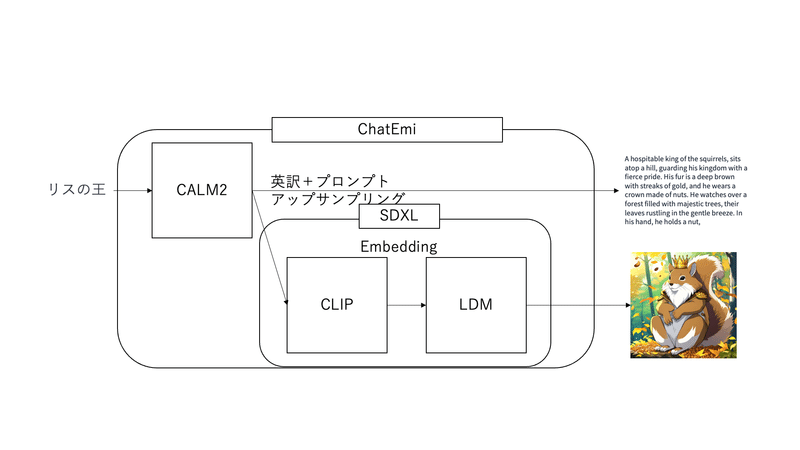
上の図は、先程と同じように「リスの王」というプロンプトを入力から、具体的なリスの王の画像を生成しながら、返答する文章を生成するシステムの概要図になります。この図をもとにDALL-E 3もどきの挙動を説明します。まず、「リスの王」というプロンプトを入力します。入力されたプロンプトは国産LLM、CALM2のシステムプロンプトによりアップサンプリングされます。このとき、システムプロンプトはHugging Faceの人が再現実装したものを使います。また、同時に英語に翻訳する必要があるため、これもCALM2で変換します。その後、この英訳+アップサンプリングしたプロンプトをSDXLに入力します。アップサンプリングされたプロンプトを、性能が良くないCLIP Text EncoderでEmbedding にします。ここは若干妥協します。できれば、T5を用いると良いでしょう。Embeddingにされたプロンプトは高解像度な画像生成アルゴリズムであるLDMを使って生成しています。最後に生成された画像と返答を返して処理は終了となります。なお、出力がアニメっぽいのはSDXLをファインチューニングしてアニメっぽいものしか出ないようにしているためです。
DALL-E 3もどきを使ってみる
さて、実際にDALL-E 3もどきであるChatEmiをつかってみましょう。以下のリンクから試すことができます
このサイトで実際に「リスの王」を入力して試すとこんな感じになります。
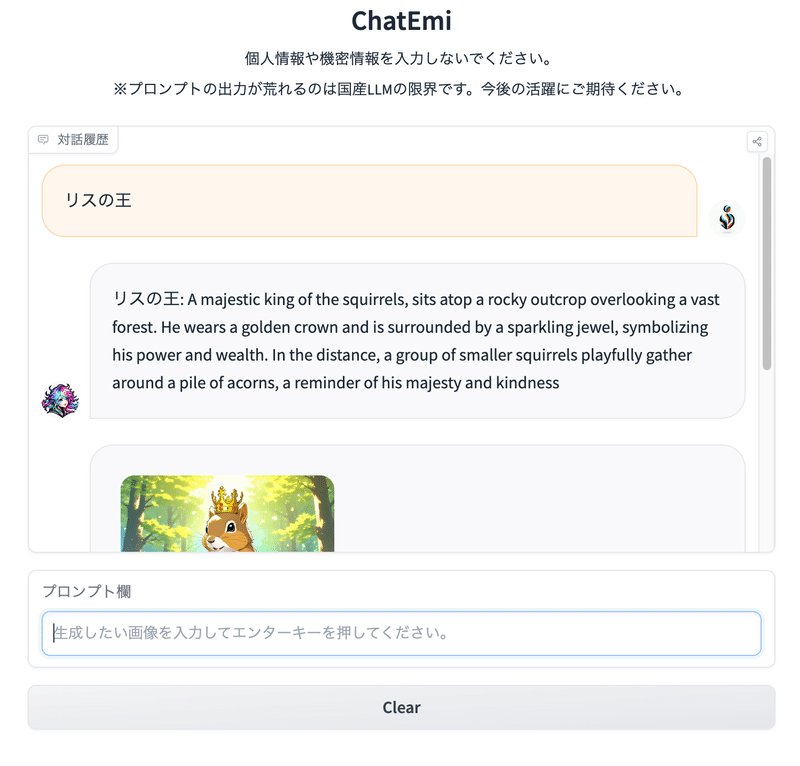


というように確かに対話で画像が生成できることがわかりました。それでは、DALL-E 3と同じように内容を変更することができるのでしょうか。リスの王を「黒い髪の女王」に変えてみます。



確かに変更することができました。ね、簡単でしょ。
まとめ
今回はDALL-E 3を紹介し、その再現実装方法を紹介しました。他の人もぜひ再現実装してサービスに組み込んでください。
この記事が気に入ったらサポートをしてみませんか?