最尤推定

母数を入力とする尤度関数をたてる。
尤度関数の対数をとって単調増加関数である対数尤度関数をつくる。
対数尤度関数を微分してゼロであれば尤度関数は最大値を成す。
その方程式を解くと最ももっともらしい母数(パラメータ)が得られる。
この辺の知識が必要です。
この記事の欠けている部分は、季節が過ぎるごとに追加される可能性があります。
不確定な情報も、もっともらしく断定口調で記述している場合があります。
指数
$$
\sqrt[n]{a}=a^{\frac{1}{n}}\\
\sqrt{a}=a^{\frac{1}{2}}\\
a^{-1}=\frac{1}{a}
$$
対数
$${a>0かつa\neq1}$$の時(底の条件)
かつ$${p>0}$$の時(真数条件)
$$
x=a^p
$$
に対して
$$
p=log_a x
$$
すなわちaをp乗するとx
aを底
xを真数
a=10の時、常用対数
a=e(ネイピア数)の時、自然対数
$$
\log_a xy = \log_a x+\log_a y\\
\log_ax^p=p\log_ax\\
\log_aa=1,\log_a1=0
$$
また
$$
\ln=\log_e
$$
であって
$$
\frac{d}{dx}\ln x=\frac{1}{x}
$$
また、合成関数の微分から
$$
\frac{d}{dx}\ln f(x)=\frac{f'(x)}{f(x)}
$$
これは
$$
\frac{dy}{dx}=\frac{dy}{du}\frac{du}{dx}
$$
から
$$
y=\ln f(x)\\
u=f(x)\\
$$
$${\ln u}$$を$${u}$$で微分するとは$${\ln f(x)}$$を$${f(x)}$$で微分することであって$${\frac{dy}{du}=\frac{1}{f(x)}}$$
$${u}$$を$${x}$$で微分するとは$${\frac{du}{dx}=f'(x)}$$
初等組み合わせ
n個の石から1つを選ぶ(選んだ石は戻す)ということをm回繰り返すと、石の並べ順の総パターン数はnのm乗
$$
n^m
$$
n個の石から1個ずつ取り出して並べていくと、石の並べ順の総パターン数はnの階乗
$$
n!=n×(n-1)×(n-2)×…×2×1
$$
また、$${0!=1}$$
順列
n個の石からk個選んで並べると、あるいは
n個の石から1個ずつ取り出して並べていくことをk回繰り返すと、石の並べ順は
$$
_nP_k=\frac{n!}{(n-k)!}=n(n-1)(n-2)…(n-k+1)
$$
また、$${nP_0=\frac{n!}{(n-0)!}=\frac{n!}{n!}=1}$$
石の並べ順を問わない場合、
取り出した石の組み合わせのみに着目する場合は組み合わせ、あるいは二項係数
組み合わせ、二項係数
$$
\begin{pmatrix} n \\k \\ \end{pmatrix}={}_n C_k = \frac{n!}{k!(n-k)!}
$$
また
$$
\begin{pmatrix} n \\k \\ \end{pmatrix}=\frac{n(n-1)(n-2)…(n-(k-1))}{k(k-1)(k-2)…1}=\frac{n(n-1)(n-2)…(n-(k-1))}{k!}
$$
母数(パラメータ)
パラメータとはすなわち関数を特徴づける値、関数を修飾、装飾する数値であり、最も素直に確率分布を用いる時は定数として固定して用いられるものである。パラメータが固定された場合、その確率分布は普通のその辺のf(x)なりf(x,y)なりとして扱うことができる。
例えばベルヌーイ分布$${Bern(X=x|\mu)=\mu^x(1-\mu)^{1-x}}$$における母数は$${\mu}$$。ガウス分布の母数は平均$${\mu}$$と分散$${\sigma^2}$$である。
普通、関数の形を見たい場合はf(x)なりf(x,y)の形を見たいのであって、そこにわざわざパラメータのための軸をとりたくはないわけである。とりわけガウシアンなどもパラメータをもち、かつ1変数もあれば2変数もあるが、基本的に扱う人はf(x)やらf(x,y)やらがおりなす釣り鐘型が見たいのであって、教科書でもなんでもガウシアンを図で描く時はパラメータなんとかの元でのf(x)やf(x,y)が描写される。
もちろんパラメータを軸に取りたければとって悪いことはなく、また、プログラム的には全部引数である。例えば$${Bern(x;\mu)}$$は
double Bern(int x, double mu)
{
return pow(mu,x)*pow((1-mu),1-x);
}
double pow(double x, int n)
{
double ret = 1;
for(int i = 0; i<n; i++)
{
ret*=x;
}
return ret;
}ただし上記の例はx{0,1}以外は考慮せず、powは探せばどっかにあるやろ的な累乗関数。
ベルヌーイ分布の$${\mu}$$の手前のバーティカルバーは条件付き確率を示す。条件付き確率として読む場合はパラメータ$${\mu}$$の元で確率変数Xがx{0,1}をとる確率は$${Bern(X=x|\mu)}$$と読む。すなわちこの時のパラメータ$${\mu}$$は確率変数である。これはベイズ推定の文脈で用いられる。
$${Bern(x;\mu)}$$などと表記される場合もある。こちらは最優推定の文脈。最尤推定の文脈では母数を未知の定数とみなし、この母数を推定していくことを目的とする。
後述するが、ある確率分布を母数の関数とみなすなら、つまり母数を定数ではなく変数、すなわち独立変数とみなすなら、それは尤度関数となる。尤度関数は$${f(\mu)}$$である。
尤度(ゆうど)
尤度関数
$$
L(\theta)=f(x_1,x_2,…,x_n|\theta)=f(\mathbf x|\theta)=\prod\limits_{i=1}^nf(x_i|\theta)\\
=f(x_1|\theta)f(x_2|\theta)…f(x_n|\theta)
$$
ただし
$${\theta=(\theta_1, \theta_2,…, \theta_n)}$$
$${\mathbf x = (x_1, x_2,…, x_n)}$$
パラメータ$${\theta}$$のもとでの観測データ$${\mathbf x}$$などと読む。
関数$${f(\mathbf x|\theta)}$$において、
パラメータ$${\theta}$$を固定した状態で
関数$${f(\mathbf x|\theta)}$$が出力$${\mathbf x = (x_1, x_2,…, x_n)}$$を吐いたと仮定する、
すなわち観測されたデータ$${\mathbf x = (x_1, x_2,…, x_n)}$$は関数$${f(\mathbf x|\theta)}$$に生み出されたものとする。
その場合尤度関数はIID(Independent and identically distributed)とみなされる。
IIDとみなされると、あるパラメータ$${\theta}$$の元での出力$${\mathbf x = (x_1, x_2,…, x_n)}$$の同時確率は条件付き確率の相乗$${f(x_1|\theta)f(x_2|\theta)…f(x_n|\theta)}$$となる。
これは条件付き独立ともとれる。
IID(独立同一分布)
同じ確率分布によって得られた異なる結果。
同じ確率分布、とは。母数(パラメータ)まで同じである確率分布。
結果同士は独立している。互いに影響していない。
往々にしてIIDは仮定であって、そうだったら計算楽だなの精神で適用される。
対数尤度関数
対数をとることで単調増加関数にする。
$$
log L(\theta)=\sum\limits_{i=1}^nlog f(x_i|\theta)
$$
最尤推定
尤度を最大化するパラメータを最尤推定量とする。
最大値を取得するために両辺微分して=0をとる。
$$
\frac{\partial}{\partial \theta}log L(\theta)=\frac{\partial}{\partial \theta}\sum\limits_{i=1}^nlog f(x_i|\theta)=0
$$
具体例
コインを放り投げた時の表裏が確率変数$${x\in\lbrace 0,1 \rbrace}$$に紐づいてベルヌーイ分布$${Bern(X=x|\mu)=\mu^x(1-\mu)^{1-x}}$$に従う時、
試行の結果、コインの裏表$${D=\lbrace x_1,x_2…x_N\rbrace}$$が観測されたならば、ベルヌーイ分布の相乗は尤度関数
$$
p(D|\mu)=\prod\limits_{i=1}^Np(x_i|\mu)=\prod\limits_{i=1}^N \mu^{x_i}(1-\mu)^{1-x_i}
$$
をなす。
ガウス分布
$$
N(x|\mu,\sigma^2)=\frac{1}{\sqrt{2\pi\sigma^2}}\exp\lbrace-\frac{1}{2\sigma^2}(x-\mu)^2\rbrace
$$
の場合、
尤度関数はその総乗
$$
p(D|\mu,\sigma^2)=\prod\limits_{i=1}^Np(x_i|\mu,\sigma^2)=\prod\limits_{i=1}^N \frac{1}{\sqrt{2\pi\sigma^2}}\exp\lbrace-\frac{1}{2\sigma^2}(x_i-\mu)^2\rbrace
$$
また、尤度関数は一般に確率分布の相乗
$$
L(\theta)=\prod \limits_{i=1}^n p(x_i;\theta)=p(x_1;\theta)p(x_2;\theta)…p(x_n;\theta)
$$
のように表される。母数が増えると尤度関数は
$$
L(\theta_1,\theta_2)
$$
のように多変数関数となる。
尤度関数は結局各々の試行が別の試行に影響を与えない、独立していることを示していて、それは例えばコイントスの結果を並べたものであり、あるいは白黒2値のドットが並んだ画像であるともいえる。
この尤度関数を最大化するのが最尤推定。これは最小二乗法の文脈における誤差関数の最小化の逆のやりかた。
また、両辺共に正なら両辺共に対数をとることができて、底が1より大なら対数は単調増加関数となるため、微分して0ならば最大値を示す。ゆえに対数をとる手法は尤度関数を最大化する際にはよく用いられる。この対数尤度関数の微分0をとるやつを尤度方程式という。
また、相乗の対数をとると対数の総和になる。
ベルヌーイ分布の対数尤度関数は、相乗関数である尤度関数の対数をとることにより各項の対数の総和になって
$$
\ln p(D|\mu)=\sum\limits_{i=1}^N \ln p(x_i|\mu)=\sum\limits_{i=1}^N \lbrace x_i \ln \mu+(1-x_i)\ln(1-\mu) \rbrace
$$
尤度方程式は対数尤度関数の微分がゼロ。
$$
\frac{d}{d\mu}\ln p(D|\mu)=\frac{d}{d\mu}\sum\limits_{i=1}^N \ln p(x_i|\mu)=\frac{d}{d\mu}\sum\limits_{i=1}^N \lbrace x_i \ln \mu+(1-x_i)\ln(1-\mu) \rbrace=0
$$
これを解くと
$$
\sum\limits_{i=1}^N \lbrace x_i \frac{d}{d\mu}\ln \mu+(1-x_i)\frac{d}{d\mu}\ln(1-\mu) \rbrace=\sum\limits_{i=1}^N \lbrace \frac{x_i}{\mu}-\frac{(1-x_i)}{(1-\mu)} \rbrace=0
$$
$$
\sum\limits_{i=1}^N \frac{x_i}{\mu}=\sum\limits_{i=1}^N\frac{(1-x_i)}{(1-\mu)}
$$
$$
(1-\mu)\sum\limits_{i=1}^N x_i=\mu\sum\limits_{i=1}^N(1-x_i)\\
\sum\limits_{i=1}^N x_i-\mu\sum\limits_{i=1}^N x_i=\mu\sum\limits_{i=1}^N(1-x_i)\\
\sum\limits_{i=1}^N x_i=\mu\sum\limits_{i=1}^N(1-x_i)+\mu\sum\limits_{i=1}^N x_i\\
\sum\limits_{i=1}^N x_i=\mu\lbrace\sum\limits_{i=1}^N(1-x_i)+\sum\limits_{i=1}^N x_i\rbrace\\
\sum\limits_{i=1}^N x_i=\mu\lbrace\sum\limits_{i=1}^N1-\sum\limits_{i=1}^Nx_i+\sum\limits_{i=1}^N x_i\rbrace\\
\sum\limits_{i=1}^N x_i=\mu\lbrace\sum\limits_{i=1}^N1\rbrace\\
\sum\limits_{i=1}^N x_i=\mu N\\
$$
$$
\frac{1}{N}\sum\limits_{i=1}^N x_i=\mu
$$
これは結局、出目に対する普通の平均、相加平均、算術平均に過ぎない。統計の文脈ではサンプル平均とか標本平均とかいう。
ベルヌーイ試行においてはxは0と1しか取らないから、普通にコインをほってったら表が出る確率$${\mu}$$は1/2らへんになりそうではあるし、コインがインチキされてたり歪んでたりしたら$${\mu}$$は0なり1なりに向かって偏るであろう。
ガウス分布の対数尤度関数は、またしても相乗である尤度関数の対数をとることにより対数の総和に変換されて
$$
\ln p(D|\mu,\sigma^2)=\sum\limits_{i=1}^N \ln p(x_i|\mu,\sigma^2)=\sum\limits_{i=1}^N \lbrace \ln \lbrace\frac{1}{\sqrt{2\pi\sigma^2}}\exp\lbrace-\frac{1}{2\sigma^2}(x_i-\mu)^2\rbrace\rbrace \rbrace
$$
$$
\sum\limits_{i=1}^N \lbrace \ln \frac{1}{\sqrt{2\pi\sigma^2}}+\ln\exp\lbrace-\frac{1}{2\sigma^2}(x_i-\mu)^2\rbrace \rbrace\\
\sum\limits_{i=1}^N \lbrace \ln (2\pi\sigma^2)^{-\frac{1}{2}}+\ln e^{-\frac{1}{2\sigma^2}(x_i-\mu)^2}\rbrace
$$
$${\ln e=\log_e e=1}$$であるから
$$
\sum\limits_{i=1}^N \lbrace -\frac{1}{2}\ln (2\pi\sigma^2)-\frac{1}{2\sigma^2}(x_i-\mu)^2\rbrace
$$
インデックス持ってない変数、ここでは$${x_i}$$を含まない項の総和は
$${\sum\limits_{i=1}^{N}1=N}$$
よって
$$
-\frac{N}{2}\ln (2\pi\sigma^2)-\frac{1}{2\sigma^2}\sum\limits_{i=1}^N (x_i-\mu)^2
$$
尤度方程式はこれを微分したら0。ガウス分布はパラメータが2つあるから偏微分で一個ずつしめてくと
$$
\frac{\partial}{\partial \mu}\lbrace-\frac{N}{2}\ln (2\pi\sigma^2)+-\frac{1}{2\sigma^2}\sum\limits_{i=1}^N (x_i-\mu)^2 \rbrace
$$
$${ (x_i-\mu)^2}$$は合成関数の微分$${\frac{dy}{dx}=\frac{dy}{du}\frac{du}{dx}}$$を用いて
$${y=u^2}$$かつ$${u=x_i-\mu}$$とおくと
$${\frac{dy}{du}=2u}$$かつ$${\frac{du}{d\mu}=-1}$$であるからして
$${\frac{\partial}{\partial \mu} (x_i-\mu)^2=2(x_i-\mu)(-1)}$$
$$
\frac{\partial}{\partial \mu} \ln p(D|\mu,\sigma^2)=-\frac{1}{2\sigma^2}\sum\limits_{i=1}^N \frac{\partial}{\partial \mu}(x_i-\mu)^2 =-\frac{1}{2\sigma^2}\sum\limits_{i=1}^N 2(x_i-\mu)(-1) =\frac{1}{\sigma^2}\sum\limits_{i=1}^N (x_i-\mu)=0
$$
$$
\frac{1}{\sigma^2}\sum\limits_{i=1}^N (x_i-\mu)=0\\
\sum\limits_{i=1}^N (x_i-\mu)=0\\
\sum\limits_{i=1}^N x_i-\sum\limits_{i=1}^N\mu=0\\
\sum\limits_{i=1}^N x_i=N\mu
$$
よって
$$
\frac{1}{N}\sum\limits_{i=1}^N x_i=\mu
$$
これはベルヌーイ分布のやつと同じ。
また、もろもろはぶくと分散の最尤推定は
$$
\frac{1}{N}\sum\limits_{i=1}^{N}(x_i-\mu)^2=\sigma^2
$$
ただしここでの$${\mu}$$は先に求めた最ももっともらしかった$${\mu}$$を用いる。
ここで求まった最ももっともらしい$${\mu}$$と$${\sigma^2}$$は、最ももっともらしい(maximum likelihood)パラメータであるため、$${\mu_{ML}}$$やら$${\sigma_{ML}^2}$$などと表す。
ベイズ推定の文脈
尤度関数はベイズの定理でいうところの右辺の左上。

$$
P(\mu|D) = \frac{P(D|\mu)P(\mu)}{P(D)}
$$
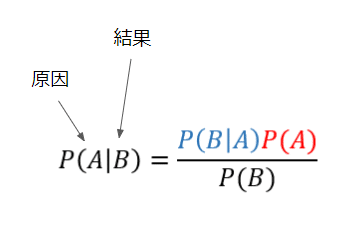
確率P(A)がP(A|B)に変化する。
ベルヌーイ分布:Bern(x;mu)
確率変数Xが二値(例えば0と1)をとり
$$
x\in\lbrace0,1\rbrace
$$
かつその出力の出現確率が偏る(かもしれない)場合。
例えば7割がた表がでるコインなど。
この場合
確率変数X=1(コイン表)となる確率p(X=1)は0.7
確率変数X=0(コイン裏)となる確率p(X=0)は0.3
確率変数X=1なる方をパラメータ$${\mu}$$で表すと
確率変数X=0なる方は$${(\mu-1)}$$
偏りのある(かもしれない)コインの確率分布は
$$
Bern(X=x|\mu)=\mu^x(1-\mu)^{1-x}
$$
xには0か1しか入らないため、項は0乗か1乗かみたいな感じになる。
また、二項分布のn=1の場合である。
期待値
$$
E[x]=\mu
$$
分散
$$
V[x]=\mu(1-\mu)
$$
尤度関数(相乗)
$$
p(D|\mu)=\prod\limits_{i=1}^Np(x_i|\mu)=\prod\limits_{i=1}^N \mu^{x_i}(1-\mu)^{1-x_i}
$$
対数尤度関数(尤度関数(相乗)の対数は総和)
$$
\ln p(D|\mu)=\sum\limits_{i=1}^N \ln p(x_i|\mu)=\sum\limits_{i=1}^N \lbrace x_i \ln \mu+(1-x_i)\ln(1-\mu) \rbrace
$$
尤度方程式(対数尤度関数の微分=0)
$$
\frac{d}{d\mu}\ln p(D|\mu)=\frac{d}{d\mu}\sum\limits_{i=1}^N \ln p(x_i|\mu)=\frac{d}{d\mu}\sum\limits_{i=1}^N \lbrace x_i \ln \mu+(1-x_i)\ln(1-\mu) \rbrace=0
$$
解くと
$$
\sum\limits_{i=1}^N \lbrace x_i \frac{d}{d\mu}\ln \mu+(1-x_i)\frac{d}{d\mu}\ln(1-\mu) \rbrace=\sum\limits_{i=1}^N \lbrace \frac{x_i}{\mu}-\frac{(1-x_i)}{(1-\mu)} \rbrace=0
$$
$$
\sum\limits_{i=1}^N \frac{x_i}{\mu}=\sum\limits_{i=1}^N\frac{(1-x_i)}{(1-\mu)}
$$
$$
(1-\mu)\sum\limits_{i=1}^N x_i=\mu\sum\limits_{i=1}^N(1-x_i)\\
\sum\limits_{i=1}^N x_i-\mu\sum\limits_{i=1}^N x_i=\mu\sum\limits_{i=1}^N(1-x_i)\\
\sum\limits_{i=1}^N x_i=\mu\sum\limits_{i=1}^N(1-x_i)+\mu\sum\limits_{i=1}^N x_i\\
\sum\limits_{i=1}^N x_i=\mu\lbrace\sum\limits_{i=1}^N(1-x_i)+\sum\limits_{i=1}^N x_i\rbrace\\
\sum\limits_{i=1}^N x_i=\mu\lbrace\sum\limits_{i=1}^N1-\sum\limits_{i=1}^Nx_i+\sum\limits_{i=1}^N x_i\rbrace\\
\sum\limits_{i=1}^N x_i=\mu\lbrace\sum\limits_{i=1}^N1\rbrace\\
\sum\limits_{i=1}^N x_i=\mu N\\
$$
$$
\frac{1}{N}\sum\limits_{i=1}^N x_i=\mu
$$
二項分布:Bin(x;n,mu)
事象が起こる確率を$${\mu}$$
n回の試行のうち、試行の結果、事象がx回起こる確率は
$$
Bin(X=x|n,\mu)={}_nC_x\mu^x(1-\mu)^{n-x}
$$
ここで確率変数Xは離散値をとる。ゆえにPは確率質量関数。確率質量関数は確率変数が離散値をとる確率分布。確率変数は現実の様々な事象(数式的に操作不可)と数字(数式的に操作可能)を結びつける関数。つまり確率変数は数式的にはただのなんかの数。確率分布は確率変数を入力とし、確率(0-1の実数)を出力とする関数。
二項分布は試行毎に試行の成功確率、事象の発生確率が変わらない事象に用いられる。また、ここで発生する事象は「成功」か「失敗」の二択である。
また、試行回数n=1ならば$${x\in\lbrace0,1\rbrace}$$において$${{}_1C_0}$$も$${{}_1C_1}$$も1であるため、ベルヌーイ分布と化す。
また、二項分布は離散確率分布であるが、試行回数nを無限にすっとばせば連続確率分布である正規分布で近似できる。
期待値
$$
E[x]=n\mu
$$
分散
$$
V[x]=n\mu(1-\mu)
$$
ガウス分布:Norm(x;mu,sigma^2)
$$
Norm(x|\mu,\sigma^2)=\frac{1}{\sqrt{2\pi\sigma^2}}\exp\lbrace-\frac{1}{2\sigma^2}(x-\mu)^2\rbrace
$$
尤度関数
$$
p(D|\mu,\sigma^2)=\prod\limits_{i=1}^Np(x_i|\mu,\sigma^2)=\prod\limits_{i=1}^N \frac{1}{\sqrt{2\pi\sigma^2}}\exp\lbrace-\frac{1}{2\sigma^2}(x_i-\mu)^2\rbrace
$$
対数尤度関数
$$
\ln p(D|\mu,\sigma^2)=\sum\limits_{i=1}^N \ln p(x_i|\mu,\sigma^2)=-\frac{N}{2}\ln (2\pi\sigma^2)-\frac{1}{2\sigma^2}\sum\limits_{i=1}^N (x_i-\mu)^2
$$
尤度方程式
$${\mu}$$に関して
$$
\frac{\partial}{\partial \mu}\ln p(D|\mu,\sigma^2)=\frac{\partial}{\partial \mu}\sum\limits_{i=1}^N \ln p(x_i|\mu,\sigma^2)=0
$$
解くと
$$
\frac{1}{N}\sum\limits_{i=1}^N x_i=\mu
$$
$${\sigma^2}$$に関して
$$
\frac{\partial}{\partial \sigma^2}\ln p(D|\mu,\sigma^2)=\frac{\partial}{\partial \sigma^2}\sum\limits_{i=1}^N \ln p(x_i|\mu,\sigma^2)=0
$$
解くと
$$
\frac{1}{N}\sum\limits_{i=1}^{N}(x_i-\mu)^2=\sigma^2
$$
この記事が気に入ったらサポートをしてみませんか?