
初学者によるHyperNetwork学習メモ

⚠タイトル通り初学者によるメモ感覚のものです、色々間違ってたりします
SDの導入までは準備出来てるものとします。
まず準備するもの
8GB以上のVRAMがあるグラフィックボードもしくはColab環境
キャラ学習するなら元になるキャラ絵(最低20枚~最高50枚くらい)
脱がせたり着せ替えたりするなら2割くらいヌードや別差分欲しい絵柄学習するなら似た絵柄の元絵(最低25枚くらい欲しいかも)
(左右反転させるので実質50枚です)
キャラ学習
元になる画像サイズは512×512である必要はありません。というか個人的には全身写ってる縦長絵のほうが体感成功します。
ただ512×512で顔と服に分けて学習させたほうが汎用性は上がります。
(縦長絵のみで学習させると横長画像に対応しなかったり)
またキャラ学習の際に集める画像はキャラの特徴がわかりやすいものにしましょう。
後述しているナンジャモで言えば頭のコイルが途切れてるものなどはあまり使用しないほうが良いです。
絵柄学習
こちらも512×512である必要はありませんが描かれているキャラの顔が明確に認識出来る画像が好ましいです。
一番手っ取り早いのは良い感じの絵柄をAIくんが出してくれたときにそのままシード値固定せず50枚生成すると楽です。
導入拡張機能
HyperNetwork-MonkeyPatch-Extension
https://github.com/aria1th/Hypernetwork-MonkeyPatch-Extensionstable-diffusion-webui-wd14-tagger
https://github.com/toriato/stable-diffusion-webui-wd14-tagger
学習画像の準備・処理
左右反転させても問題ない左右対称キャラクターや絵柄学習のみ使用
学習の画像の前処理の反転画像を生成するに☑
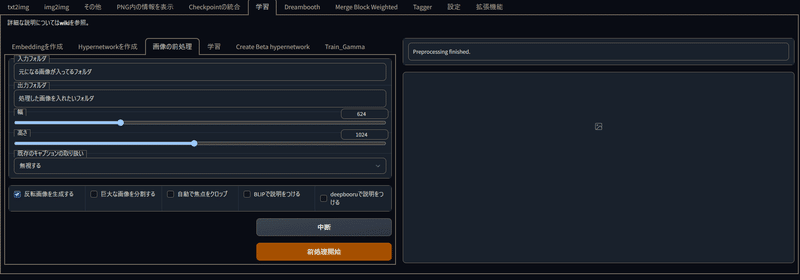
幅、高さは処理したときに出てくる画像の大きさになります。
出したい画像サイズに調節してください。
縦画像と横画像が混ざってるけど左右反転したい場合は
巨大な画像を分割する・自動で焦点をクロップに☑
もしくは縦画像と横画像でフォルダを一度分けておいて二回に分けて出力してください。
タグ付け
ここでは先程のstable-diffusion-webui-wd14-taggerを使います。

拡張機能欄のURLからインストールに先程のURLをコピペしてインストール
(HyperNetwork-MonkeyPatch-Extensionも入れてなければここでしちゃいましょう)
一度再起動したらTaggerのタブが増えてると思うのでそこを選んでください。

基本的はこの形になります。
タグを除外にbreasts, blurryを入れたほうが学習内容が良くなるという話を聞いたので脳死で入れてます。
あと服の装飾品多いとVirtual youtuberタグも入れがちなので除外していいと思います。
そしたらInterrogateを押します。

Interrogateを押すと画像の横に同ネームのテキストファイルが生成されます
画風再現の場合は全く弄らなくていいですがキャラ再現の場合は弄る必要があるため簡単に説明します。
キャラ再現のみ(タグ整理)

画像の横にあるテキストファイルを開くと画像に対応していそうなプロンプトが大量に書き込まれています。
キャラ再現の場合大体頭の部分のタグは消していいです。
表情に関するタグは残してください(:dやvは表情タグです)
multicolored hairが入るようなキャラの場合hairに関するタグが物凄いことになるので髪色関連全部消してください。

あとこういうなんか既存タグに置き換えられない変な特徴持ってるキャラ学習させたい場合も髪に関するタグは消していいです
例として出してるナンジャモの場合、頭のコイルをballoon、リボン型の髪型をribbonとしてタグ付けするので元画像をよく見ながらどれにどのタグ付けてるのか考えて消していってください。
hairやeyesのみが頭のことを指し示してるタグとは限りません。
逆に頭どうでもいいから服の特徴だけ覚えさせたいな~ってときは
服のタグを消して頭に関するタグ全部残してください。
まぁここまでつらつら書いたもののタグ全く弄らずでも再現は可能です。
消しておくと詳細なことをプロンプトに書かなくても勝手に出てくるようになるだけなので
部位ごとに呼び出すほうが良ければそのままでも可(ただし上記の通りmulticolored hairが入るようなキャラの場合は髪色に関するタグは全部消した方が良いです)
では次に行きます
HyperNetworkを作成
Hypernetwork-MonkeyPatch-Extensionが入ってれば学習タブにCreate Beta hypernetworkが出てきてると思うのでそこを選んでください。

名称:HyperNetworkの名付けですね。
わかりやすいものにしとかないと何が何だか自分でもわからなくなるのでわかりやすくしましょう。モジュール
知りませんが全部☑入れときましょうレイヤー構造
自分はキャラ学習1, 2, 1 画風再現1, 1.5, 1.5, 1としています 1, 3, 1や1, 2, 2, 1の方が良いと言われてたりしますが、8GBだとたまに容量不足で学習落ちてストレスなのでやめましょう。活性化関数
大体mishかrelu、leakyreluで良いと思います。
個人的なイメージとしてはmishは細部にもこだわる代わりに学習時間が長く学習の調整が難しいです。
relu、leakyreluは大雑把に学んでくれます、特徴捉えて早い。レイヤーウェイト
relu、leakyreluの場合Normal、mishの場合XavierUniform
mishの場合だけなんで違うのかというと先人がそれを使ってたからです。詳細は知りません。レイヤーの正規化
過学習起こしづらくなりますが学習率が低いと学習が全く進みません。
レイヤー正規化を使う場合、1e-4などある程度大きき目の学習率からはじめ
逆にレイヤー正規化を使わない場合は5e-5~6e-5など、低めの学習率を使うようにしましょう。use drop out
過学習起こしづらくなるそうです、構造が1, 2, 1の場合 0, 0.3, 0のような形で使うそうです。興味ある人は調べてください。
設定出来たらHyperNetworkを作成
Train_Gamma

HyperNetwork選択欄の横のENDを押して先程作成したHyperNetwork名を選択しましょう。
学習率は人によって好み出ますが個人的には5e-4:6000, 5e-5:9000, 5e-6:10000,でやっています。
まぁこれ見て参考にする人は多分初めてだったりこれから学ぶ人が多いと思うのでとりあえず上の学習率で行きましょう。
1回当たりの枚数:VRAM8GBの私は上げたら動かなかったので1です
Gradient蓄積ステップ:Show advanced learn rate scheduler options(for Hypernetworks)の項目と同時に使うと効率的に学習できるらしいですが8GBでは動かないも同然だったので1です。
データセットフォルダ
Taggerで選んだフォルダのパスを入力してくださいログフォルダ
作成最中のHyperNetwork状況の保存やサンプルイメージを出力するフォルダを選択してください。プロンプトのテンプレートファイル
Cドライブに入れてるなら
C:\stable-diffusion-webui\textual_inversion_templates
になんかそれっぽいのがあります。これは何かというと全画像に共通するタグを予めこちらで決めようというものです。絶対にこのタグ打てば全画像に共通するものを出してくれるみたいな感じですね。
キャラであれば中のテキストファイルにmasterpiece, best quality, 1girl, キャラ名, [filewords]
画風であれば中のテキストファイルにby alsan, [filewords]みたいにしてください。
まぁ呼び出すためのキーなだけなんで何でもいいです。
設定したらそのテキストファイルへのパスをテンプレートファイルに突っ込んでください幅、高さ
512×512以上で学習しようとすると8GB民は落ちます。不干渉最大ステップ数
最大でどれだけ学習するかですね、今回は私の設定使ってるなら10000でやりましょう。どうせ一定数ごとに学習内容の保存するので多いくらいがちょうどいいです。指定したステップ数ごとに画像を生成し、ログに保存する。
自分はいつも500です。設定した数値の倍数まで学習ステップが進むごとにログフォルダに、その時点でのHyperNetwork.ptファイルとimage画像が出力されます。保存した画像にembeddingを埋め込む
HyperNetworkには関係ないです。プレビューの作成にt2iタブから読み込んだパラメーターを使う
これは☑必須です、経過画像がわからなくなるので
ただその前に設定が必要なので設定を後述します。プロンプト作成時にタグを","区切りでシャッフルする。
これも過学習起こしづらくなる要素の1個という認識です、とりあえず☑プロンプト作成時にタグをドロップアウトする
画像を構成する要素として重要なタグをドロップアウトされて学習される場合があるので原則は0です。サンプリングメソッド
どれが何とか知りませんが使った感想で言うなら
ランダム>deterministic>onceなのかなと勝手に思ってます。
興味あるなら調べてください(初学者感)
あとは作成と言いたいところなんですがプレビューの作成にt2iタブから読み込んだパラメーターを使うに☑を入れたのでt2iの欄に移動してください。
プレビュー作成のための設定
プロンプトにテンプレートファイルで指定したプロンプト+Taggerで残した特徴で出したいやつを入力しましょう。
例として
masterpiece, best quality, 呼び出しキー, white jacket, long sleeves, animal hood, pleated skirt, hooded jacket, blue headwear, open jacket, full body
太文字部分はTaggerでタグ付けしてキャラと分離させたものを呼び出してます。
キャラ学習させるなら最後のところにfull body付けておいたほうが破綻したときわかりやすくていいと思います。
ネガティブプロンプトは普段遣いのもので良いです。
サンプリング回数とアルゴリズムはぶっちゃけ多いステップ必要なやつは時間の無駄なので
ステップ25前後でEuler aかDPM++ 2M Karrasあたりでいいです、好みで
幅と高さ 512×512 だよ、わかったねそれ以上にしてもいいけど
8GBの人は間違いなくサンプル画像出力時に学習が毎回中断されるハメになります。
CFGはお好みで、自分はいつも7.5くらいです
シード値はなんでもいいから数値で固定しろ
固定しないと学習経過が分かりづらい
ちゃんと設定出来てるか確かめるために一度生成押しておきましょう。
512×512で出力されてるか確かめようね(2敗)
あと設定タブからHyperNetworkの強度を1にして保存してください
HyperNetworkの学習を開始
小出し通りです、Train_Gammaに戻ってHyperNetworkの学習を開始してください。
この際8GBの民はVRAMを消費する作業は極力しないでください、Youtube見たり画面配信見たり付けたり。
私は大体Taggerを先に何個かのキャラにつけておいて学習中にタグ添削してるかスマホでマンガ読んでます。
デュアルモニターの人は片側に学習画面出しておけばいいですが、シングルモニターの人はコマンドプロンプトを最前面に固定しておいた方がエラー吐いたときにわかりやすくていいです。
エラー吐いたらもちろん学習はストップしてしまうので気付くのが送れるとただの時間の無駄です。
よくあるエラーの解決方法
エラーで落ちた後再学習させようとするとエラー起きる!
って場合以下の行為をすると大体直ります。直らなかったら先輩達に聞こうね。
Train_GammaのHyperNetwork横のENDで更新後に再学習
学習に伴ってハッシュタグ(後ろの数値)が変わっていて、そんなHyperNetwork存在してないよ!って言われてる可能性があります。CUDAって文字が見える時
CUDAバージョンが低いかVRAM容量不足なので下記の行為を試していきましょう。
Stable-diffusion-webuiのwebui-user.batをメモ帳(編集)で開く
set COMMANDLINE_ARGS=の後ろに--xformersを付ける
set COMMANDLINE_ARGS=--xformers
再度試す。
まだ動かなければタスクマネージャー開いてGPUを使ってるソフトが無いか確認してタスクキルもしくは再起動
再度試す。
まだ動かなければタスクマネージャーのパフォーマンスを見て専用GPUメモリが8GB以上あるか確認
あるならCUDAバージョンが低いのが多分原因なので更新してきましょう。
この際SDのブラウザ画面閉じたり更新した人はt2iの設定だけし直してね
あとTrain_Gammaの設定も初期化されてるから気をつけてね。知識ある先人にコマンドプロンプト見せて解決してもらう。
今のところよくあるエラーでこれ以外見てないので解決しなかったら他の人の力借りてください。
HyperNetworkの再現度を試す。
はい、まぁ完成したらとりあえず試してみましょう。
途中からほぼ構図が変わんなくなってたり人ですら無くなってたりすると思うので、サンプル画像的に過学習起こしてたら起こしていないステップ数のHyperNetworkをログフォルダからコピーしてC:\stable-diffusion-webui\models\hypernetworksに突っ込んでください
もし512×512以上の大きさで画像を出力したい場合
高解像度補助に☑を入れましょう。(入れなくても動くときあるけど安定性が増すので)

ノイズ除去強度はお好みで幅と高さなんですが0でも問題なく動きます。
最適な設定を求めてる場合はコチラから設定を探してください。
上2つが作りたい画像のサイズ、下2つが高解像度補助に入力する数値になります。
ここで想像通り良い感じに出力されたならGoodです。お疲れ様でした。
ですが私の設定でやった方は凄い似てるけど全く構図が変わらないとか起きてると思います、ステップ数多めで過学習気味になってるはずなので。
過学習の場合の対処法
設定欄からHyperNetworkの強度を下げる
0.05ずつくらい下げていくとどこかで良い感じに構図とか変えられる場所があるはずです。
私の設定でやってるなら最終的に出来たHyperNetworkだと0.85くらいで構図変更が出来て0.7くらいで完全に脱がせると思いますステップ数が低いHyperNetworkを持ってくる
私の設定でやった人はログフォルダに500ステップ毎のサンプル画像とHyperNetworkのptファイルがあるはずなのでサンプル画像見て良い感じのステップ数から持ってきましょう。どっちもやったけど満足行かない
HN強度1に設定し直して出力してみて面影あるけど似てないな?ってステップ数のptファイルを探して再度Train_Gammaに入れましょう。
その際学習率を落としてください、5e-6とか5e-7くらいで学習させてみよう。
HyperNetwork初学者による初学者講座-完-
まぁなんか自分が初心者だとしてこれくらいの説明あればわかるかな
って感じに書いてたら校長の話くらい長くなりました。
見出し設定してるし各自知りたい所だけ見ればそんなに長くならないとはおもうけど…。
これは追加学習の方法をまとめてるだけであって特定絵師の画風とかを再現することを推奨するものでは無いです。
また著作権物を追加学習させて作ったものでお金を稼ぐのもオススメしません。
追加学習させたものは個人のTwitter等で楽しむ範囲に留めておきましょう。
もし何か質問とか間違いがあったらTwitterのDMにでも来てください。
AI関係の方であればフォロー返してるのでよろしくお願いします。
また何かまとめることが出来たら書くと思います。
この記事が気に入ったらサポートをしてみませんか?